 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusing Hand and Body Skeletons for Human Action Recognition in Assembly
Jul 18, 2023



As collaborative robots (cobots) continue to gain popularity in industrial manufacturing, effective human-robot collaboration becomes crucial. Cobots should be able to recognize human actions to assist with assembly tasks and act autonomously. To achieve this, skeleton-based approaches are often used due to their ability to generalize across various people and environments. Although body skeleton approaches are widely used for action recognition, they may not be accurate enough for assembly actions where the worker's fingers and hands play a significant role. To address this limitation, we propose a method in which less detailed body skeletons are combined with highly detailed hand skeletons. We investigate CNNs and transformers, the latter of which are particularly adept at extracting and combining important information from both skeleton types using attention. This paper demonstrates the effectiveness of our proposed approach in enhancing action recognition in assembly scenarios.
How Object Information Improves Skeleton-based Human Action Recognition in Assembly Tasks
Jun 09, 2023As the use of collaborative robots (cobots) in industrial manufacturing continues to grow, human action recognition for effective human-robot collaboration becomes increasingly important. This ability is crucial for cobots to act autonomously and assist in assembly tasks. Recently, skeleton-based approaches are often used as they tend to generalize better to different people and environments. However, when processing skeletons alone, information about the objects a human interacts with is lost. Therefore, we present a novel approach of integrating object information into skeleton-based action recognition. We enhance two state-of-the-art methods by treating object centers as further skeleton joints. Our experiments on the assembly dataset IKEA ASM show that our approach improves the performance of these state-of-the-art methods to a large extent when combining skeleton joints with objects predicted by a state-of-the-art instance segmentation model. Our research sheds light on the benefits of combining skeleton joints with object information for human action recognition in assembly tasks. We analyze the effect of the object detector on the combination for action classification and discuss the important factors that must be taken into account.
Efficient Multi-Task RGB-D Scene Analysis for Indoor Environments
Jul 10, 2022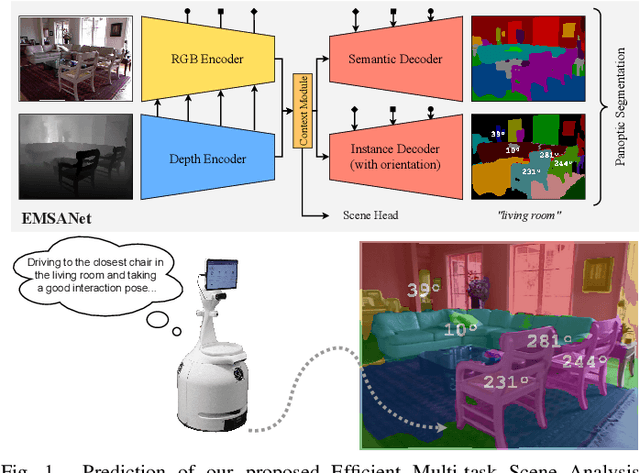


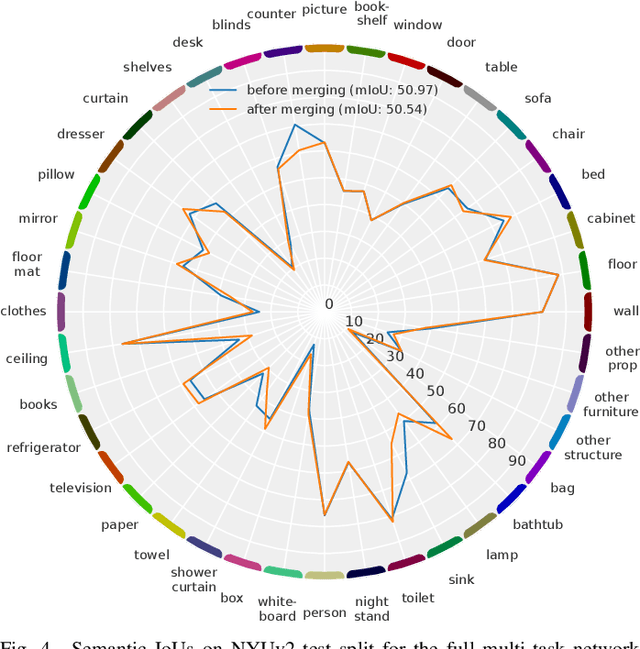
Semantic scene understanding is essential for mobile agents acting in various environments. Although semantic segmentation already provides a lot of information, details about individual objects as well as the general scene are missing but required for many real-world applications. However, solving multiple tasks separately is expensive and cannot be accomplished in real time given limited computing and battery capabilities on a mobile platform. In this paper, we propose an efficient multi-task approach for RGB-D scene analysis~(EMSANet) that simultaneously performs semantic and instance segmentation~(panoptic segmentation), instance orientation estimation, and scene classification. We show that all tasks can be accomplished using a single neural network in real time on a mobile platform without diminishing performance - by contrast, the individual tasks are able to benefit from each other. In order to evaluate our multi-task approach, we extend the annotations of the common RGB-D indoor datasets NYUv2 and SUNRGB-D for instance segmentation and orientation estimation. To the best of our knowledge, we are the first to provide results in such a comprehensive multi-task setting for indoor scene analysis on NYUv2 and SUNRGB-D.
Few-Shot Object Detection: A Survey
Dec 22, 2021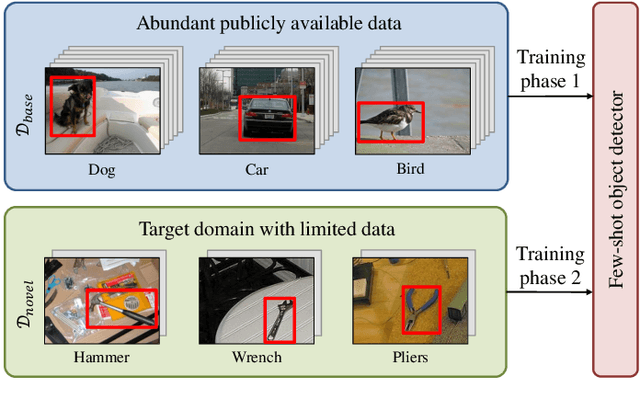

