 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Out-of-Domain Detection for Automated Driving
Oct 23, 2023

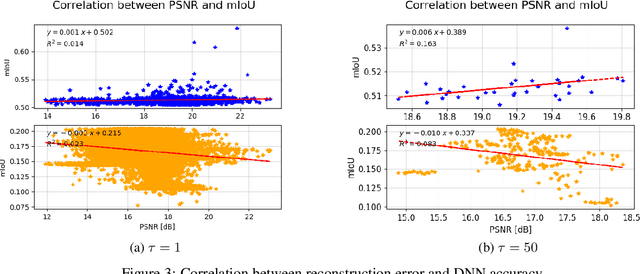
Ensuring safety in automated driving is a major challenge for the automotive industry. Special attention is paid to artificial intelligence, in particular to Deep Neural Networks (DNNs), which is considered a key technology in the realization of highly automated driving. DNNs learn from training data, which means that they only achieve good accuracy within the underlying data distribution of the training data. When leaving the training domain, a distributional shift is caused, which can lead to a drastic reduction of accuracy. In this work, we present a proof of concept for a safety mechanism that can detect the leaving of the domain online, i.e. at runtime. In our experiments with the Synthia data set we can show that a 100 % correct detection of whether the input data is inside or outside the domain is achieved. The ability to detect when the vehicle leaves the domain can be an important requirement for certification.
Improving Predictive Performance and Calibration by Weight Fusion in Semantic Segmentation
Jul 22, 2022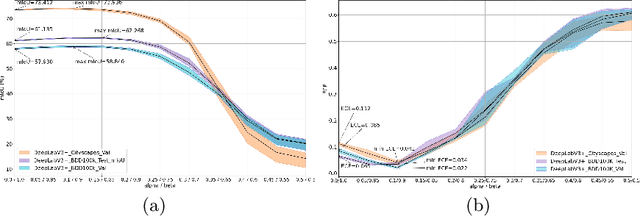

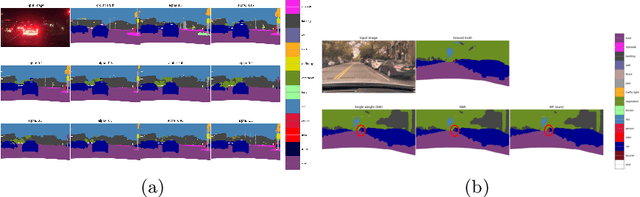
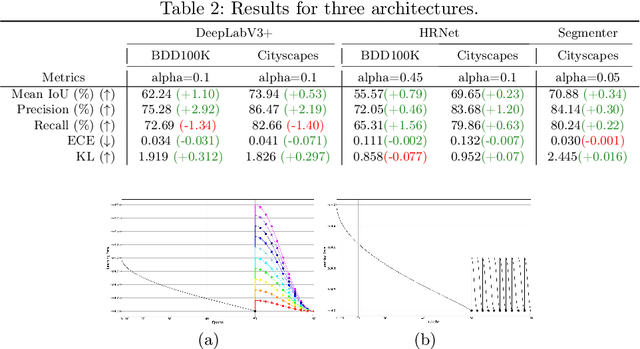
Averaging predictions of a deep ensemble of networks is apopular and effective method to improve predictive performance andcalibration in various benchmarks and Kaggle competitions. However, theruntime and training cost of deep ensembles grow linearly with the size ofthe ensemble, making them unsuitable for many applications. Averagingensemble weights instead of predictions circumvents this disadvantageduring inference and is typically applied to intermediate checkpoints ofa model to reduce training cost. Albeit effective, only few works haveimproved the understanding and the performance of weight averaging.Here, we revisit this approach and show that a simple weight fusion (WF)strategy can lead to a significantly improved predictive performance andcalibration. We describe what prerequisites the weights must meet interms of weight space, functional space and loss. Furthermore, we presenta new test method (called oracle test) to measure the functional spacebetween weights. We demonstrate the versatility of our WF strategy acrossstate of the art segmentation CNNs and Transformers as well as real worlddatasets such as BDD100K and Cityscapes. We compare WF with similarapproaches and show our superiority for in- and out-of-distribution datain terms of predictive performance and calibration.
Efficient Multi-Task RGB-D Scene Analysis for Indoor Environments
Jul 10, 2022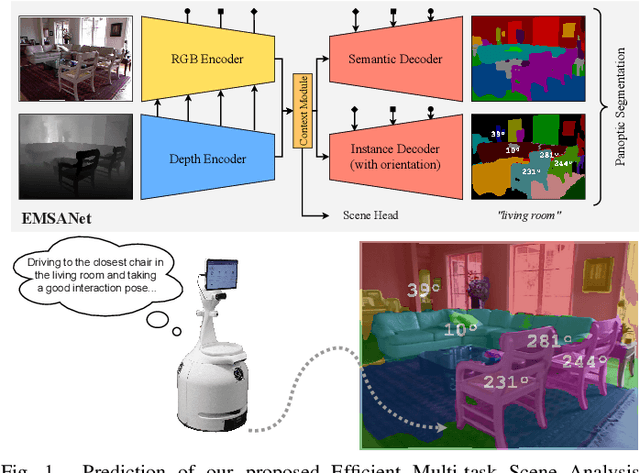


