 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Steering for Autonomous Vehicles via Conditional Imitation Co-Learning
Nov 25, 2024



Autonomous driving involves complex tasks such as data fusion, object and lane detection, behavior prediction, and path planning. As opposed to the modular approach which dedicates individual subsystems to tackle each of those tasks, the end-to-end approach treats the problem as a single learnable task using deep neural networks, reducing system complexity and minimizing dependency on heuristics. Conditional imitation learning (CIL) trains the end-to-end model to mimic a human expert considering the navigational commands guiding the vehicle to reach its destination, CIL adopts specialist network branches dedicated to learn the driving task for each navigational command. Nevertheless, the CIL model lacked generalization when deployed to unseen environments. This work introduces the conditional imitation co-learning (CIC) approach to address this issue by enabling the model to learn the relationships between CIL specialist branches via a co-learning matrix generated by gated hyperbolic tangent units (GTUs). Additionally, we propose posing the steering regression problem as classification, we use a classification-regression hybrid loss to bridge the gap between regression and classification, we also propose using co-existence probability to consider the spatial tendency between the steering classes. Our model is demonstrated to improve autonomous driving success rate in unseen environment by 62% on average compared to the CIL method.
* NCTA 2024 Best Paper Honorable Mention
Dynamic Conditional Imitation Learning for Autonomous Driving
Nov 17, 2022

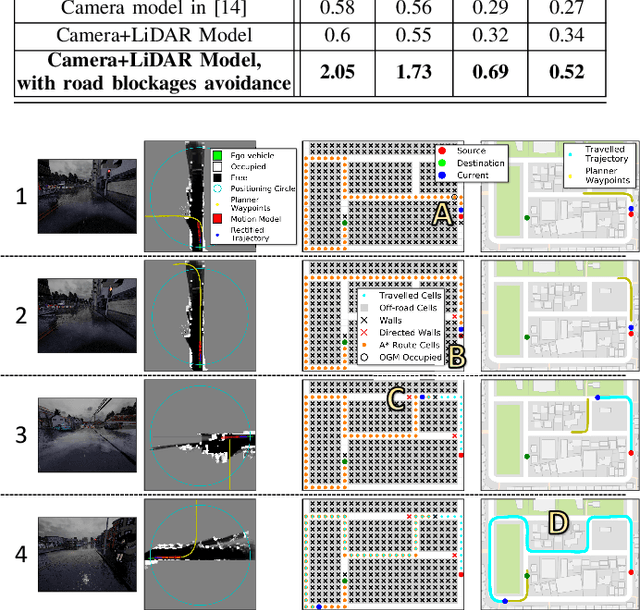

Conditional imitation learning (CIL) trains deep neural networks, in an end-to-end manner, to mimic human driving. This approach has demonstrated suitable vehicle control when following roads, avoiding obstacles, or taking specific turns at intersections to reach a destination. Unfortunately, performance dramatically decreases when deployed to unseen environments and is inconsistent against varying weather conditions. Most importantly, the current CIL fails to avoid static road blockages. In this work, we propose a solution to those deficiencies. First, we fuse the laser scanner with the regular camera streams, at the features level, to overcome the generalization and consistency challenges. Second, we introduce a new efficient Occupancy Grid Mapping (OGM) method along with new algorithms for road blockages avoidance and global route planning. Consequently, our proposed method dynamically detects partial and full road blockages, and guides the controlled vehicle to another route to reach the destination. Following the original CIL work, we demonstrated the effectiveness of our proposal on CARLA simulator urban driving benchmark. Our experiments showed that our model improved consistency against weather conditions by four times and autonomous driving success rate generalization by 52%. Furthermore, our global route planner improved the driving success rate by 37%. Our proposed road blockages avoidance algorithm improved the driving success rate by 27%. Finally, the average kilometers traveled before a collision with a static object increased by 1.5 times. The main source code can be reached at https://heshameraqi.github.io/dynamic_cil_autonomous_driving.
* 14 pages, 11 figures, 7 tables
Collision-Free Navigation using Evolutionary Symmetrical Neural Networks
Apr 11, 2022