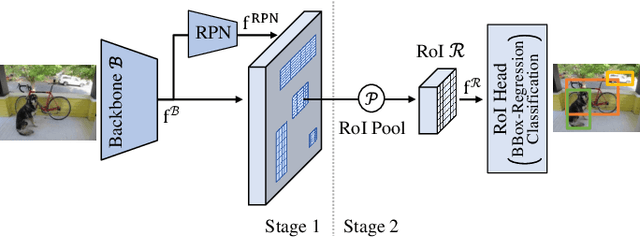
Humans are able to learn to recognize new objects even from a few examples. In contrast, training deep-learning-based object detectors requires huge amounts of annotated data. To avoid the need to acquire and annotate these huge amounts of data, few-shot object detection aims to learn from few object instances of new categories in the target domain. In this survey, we provide an overview of the state of the art in few-shot object detection. We categorize approaches according to their training scheme and architectural layout. For each type of approaches, we describe the general realization as well as concepts to improve the performance on novel categories. Whenever appropriate, we give short takeaways regarding these concepts in order to highlight the best ideas. Eventually, we introduce commonly used datasets and their evaluation protocols and analyze reported benchmark results. As a result, we emphasize common challenges in evaluation and identify the most promising current trends in this emerging field of few-shot object detection.
Efficient RGB-D Semantic Segmentation for Indoor Scene Analysis
Nov 13, 2020
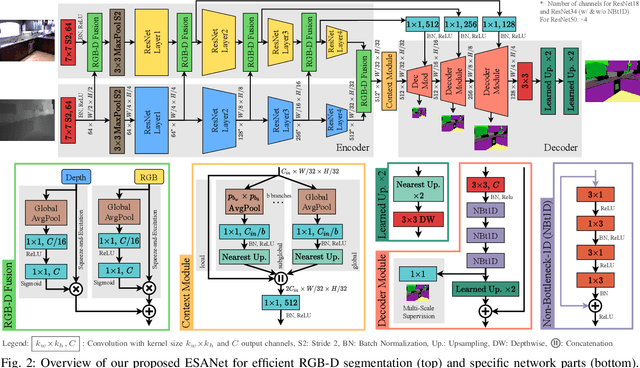

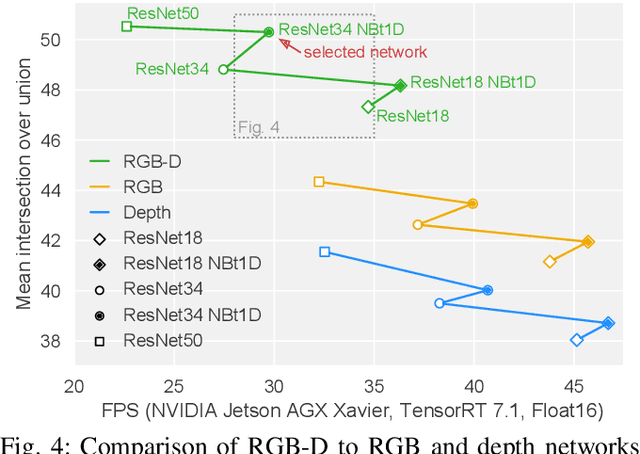
Analyzing scenes thoroughly is crucial for mobile robots acting in different environments. Semantic segmentation can enhance various subsequent tasks, such as (semantically assisted) person perception, (semantic) free space detection, (semantic) mapping, and (semantic) navigation. In this paper, we propose an efficient and robust RGB-D segmentation approach that can be optimized to a high degree using NVIDIA TensorRT and, thus, is well suited as a common initial processing step in a complex system for scene analysis on mobile robots. We show that RGB-D segmentation is superior to processing RGB images solely and that it can still be performed in real time if the network architecture is carefully designed. We evaluate our proposed Efficient Scene Analysis Network (ESANet) on the common indoor datasets NYUv2 and SUNRGB-D and show that it reaches state-of-the-art performance when considering both segmentation performance and runtime. Furthermore, our evaluation on the outdoor dataset Cityscapes shows that our approach is suitable for other areas of application as well. Finally, instead of presenting benchmark results only, we show qualitative results in one of our indoor application scenarios.