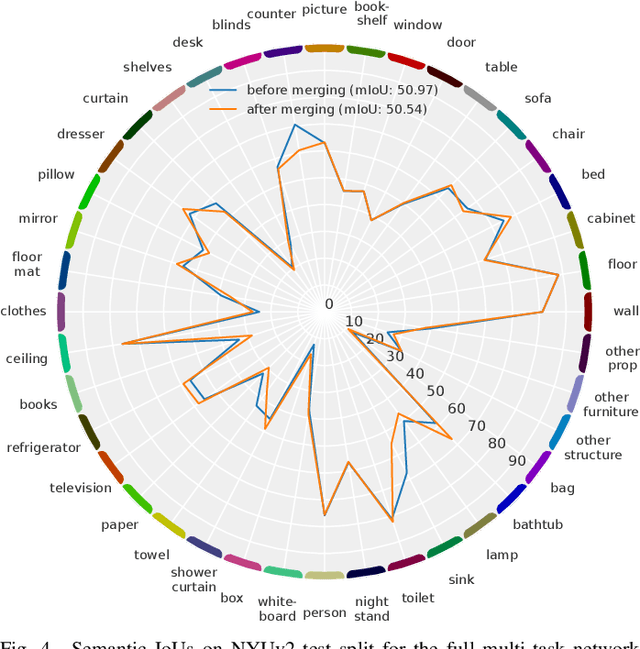
Semantic scene understanding is essential for mobile agents acting in various environments. Although semantic segmentation already provides a lot of information, details about individual objects as well as the general scene are missing but required for many real-world applications. However, solving multiple tasks separately is expensive and cannot be accomplished in real time given limited computing and battery capabilities on a mobile platform. In this paper, we propose an efficient multi-task approach for RGB-D scene analysis~(EMSANet) that simultaneously performs semantic and instance segmentation~(panoptic segmentation), instance orientation estimation, and scene classification. We show that all tasks can be accomplished using a single neural network in real time on a mobile platform without diminishing performance - by contrast, the individual tasks are able to benefit from each other. In order to evaluate our multi-task approach, we extend the annotations of the common RGB-D indoor datasets NYUv2 and SUNRGB-D for instance segmentation and orientation estimation. To the best of our knowledge, we are the first to provide results in such a comprehensive multi-task setting for indoor scene analysis on NYUv2 and SUNRGB-D.
Explaining Clinical Decision Support Systems in Medical Imaging using Cycle-Consistent Activation Maximization
Oct 13, 2020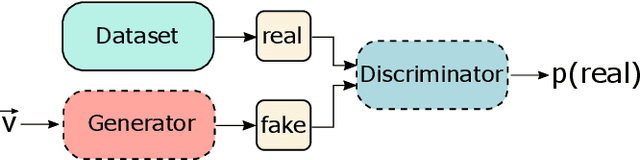
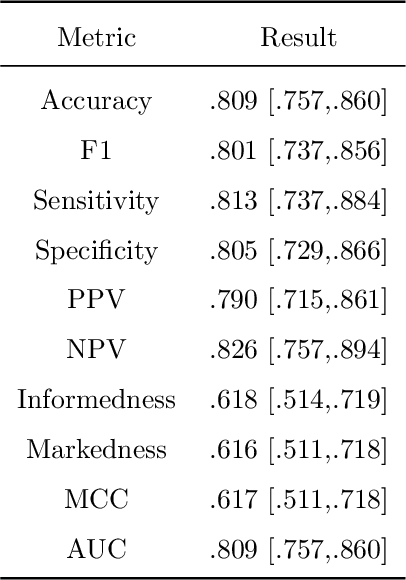
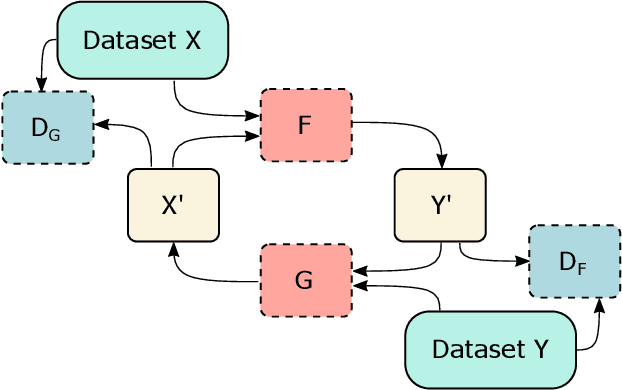
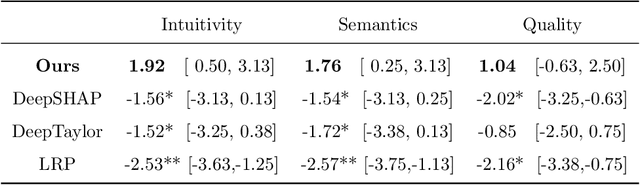
Clinical decision support using deep neural networks has become a topic of steadily growing interest. While recent work has repeatedly demonstrated that deep learning offers major advantages for medical image classification over traditional methods, clinicians are often hesitant to adopt the technology because its underlying decision-making process is considered to be intransparent and difficult to comprehend. In recent years, this has been addressed by a variety of approaches that have successfully contributed to providing deeper insight. Most notably, additive feature attribution methods are able to propagate decisions back into the input space by creating a saliency map which allows the practitioner to "see what the network sees." However, the quality of the generated maps can become poor and the images noisy if only limited data is available - a typical scenario in clinical contexts. We propose a novel decision explanation scheme based on CycleGAN activation maximization which generates high-quality visualizations of classifier decisions even in smaller data sets. We conducted a user study in which these visualizations significantly outperformed existing methods on the LIDC dataset for lung lesion malignancy classification. With our approach we make a significant contribution to a better understanding of clinical decision support systems based on deep neural networks and thus aim to foster overall clinical acceptance.