 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Evaluation of RGB and LiDAR Fusion for Semantic Segmentation
Aug 17, 2021
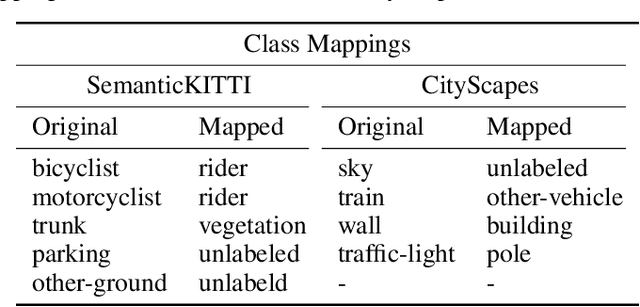
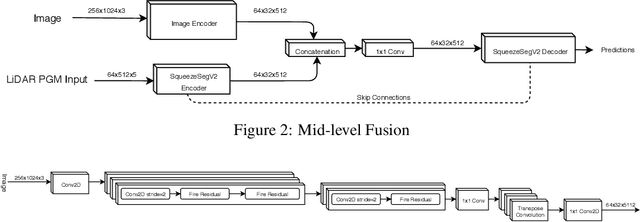
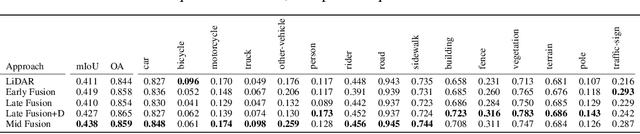
LiDARs and cameras are the two main sensors that are planned to be included in many announced autonomous vehicles prototypes. Each of the two provides a unique form of data from a different perspective to the surrounding environment. In this paper, we explore and attempt to answer the question: is there an added benefit by fusing those two forms of data for the purpose of semantic segmentation within the context of autonomous driving? We also attempt to show at which level does said fusion prove to be the most useful. We evaluated our algorithms on the publicly available SemanticKITTI dataset. All fusion models show improvements over the base model, with the mid-level fusion showing the highest improvement of 2.7% in terms of mean Intersection over Union (mIoU) metric.