Collision avoidance systems play a vital role in reducing the number of vehicle accidents and saving human lives. This paper extends the previous work using evolutionary neural networks for reactive collision avoidance. We are proposing a new method we have called symmetric neural networks. The method improves the model's performance by enforcing constraints between the network weights which reduces the model optimization search space and hence, learns more accurate control of the vehicle steering for improved maneuvering. The training and validation processes are carried out using a simulation environment - the codebase is publicly available. Extensive experiments are conducted to analyze the proposed method and evaluate its performance. The method is tested in several simulated driving scenarios. In addition, we have analyzed the effect of the rangefinder sensor resolution and noise on the overall goal of reactive collision avoidance. Finally, we have tested the generalization of the proposed method. The results are encouraging; the proposed method has improved the model's learning curve for training scenarios and generalization to the new test scenarios. Using constrained weights has significantly improved the number of generations required for the Genetic Algorithm optimization.
* arXiv admin note: text overlap with arXiv:1609.08414
ASMDD: Arabic Speech Mispronunciation Detection Dataset
Nov 01, 2021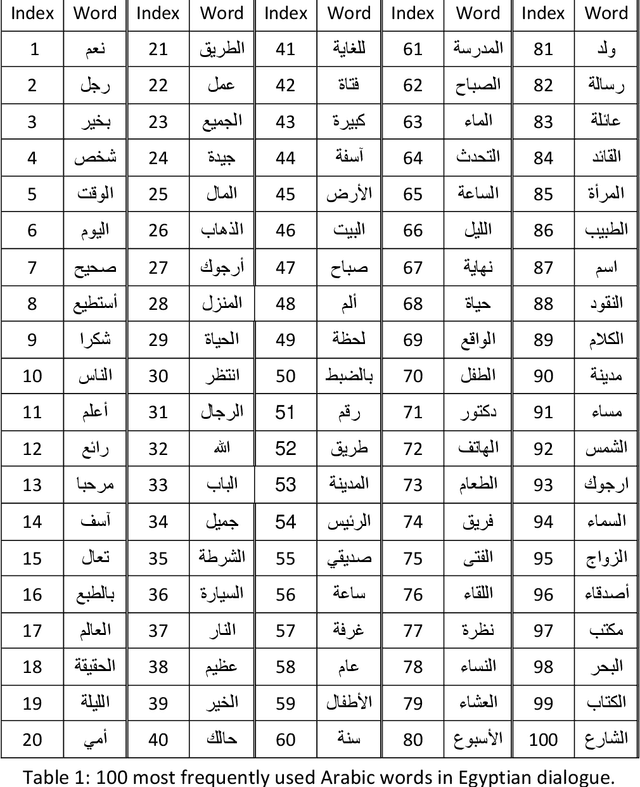
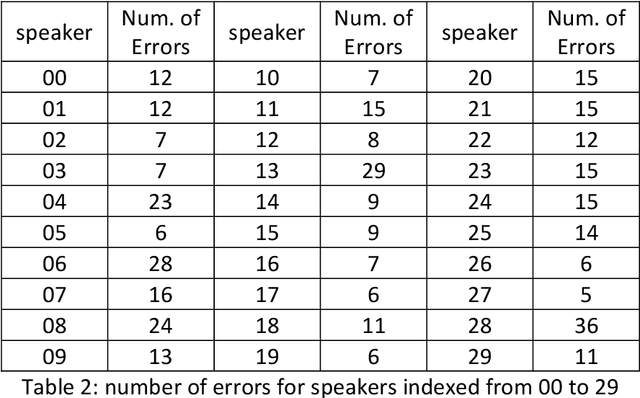

The largest dataset of Arabic speech mispronunciation detections in Egyptian dialogues is introduced. The dataset is composed of annotated audio files representing the top 100 words that are most frequently used in the Arabic language, pronounced by 100 Egyptian children (aged between 2 and 8 years old). The dataset is collected and annotated on segmental pronunciation error detections by expert listeners.
An Evaluation of RGB and LiDAR Fusion for Semantic Segmentation
Aug 17, 2021
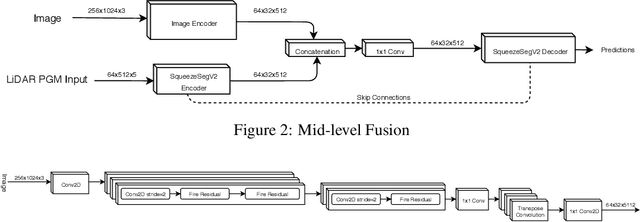
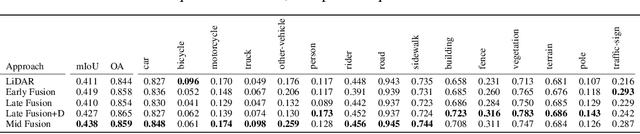
LiDARs and cameras are the two main sensors that are planned to be included in many announced autonomous vehicles prototypes. Each of the two provides a unique form of data from a different perspective to the surrounding environment. In this paper, we explore and attempt to answer the question: is there an added benefit by fusing those two forms of data for the purpose of semantic segmentation within the context of autonomous driving? We also attempt to show at which level does said fusion prove to be the most useful. We evaluated our algorithms on the publicly available SemanticKITTI dataset. All fusion models show improvements over the base model, with the mid-level fusion showing the highest improvement of 2.7% in terms of mean Intersection over Union (mIoU) metric.
Spatio-Temporal Attention Mechanism and Knowledge Distillation for Lip Reading
Aug 07, 2021

