 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Prediction of Dense Visual Embeddings via Distillation and RGB-D Transformers
Jan 01, 2026In domestic environments, robots require a comprehensive understanding of their surroundings to interact effectively and intuitively with untrained humans. In this paper, we propose DVEFormer - an efficient RGB-D Transformer-based approach that predicts dense text-aligned visual embeddings (DVE) via knowledge distillation. Instead of directly performing classical semantic segmentation with fixed predefined classes, our method uses teacher embeddings from Alpha-CLIP to guide our efficient student model DVEFormer in learning fine-grained pixel-wise embeddings. While this approach still enables classical semantic segmentation, e.g., via linear probing, it further enables flexible text-based querying and other applications, such as creating comprehensive 3D maps. Evaluations on common indoor datasets demonstrate that our approach achieves competitive performance while meeting real-time requirements, operating at 26.3 FPS for the full model and 77.0 FPS for a smaller variant on an NVIDIA Jetson AGX Orin. Additionally, we show qualitative results that highlight the effectiveness and possible use cases in real-world applications. Overall, our method serves as a drop-in replacement for traditional segmentation approaches while enabling flexible natural-language querying and seamless integration into 3D mapping pipelines for mobile robotics.
* Published in Proc. IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2025)
PanopticNDT: Efficient and Robust Panoptic Mapping
Sep 24, 2023As the application scenarios of mobile robots are getting more complex and challenging, scene understanding becomes increasingly crucial. A mobile robot that is supposed to operate autonomously in indoor environments must have precise knowledge about what objects are present, where they are, what their spatial extent is, and how they can be reached; i.e., information about free space is also crucial. Panoptic mapping is a powerful instrument providing such information. However, building 3D panoptic maps with high spatial resolution is challenging on mobile robots, given their limited computing capabilities. In this paper, we propose PanopticNDT - an efficient and robust panoptic mapping approach based on occupancy normal distribution transform (NDT) mapping. We evaluate our approach on the publicly available datasets Hypersim and ScanNetV2. The results reveal that our approach can represent panoptic information at a higher level of detail than other state-of-the-art approaches while enabling real-time panoptic mapping on mobile robots. Finally, we prove the real-world applicability of PanopticNDT with qualitative results in a domestic application.
Fusing Hand and Body Skeletons for Human Action Recognition in Assembly
Jul 18, 2023



As collaborative robots (cobots) continue to gain popularity in industrial manufacturing, effective human-robot collaboration becomes crucial. Cobots should be able to recognize human actions to assist with assembly tasks and act autonomously. To achieve this, skeleton-based approaches are often used due to their ability to generalize across various people and environments. Although body skeleton approaches are widely used for action recognition, they may not be accurate enough for assembly actions where the worker's fingers and hands play a significant role. To address this limitation, we propose a method in which less detailed body skeletons are combined with highly detailed hand skeletons. We investigate CNNs and transformers, the latter of which are particularly adept at extracting and combining important information from both skeleton types using attention. This paper demonstrates the effectiveness of our proposed approach in enhancing action recognition in assembly scenarios.
How Object Information Improves Skeleton-based Human Action Recognition in Assembly Tasks
Jun 09, 2023As the use of collaborative robots (cobots) in industrial manufacturing continues to grow, human action recognition for effective human-robot collaboration becomes increasingly important. This ability is crucial for cobots to act autonomously and assist in assembly tasks. Recently, skeleton-based approaches are often used as they tend to generalize better to different people and environments. However, when processing skeletons alone, information about the objects a human interacts with is lost. Therefore, we present a novel approach of integrating object information into skeleton-based action recognition. We enhance two state-of-the-art methods by treating object centers as further skeleton joints. Our experiments on the assembly dataset IKEA ASM show that our approach improves the performance of these state-of-the-art methods to a large extent when combining skeleton joints with objects predicted by a state-of-the-art instance segmentation model. Our research sheds light on the benefits of combining skeleton joints with object information for human action recognition in assembly tasks. We analyze the effect of the object detector on the combination for action classification and discuss the important factors that must be taken into account.
