 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Prediction of Dense Visual Embeddings via Distillation and RGB-D Transformers
Jan 01, 2026In domestic environments, robots require a comprehensive understanding of their surroundings to interact effectively and intuitively with untrained humans. In this paper, we propose DVEFormer - an efficient RGB-D Transformer-based approach that predicts dense text-aligned visual embeddings (DVE) via knowledge distillation. Instead of directly performing classical semantic segmentation with fixed predefined classes, our method uses teacher embeddings from Alpha-CLIP to guide our efficient student model DVEFormer in learning fine-grained pixel-wise embeddings. While this approach still enables classical semantic segmentation, e.g., via linear probing, it further enables flexible text-based querying and other applications, such as creating comprehensive 3D maps. Evaluations on common indoor datasets demonstrate that our approach achieves competitive performance while meeting real-time requirements, operating at 26.3 FPS for the full model and 77.0 FPS for a smaller variant on an NVIDIA Jetson AGX Orin. Additionally, we show qualitative results that highlight the effectiveness and possible use cases in real-world applications. Overall, our method serves as a drop-in replacement for traditional segmentation approaches while enabling flexible natural-language querying and seamless integration into 3D mapping pipelines for mobile robotics.
* Published in Proc. IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2025)
PanopticNDT: Efficient and Robust Panoptic Mapping
Sep 24, 2023As the application scenarios of mobile robots are getting more complex and challenging, scene understanding becomes increasingly crucial. A mobile robot that is supposed to operate autonomously in indoor environments must have precise knowledge about what objects are present, where they are, what their spatial extent is, and how they can be reached; i.e., information about free space is also crucial. Panoptic mapping is a powerful instrument providing such information. However, building 3D panoptic maps with high spatial resolution is challenging on mobile robots, given their limited computing capabilities. In this paper, we propose PanopticNDT - an efficient and robust panoptic mapping approach based on occupancy normal distribution transform (NDT) mapping. We evaluate our approach on the publicly available datasets Hypersim and ScanNetV2. The results reveal that our approach can represent panoptic information at a higher level of detail than other state-of-the-art approaches while enabling real-time panoptic mapping on mobile robots. Finally, we prove the real-world applicability of PanopticNDT with qualitative results in a domestic application.
Efficient Multi-Task Scene Analysis with RGB-D Transformers
Jun 08, 2023Scene analysis is essential for enabling autonomous systems, such as mobile robots, to operate in real-world environments. However, obtaining a comprehensive understanding of the scene requires solving multiple tasks, such as panoptic segmentation, instance orientation estimation, and scene classification. Solving these tasks given limited computing and battery capabilities on mobile platforms is challenging. To address this challenge, we introduce an efficient multi-task scene analysis approach, called EMSAFormer, that uses an RGB-D Transformer-based encoder to simultaneously perform the aforementioned tasks. Our approach builds upon the previously published EMSANet. However, we show that the dual CNN-based encoder of EMSANet can be replaced with a single Transformer-based encoder. To achieve this, we investigate how information from both RGB and depth data can be effectively incorporated in a single encoder. To accelerate inference on robotic hardware, we provide a custom NVIDIA TensorRT extension enabling highly optimization for our EMSAFormer approach. Through extensive experiments on the commonly used indoor datasets NYUv2, SUNRGB-D, and ScanNet, we show that our approach achieves state-of-the-art performance while still enabling inference with up to 39.1 FPS on an NVIDIA Jetson AGX Orin 32 GB.
