 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Predictive Performance and Calibration by Weight Fusion in Semantic Segmentation
Jul 22, 2022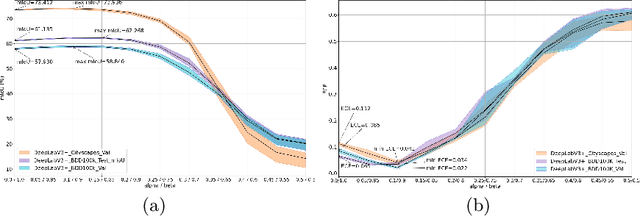

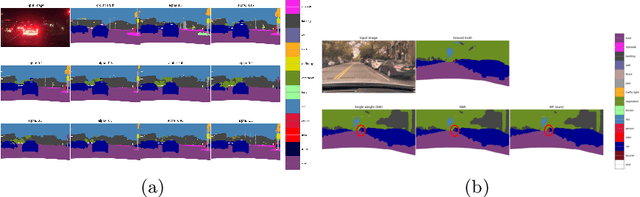
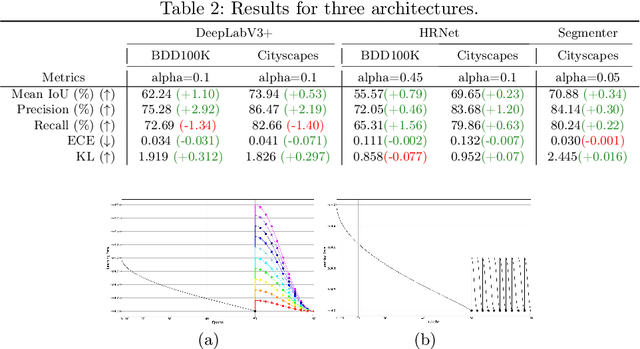
Averaging predictions of a deep ensemble of networks is apopular and effective method to improve predictive performance andcalibration in various benchmarks and Kaggle competitions. However, theruntime and training cost of deep ensembles grow linearly with the size ofthe ensemble, making them unsuitable for many applications. Averagingensemble weights instead of predictions circumvents this disadvantageduring inference and is typically applied to intermediate checkpoints ofa model to reduce training cost. Albeit effective, only few works haveimproved the understanding and the performance of weight averaging.Here, we revisit this approach and show that a simple weight fusion (WF)strategy can lead to a significantly improved predictive performance andcalibration. We describe what prerequisites the weights must meet interms of weight space, functional space and loss. Furthermore, we presenta new test method (called oracle test) to measure the functional spacebetween weights. We demonstrate the versatility of our WF strategy acrossstate of the art segmentation CNNs and Transformers as well as real worlddatasets such as BDD100K and Cityscapes. We compare WF with similarapproaches and show our superiority for in- and out-of-distribution datain terms of predictive performance and calibration.