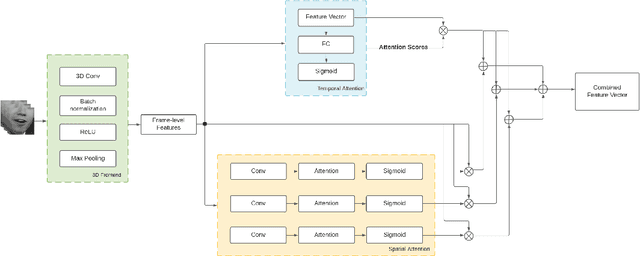

Despite the advancement in the domain of audio and audio-visual speech recognition, visual speech recognition systems are still quite under-explored due to the visual ambiguity of some phonemes. In this work, we propose a new lip-reading model that combines three contributions. First, the model front-end adopts a spatio-temporal attention mechanism to help extract the informative data from the input visual frames. Second, the model back-end utilizes a sequence-level and frame-level Knowledge Distillation (KD) techniques that allow leveraging audio data during the visual model training. Third, a data preprocessing pipeline is adopted that includes facial landmarks detection-based lip-alignment. On LRW lip-reading dataset benchmark, a noticeable accuracy improvement is demonstrated; the spatio-temporal attention, Knowledge Distillation, and lip-alignment contributions achieved 88.43%, 88.64%, and 88.37% respectively.
Pervasive Hand Gesture Recognition for Smartphones using Non-audible Sound and Deep Learning
Aug 04, 2021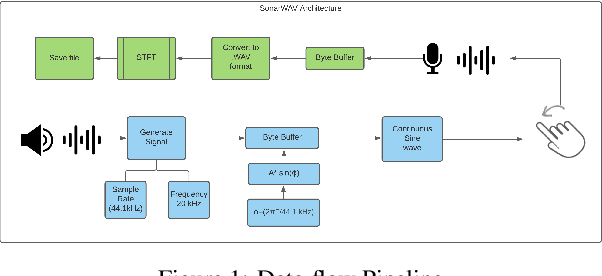
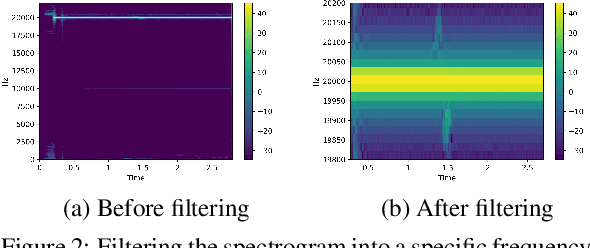
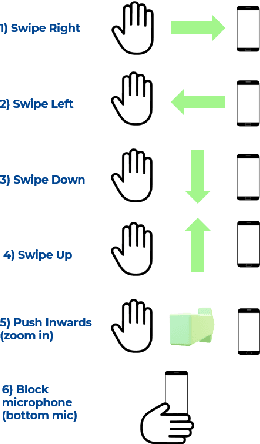
Due to the mass advancement in ubiquitous technologies nowadays, new pervasive methods have come into the practice to provide new innovative features and stimulate the research on new human-computer interactions. This paper presents a hand gesture recognition method that utilizes the smartphone's built-in speakers and microphones. The proposed system emits an ultrasonic sonar-based signal (inaudible sound) from the smartphone's stereo speakers, which is then received by the smartphone's microphone and processed via a Convolutional Neural Network (CNN) for Hand Gesture Recognition. Data augmentation techniques are proposed to improve the detection accuracy and three dual-channel input fusion methods are compared. The first method merges the dual-channel audio as a single input spectrogram image. The second method adopts early fusion by concatenating the dual-channel spectrograms. The third method adopts late fusion by having two convectional input branches processing each of the dual-channel spectrograms and then the outputs are merged by the last layers. Our experimental results demonstrate a promising detection accuracy for the six gestures presented in our publicly available dataset with an accuracy of 93.58\% as a baseline.
End-to-end sensor modeling for LiDAR Point Cloud
Jul 17, 2019