Efficient Multi-Task Scene Analysis with RGB-D Transformers
Jun 08, 2023Scene analysis is essential for enabling autonomous systems, such as mobile robots, to operate in real-world environments. However, obtaining a comprehensive understanding of the scene requires solving multiple tasks, such as panoptic segmentation, instance orientation estimation, and scene classification. Solving these tasks given limited computing and battery capabilities on mobile platforms is challenging. To address this challenge, we introduce an efficient multi-task scene analysis approach, called EMSAFormer, that uses an RGB-D Transformer-based encoder to simultaneously perform the aforementioned tasks. Our approach builds upon the previously published EMSANet. However, we show that the dual CNN-based encoder of EMSANet can be replaced with a single Transformer-based encoder. To achieve this, we investigate how information from both RGB and depth data can be effectively incorporated in a single encoder. To accelerate inference on robotic hardware, we provide a custom NVIDIA TensorRT extension enabling highly optimization for our EMSAFormer approach. Through extensive experiments on the commonly used indoor datasets NYUv2, SUNRGB-D, and ScanNet, we show that our approach achieves state-of-the-art performance while still enabling inference with up to 39.1 FPS on an NVIDIA Jetson AGX Orin 32 GB.
ATTACH Dataset: Annotated Two-Handed Assembly Actions for Human Action Understanding
Apr 17, 2023With the emergence of collaborative robots (cobots), human-robot collaboration in industrial manufacturing is coming into focus. For a cobot to act autonomously and as an assistant, it must understand human actions during assembly. To effectively train models for this task, a dataset containing suitable assembly actions in a realistic setting is crucial. For this purpose, we present the ATTACH dataset, which contains 51.6 hours of assembly with 95.2k annotated fine-grained actions monitored by three cameras, which represent potential viewpoints of a cobot. Since in an assembly context workers tend to perform different actions simultaneously with their two hands, we annotated the performed actions for each hand separately. Therefore, in the ATTACH dataset, more than 68% of annotations overlap with other annotations, which is many times more than in related datasets, typically featuring more simplistic assembly tasks. For better generalization with respect to the background of the working area, we did not only record color and depth images, but also used the Azure Kinect body tracking SDK for estimating 3D skeletons of the worker. To create a first baseline, we report the performance of state-of-the-art methods for action recognition as well as action detection on video and skeleton-sequence inputs. The dataset is available at https://www.tu-ilmenau.de/neurob/data-sets-code/attach-dataset .
A Little Bit Attention Is All You Need for Person Re-Identification
Feb 28, 2023Person re-identification plays a key role in applications where a mobile robot needs to track its users over a long period of time, even if they are partially unobserved for some time, in order to follow them or be available on demand. In this context, deep-learning based real-time feature extraction on a mobile robot is often performed on special-purpose devices whose computational resources are shared for multiple tasks. Therefore, the inference speed has to be taken into account. In contrast, person re-identification is often improved by architectural changes that come at the cost of significantly slowing down inference. Attention blocks are one such example. We will show that some well-performing attention blocks used in the state of the art are subject to inference costs that are far too high to justify their use for mobile robotic applications. As a consequence, we propose an attention block that only slightly affects the inference speed while keeping up with much deeper networks or more complex attention blocks in terms of re-identification accuracy. We perform extensive neural architecture search to derive rules at which locations this attention block should be integrated into the architecture in order to achieve the best trade-off between speed and accuracy. Finally, we confirm that the best performing configuration on a re-identification benchmark also performs well on an indoor robotic dataset.
Relate to Predict: Towards Task-Independent Knowledge Representations for Reinforcement Learning
Dec 10, 2022



Reinforcement Learning (RL) can enable agents to learn complex tasks. However, it is difficult to interpret the knowledge and reuse it across tasks. Inductive biases can address such issues by explicitly providing generic yet useful decomposition that is otherwise difficult or expensive to learn implicitly. For example, object-centered approaches decompose a high dimensional observation into individual objects. Expanding on this, we utilize an inductive bias for explicit object-centered knowledge separation that provides further decomposition into semantic representations and dynamics knowledge. For this, we introduce a semantic module that predicts an objects' semantic state based on its context. The resulting affordance-like object state can then be used to enrich perceptual object representations. With a minimal setup and an environment that enables puzzle-like tasks, we demonstrate the feasibility and benefits of this approach. Specifically, we compare three different methods of integrating semantic representations into a model-based RL architecture. Our experiments show that the degree of explicitness in knowledge separation correlates with faster learning, better accuracy, better generalization, and better interpretability.