Efficient Multi-Task RGB-D Scene Analysis for Indoor Environments
Jul 10, 2022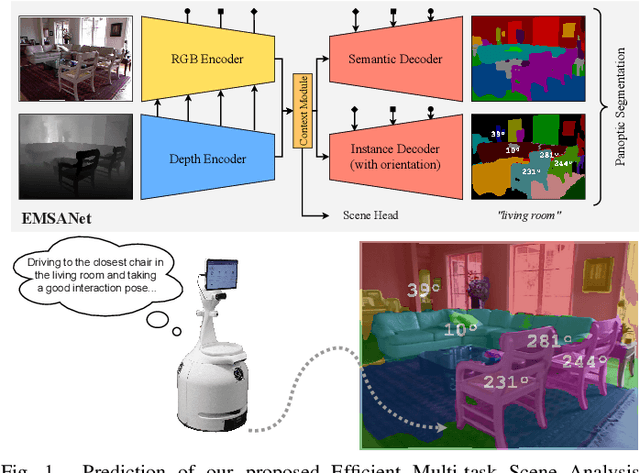


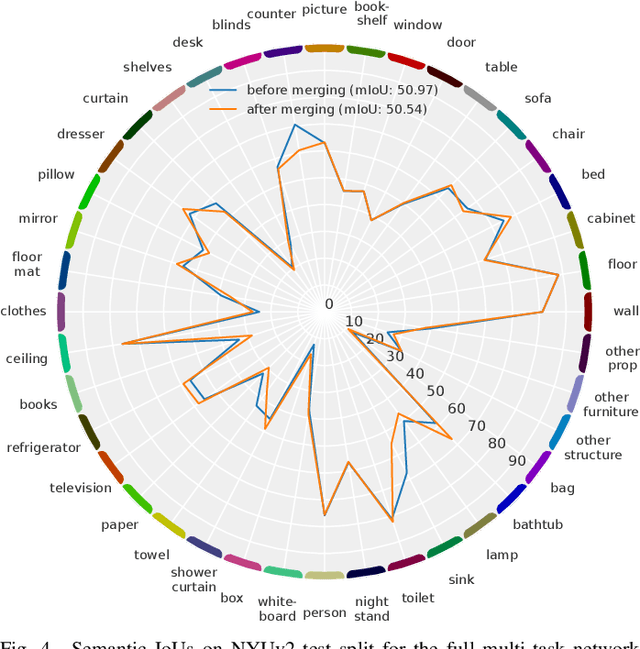
Semantic scene understanding is essential for mobile agents acting in various environments. Although semantic segmentation already provides a lot of information, details about individual objects as well as the general scene are missing but required for many real-world applications. However, solving multiple tasks separately is expensive and cannot be accomplished in real time given limited computing and battery capabilities on a mobile platform. In this paper, we propose an efficient multi-task approach for RGB-D scene analysis~(EMSANet) that simultaneously performs semantic and instance segmentation~(panoptic segmentation), instance orientation estimation, and scene classification. We show that all tasks can be accomplished using a single neural network in real time on a mobile platform without diminishing performance - by contrast, the individual tasks are able to benefit from each other. In order to evaluate our multi-task approach, we extend the annotations of the common RGB-D indoor datasets NYUv2 and SUNRGB-D for instance segmentation and orientation estimation. To the best of our knowledge, we are the first to provide results in such a comprehensive multi-task setting for indoor scene analysis on NYUv2 and SUNRGB-D.
