 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Conditional Imitation Learning for Autonomous Driving
Nov 17, 2022

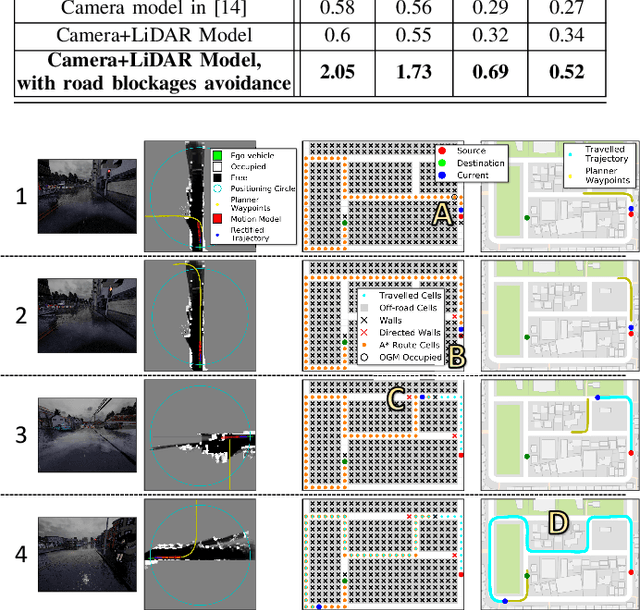

Conditional imitation learning (CIL) trains deep neural networks, in an end-to-end manner, to mimic human driving. This approach has demonstrated suitable vehicle control when following roads, avoiding obstacles, or taking specific turns at intersections to reach a destination. Unfortunately, performance dramatically decreases when deployed to unseen environments and is inconsistent against varying weather conditions. Most importantly, the current CIL fails to avoid static road blockages. In this work, we propose a solution to those deficiencies. First, we fuse the laser scanner with the regular camera streams, at the features level, to overcome the generalization and consistency challenges. Second, we introduce a new efficient Occupancy Grid Mapping (OGM) method along with new algorithms for road blockages avoidance and global route planning. Consequently, our proposed method dynamically detects partial and full road blockages, and guides the controlled vehicle to another route to reach the destination. Following the original CIL work, we demonstrated the effectiveness of our proposal on CARLA simulator urban driving benchmark. Our experiments showed that our model improved consistency against weather conditions by four times and autonomous driving success rate generalization by 52%. Furthermore, our global route planner improved the driving success rate by 37%. Our proposed road blockages avoidance algorithm improved the driving success rate by 27%. Finally, the average kilometers traveled before a collision with a static object increased by 1.5 times. The main source code can be reached at https://heshameraqi.github.io/dynamic_cil_autonomous_driving.
* 14 pages, 11 figures, 7 tables
Complexer-YOLO: Real-Time 3D Object Detection and Tracking on Semantic Point Clouds
Apr 16, 2019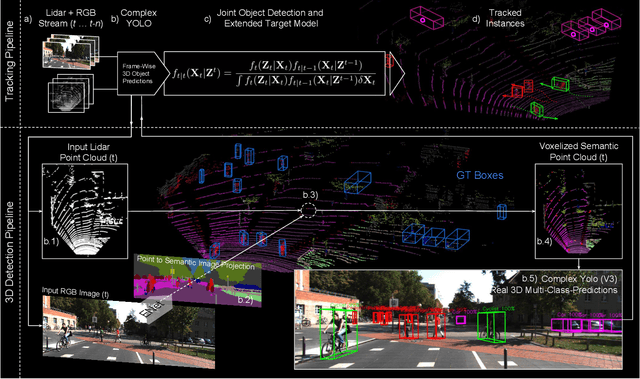
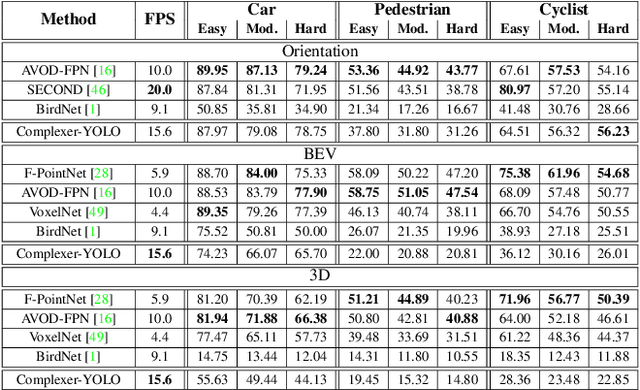
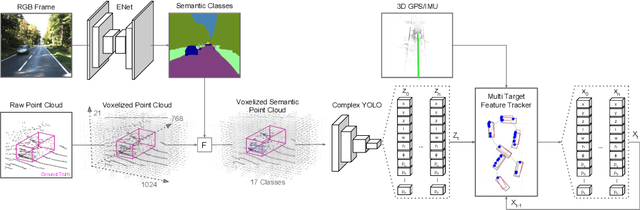
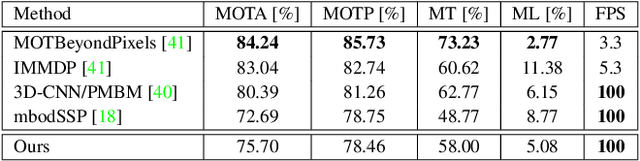
Accurate detection of 3D objects is a fundamental problem in computer vision and has an enormous impact on autonomous cars, augmented/virtual reality and many applications in robotics. In this work we present a novel fusion of neural network based state-of-the-art 3D detector and visual semantic segmentation in the context of autonomous driving. Additionally, we introduce Scale-Rotation-Translation score (SRTs), a fast and highly parameterizable evaluation metric for comparison of object detections, which speeds up our inference time up to 20\% and halves training time. On top, we apply state-of-the-art online multi target feature tracking on the object measurements to further increase accuracy and robustness utilizing temporal information. Our experiments on KITTI show that we achieve same results as state-of-the-art in all related categories, while maintaining the performance and accuracy trade-off and still run in real-time. Furthermore, our model is the first one that fuses visual semantic with 3D object detection.
Static Free Space Detection with Laser Scanner using Occupancy Grid Maps
Jan 02, 2018