Efficient and Robust Semantic Mapping for Indoor Environments
Mar 11, 2022
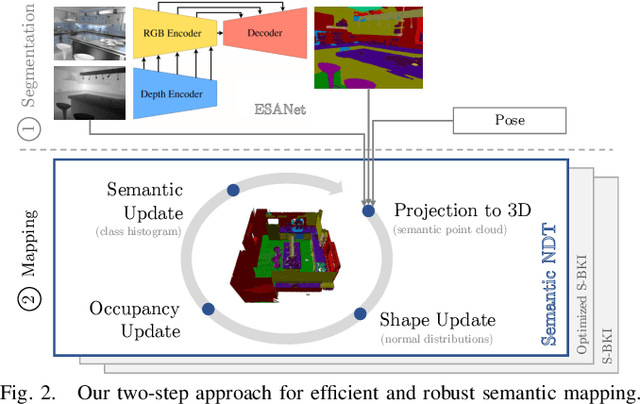


A key proficiency an autonomous mobile robot must have to perform high-level tasks is a strong understanding of its environment. This involves information about what types of objects are present, where they are, what their spatial extend is, and how they can be reached, i.e., information about free space is also crucial. Semantic maps are a powerful instrument providing such information. However, applying semantic segmentation and building 3D maps with high spatial resolution is challenging given limited resources on mobile robots. In this paper, we incorporate semantic information into efficient occupancy normal distribution transform (NDT) maps to enable real-time semantic mapping on mobile robots. On the publicly available dataset Hypersim, we show that, due to their sub-voxel accuracy, semantic NDT maps are superior to other approaches. We compare them to the recent state-of-the-art approach based on voxels and semantic Bayesian spatial kernel inference~(S-BKI) and to an optimized version of it derived in this paper. The proposed semantic NDT maps can represent semantics to the same level of detail, while mapping is 2.7 to 17.5 times faster. For the same grid resolution, they perform significantly better, while mapping is up to more than 5 times faster. Finally, we prove the real-world applicability of semantic NDT maps with qualitative results in a domestic application.
Few-Shot Object Detection: A Survey
Dec 22, 2021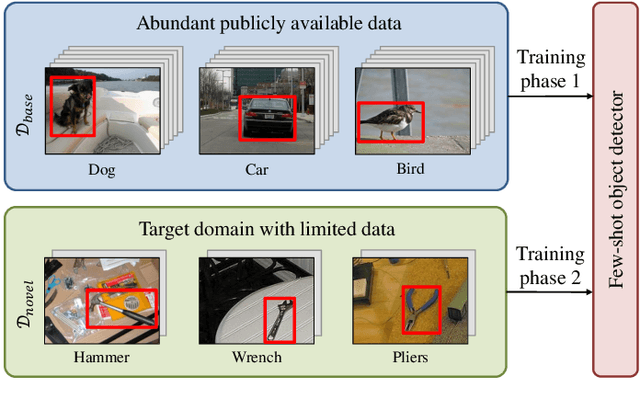

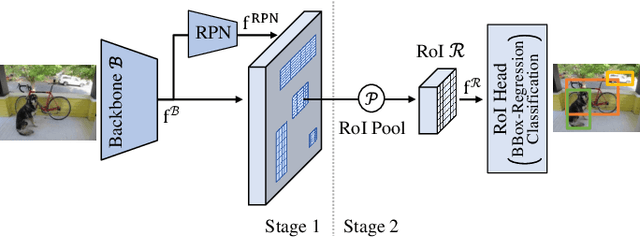
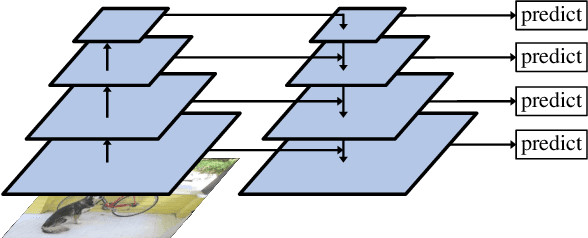
Humans are able to learn to recognize new objects even from a few examples. In contrast, training deep-learning-based object detectors requires huge amounts of annotated data. To avoid the need to acquire and annotate these huge amounts of data, few-shot object detection aims to learn from few object instances of new categories in the target domain. In this survey, we provide an overview of the state of the art in few-shot object detection. We categorize approaches according to their training scheme and architectural layout. For each type of approaches, we describe the general realization as well as concepts to improve the performance on novel categories. Whenever appropriate, we give short takeaways regarding these concepts in order to highlight the best ideas. Eventually, we introduce commonly used datasets and their evaluation protocols and analyze reported benchmark results. As a result, we emphasize common challenges in evaluation and identify the most promising current trends in this emerging field of few-shot object detection.