 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Conditional Imitation Learning for Autonomous Driving
Nov 17, 2022

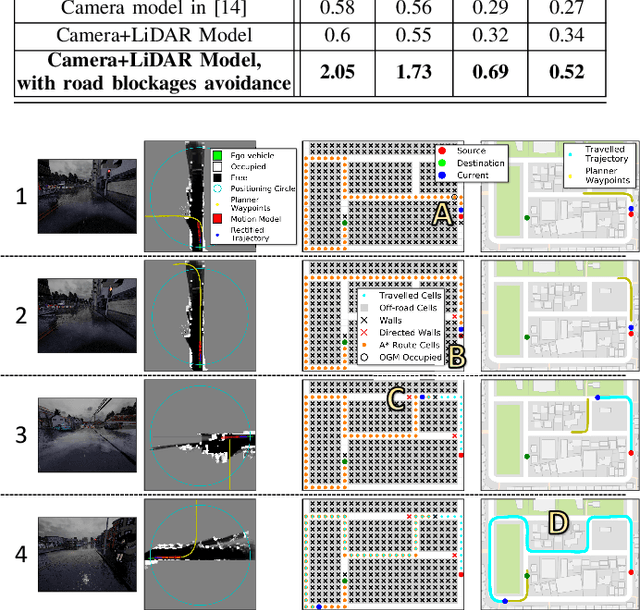

Conditional imitation learning (CIL) trains deep neural networks, in an end-to-end manner, to mimic human driving. This approach has demonstrated suitable vehicle control when following roads, avoiding obstacles, or taking specific turns at intersections to reach a destination. Unfortunately, performance dramatically decreases when deployed to unseen environments and is inconsistent against varying weather conditions. Most importantly, the current CIL fails to avoid static road blockages. In this work, we propose a solution to those deficiencies. First, we fuse the laser scanner with the regular camera streams, at the features level, to overcome the generalization and consistency challenges. Second, we introduce a new efficient Occupancy Grid Mapping (OGM) method along with new algorithms for road blockages avoidance and global route planning. Consequently, our proposed method dynamically detects partial and full road blockages, and guides the controlled vehicle to another route to reach the destination. Following the original CIL work, we demonstrated the effectiveness of our proposal on CARLA simulator urban driving benchmark. Our experiments showed that our model improved consistency against weather conditions by four times and autonomous driving success rate generalization by 52%. Furthermore, our global route planner improved the driving success rate by 37%. Our proposed road blockages avoidance algorithm improved the driving success rate by 27%. Finally, the average kilometers traveled before a collision with a static object increased by 1.5 times. The main source code can be reached at https://heshameraqi.github.io/dynamic_cil_autonomous_driving.
* 14 pages, 11 figures, 7 tables
An Evaluation of RGB and LiDAR Fusion for Semantic Segmentation
Aug 17, 2021
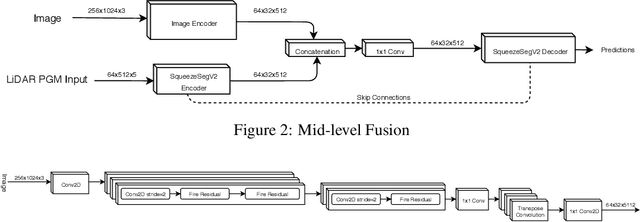
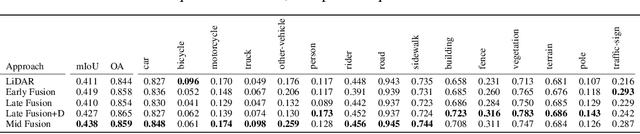