Advanced sensors are a key to enable self-driving cars technology. Laser scanner sensors (LiDAR, Light Detection And Ranging) became a fundamental choice due to its long-range and robustness to low light driving conditions. The problem of designing a control software for self-driving cars is a complex task to explicitly formulate in rule-based systems, thus recent approaches rely on machine learning that can learn those rules from data. The major problem with such approaches is that the amount of training data required for generalizing a machine learning model is big, and on the other hand LiDAR data annotation is very costly compared to other car sensors. An accurate LiDAR sensor model can cope with such problem. Moreover, its value goes beyond this because existing LiDAR development, validation, and evaluation platforms and processes are very costly, and virtual testing and development environments are still immature in terms of physical properties representation. In this work we propose a novel Deep Learning-based LiDAR sensor model. This method models the sensor echos, using a Deep Neural Network to model echo pulse widths learned from real data using Polar Grid Maps (PGM). We benchmark our model performance against comprehensive real sensor data and very promising results are achieved that sets a baseline for future works.
Driver Distraction Identification with an Ensemble of Convolutional Neural Networks
Jan 22, 2019
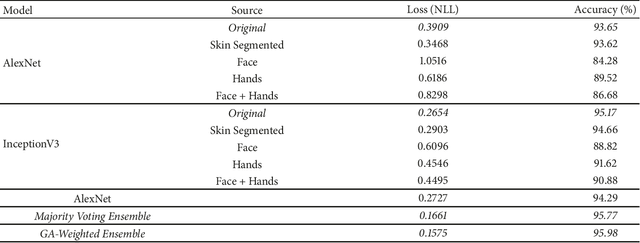

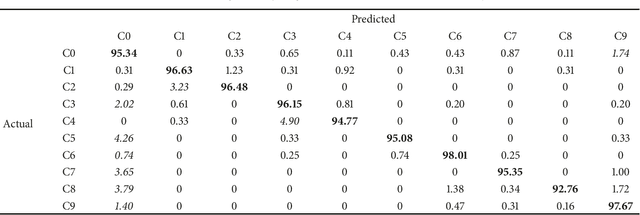
The World Health Organization (WHO) reported 1.25 million deaths yearly due to road traffic accidents worldwide and the number has been continuously increasing over the last few years. Nearly fifth of these accidents are caused by distracted drivers. Existing work of distracted driver detection is concerned with a small set of distractions (mostly, cell phone usage). Unreliable ad-hoc methods are often used.In this paper, we present the first publicly available dataset for driver distraction identification with more distraction postures than existing alternatives. In addition, we propose a reliable deep learning-based solution that achieves a 90% accuracy. The system consists of a genetically-weighted ensemble of convolutional neural networks, we show that a weighted ensemble of classifiers using a genetic algorithm yields in a better classification confidence. We also study the effect of different visual elements in distraction detection by means of face and hand localizations, and skin segmentation. Finally, we present a thinned version of our ensemble that could achieve 84.64% classification accuracy and operate in a real-time environment.
* arXiv admin note: substantial text overlap with arXiv:1706.09498
Static Free Space Detection with Laser Scanner using Occupancy Grid Maps
Jan 02, 2018



Drivable free space information is vital for autonomous vehicles that have to plan evasive maneuvers in real-time. In this paper, we present a new efficient method for environmental free space detection with laser scanner based on 2D occupancy grid maps (OGM) to be used for Advanced Driving Assistance Systems (ADAS) and Collision Avoidance Systems (CAS). Firstly, we introduce an enhanced inverse sensor model tailored for high-resolution laser scanners for building OGM. It compensates the unreflected beams and deals with the ray casting to grid cells accuracy and computational effort problems. Secondly, we introduce the 'vehicle on a circle for grid maps' map alignment algorithm that allows building more accurate local maps by avoiding the computationally expensive inaccurate operations of image sub-pixel shifting and rotation. The resulted grid map is more convenient for ADAS features than existing methods, as it allows using less memory sizes, and hence, results into a better real-time performance. Thirdly, we present an algorithm to detect what we call the 'in-sight edges'. These edges guarantee modeling the free space area with a single polygon of a fixed number of vertices regardless the driving situation and map complexity. The results from real world experiments show the effectiveness of our approach.
* IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, JAPAN, October 2017