Efficient and Robust Semantic Mapping for Indoor Environments
Mar 11, 2022
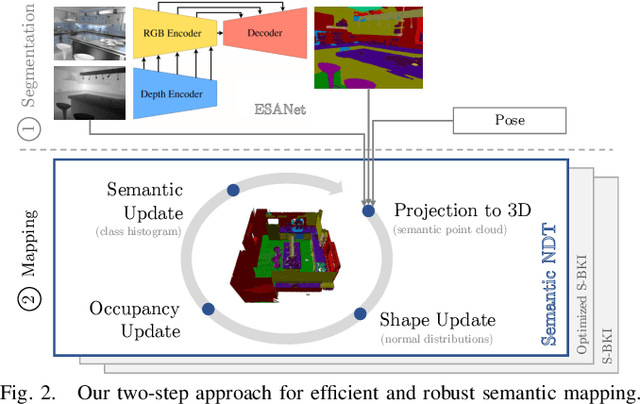


A key proficiency an autonomous mobile robot must have to perform high-level tasks is a strong understanding of its environment. This involves information about what types of objects are present, where they are, what their spatial extend is, and how they can be reached, i.e., information about free space is also crucial. Semantic maps are a powerful instrument providing such information. However, applying semantic segmentation and building 3D maps with high spatial resolution is challenging given limited resources on mobile robots. In this paper, we incorporate semantic information into efficient occupancy normal distribution transform (NDT) maps to enable real-time semantic mapping on mobile robots. On the publicly available dataset Hypersim, we show that, due to their sub-voxel accuracy, semantic NDT maps are superior to other approaches. We compare them to the recent state-of-the-art approach based on voxels and semantic Bayesian spatial kernel inference~(S-BKI) and to an optimized version of it derived in this paper. The proposed semantic NDT maps can represent semantics to the same level of detail, while mapping is 2.7 to 17.5 times faster. For the same grid resolution, they perform significantly better, while mapping is up to more than 5 times faster. Finally, we prove the real-world applicability of semantic NDT maps with qualitative results in a domestic application.
Efficient RGB-D Semantic Segmentation for Indoor Scene Analysis
Nov 13, 2020
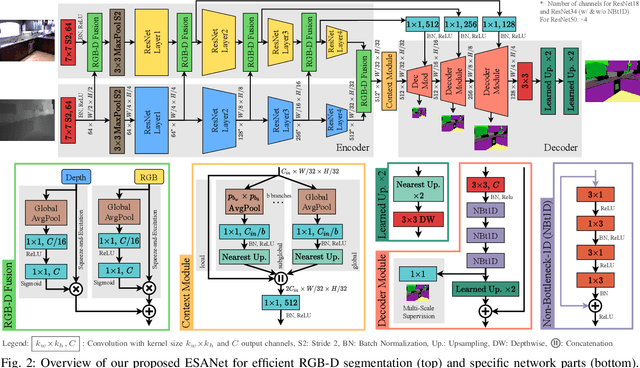

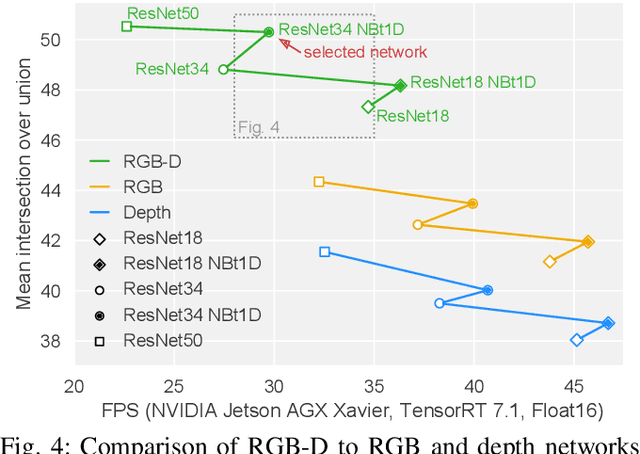
Analyzing scenes thoroughly is crucial for mobile robots acting in different environments. Semantic segmentation can enhance various subsequent tasks, such as (semantically assisted) person perception, (semantic) free space detection, (semantic) mapping, and (semantic) navigation. In this paper, we propose an efficient and robust RGB-D segmentation approach that can be optimized to a high degree using NVIDIA TensorRT and, thus, is well suited as a common initial processing step in a complex system for scene analysis on mobile robots. We show that RGB-D segmentation is superior to processing RGB images solely and that it can still be performed in real time if the network architecture is carefully designed. We evaluate our proposed Efficient Scene Analysis Network (ESANet) on the common indoor datasets NYUv2 and SUNRGB-D and show that it reaches state-of-the-art performance when considering both segmentation performance and runtime. Furthermore, our evaluation on the outdoor dataset Cityscapes shows that our approach is suitable for other areas of application as well. Finally, instead of presenting benchmark results only, we show qualitative results in one of our indoor application scenarios.