LiDARs and cameras are the two main sensors that are planned to be included in many announced autonomous vehicles prototypes. Each of the two provides a unique form of data from a different perspective to the surrounding environment. In this paper, we explore and attempt to answer the question: is there an added benefit by fusing those two forms of data for the purpose of semantic segmentation within the context of autonomous driving? We also attempt to show at which level does said fusion prove to be the most useful. We evaluated our algorithms on the publicly available SemanticKITTI dataset. All fusion models show improvements over the base model, with the mid-level fusion showing the highest improvement of 2.7% in terms of mean Intersection over Union (mIoU) metric.
Adversarial Unsupervised Domain Adaptation Guided with Deep Clustering for Face Presentation Attack Detection
Feb 13, 2021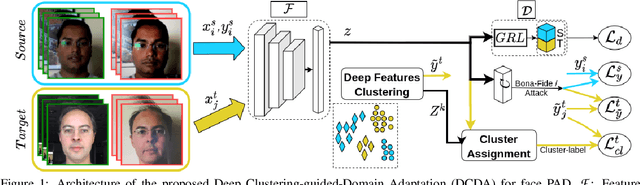
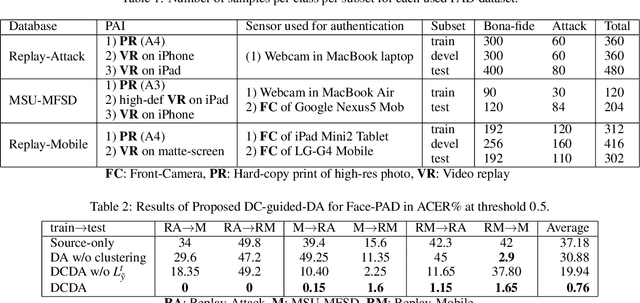
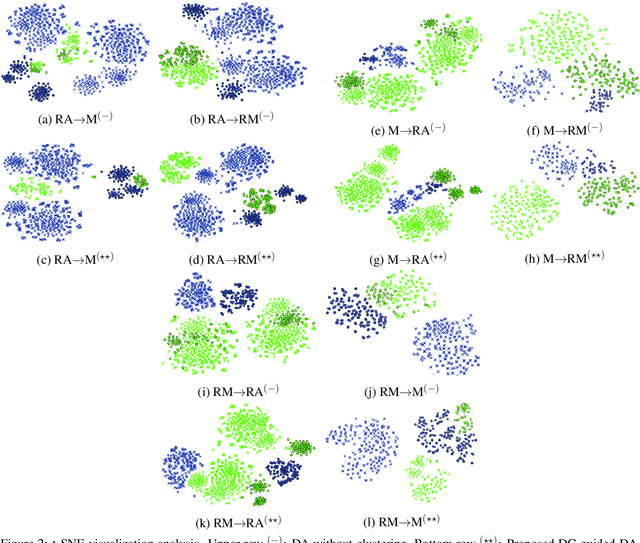
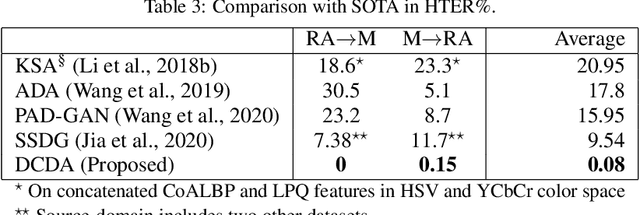
Face Presentation Attack Detection (PAD) has drawn increasing attentions to secure the face recognition systems that are widely used in many applications. Conventional face anti-spoofing methods have been proposed, assuming that testing is from the same domain used for training, and so cannot generalize well on unseen attack scenarios. The trained models tend to overfit to the acquisition sensors and attack types available in the training data. In light of this, we propose an end-to-end learning framework based on Domain Adaptation (DA) to improve PAD generalization capability. Labeled source-domain samples are used to train the feature extractor and classifier via cross-entropy loss, while unsupervised data from the target domain are utilized in adversarial DA approach causing the model to learn domain-invariant features. Using DA alone in face PAD fails to adapt well to target domain that is acquired in different conditions with different devices and attack types than the source domain. And so, in order to keep the intrinsic properties of the target domain, deep clustering of target samples is performed. Training and deep clustering are performed end-to-end, and experiments performed on several public benchmark datasets validate that our proposed Deep Clustering guided Unsupervised Domain Adaptation (DCDA) can learn more generalized information compared with the state-of-the-art classification error on the target domain.
Deep convolutional neural networks for face and iris presentation attack detection: Survey and case study
Apr 29, 2020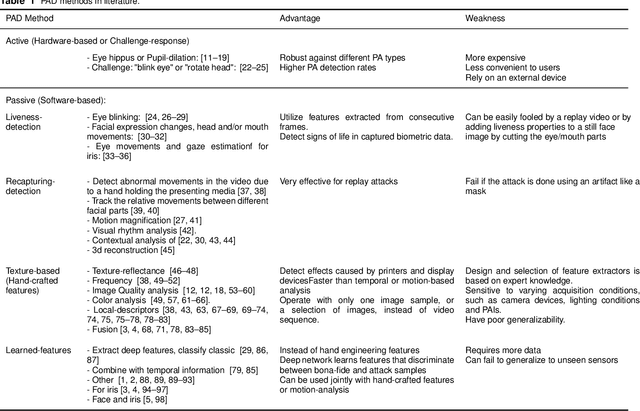