Drivable free space information is vital for autonomous vehicles that have to plan evasive maneuvers in real-time. In this paper, we present a new efficient method for environmental free space detection with laser scanner based on 2D occupancy grid maps (OGM) to be used for Advanced Driving Assistance Systems (ADAS) and Collision Avoidance Systems (CAS). Firstly, we introduce an enhanced inverse sensor model tailored for high-resolution laser scanners for building OGM. It compensates the unreflected beams and deals with the ray casting to grid cells accuracy and computational effort problems. Secondly, we introduce the 'vehicle on a circle for grid maps' map alignment algorithm that allows building more accurate local maps by avoiding the computationally expensive inaccurate operations of image sub-pixel shifting and rotation. The resulted grid map is more convenient for ADAS features than existing methods, as it allows using less memory sizes, and hence, results into a better real-time performance. Thirdly, we present an algorithm to detect what we call the 'in-sight edges'. These edges guarantee modeling the free space area with a single polygon of a fixed number of vertices regardless the driving situation and map complexity. The results from real world experiments show the effectiveness of our approach.
* IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, JAPAN, October 2017
End-to-End Deep Learning for Steering Autonomous Vehicles Considering Temporal Dependencies
Nov 22, 2017
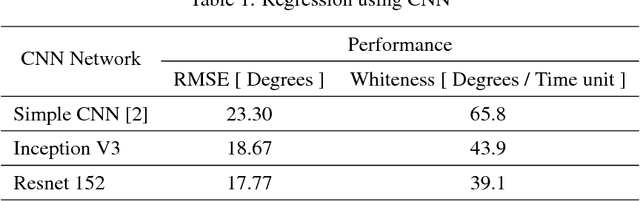


Steering a car through traffic is a complex task that is difficult to cast into algorithms. Therefore, researchers turn to training artificial neural networks from front-facing camera data stream along with the associated steering angles. Nevertheless, most existing solutions consider only the visual camera frames as input, thus ignoring the temporal relationship between frames. In this work, we propose a Convolutional Long Short-Term Memory Recurrent Neural Network (C-LSTM), that is end-to-end trainable, to learn both visual and dynamic temporal dependencies of driving. Additionally, We introduce posing the steering angle regression problem as classification while imposing a spatial relationship between the output layer neurons. Such method is based on learning a sinusoidal function that encodes steering angles. To train and validate our proposed methods, we used the publicly available Comma.ai dataset. Our solution improved steering root mean square error by 35% over recent methods, and led to a more stable steering by 87%.