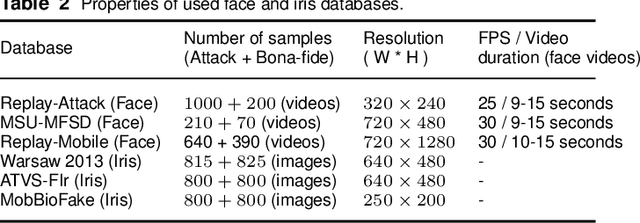

Biometric presentation attack detection is gaining increasing attention. Users of mobile devices find it more convenient to unlock their smart applications with finger, face or iris recognition instead of passwords. In this paper, we survey the approaches presented in the recent literature to detect face and iris presentation attacks. Specifically, we investigate the effectiveness of fine tuning very deep convolutional neural networks to the task of face and iris antispoofing. We compare two different fine tuning approaches on six publicly available benchmark datasets. Results show the effectiveness of these deep models in learning discriminative features that can tell apart real from fake biometric images with very low error rate. Cross-dataset evaluation on face PAD showed better generalization than state of the art. We also performed cross-dataset testing on iris PAD datasets in terms of equal error rate which was not reported in literature before. Additionally, we propose the use of a single deep network trained to detect both face and iris attacks. We have not noticed accuracy degradation compared to networks trained for only one biometric separately. Finally, we analyzed the learned features by the network, in correlation with the image frequency components, to justify its prediction decision.
Driver Distraction Identification with an Ensemble of Convolutional Neural Networks
Jan 22, 2019
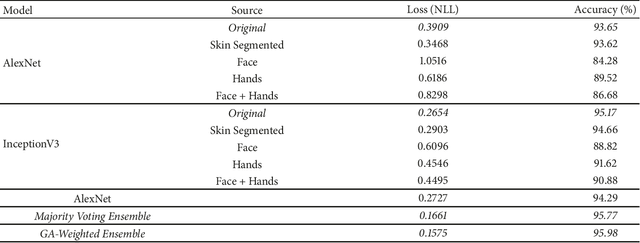

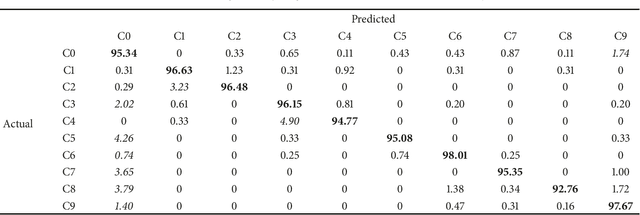
The World Health Organization (WHO) reported 1.25 million deaths yearly due to road traffic accidents worldwide and the number has been continuously increasing over the last few years. Nearly fifth of these accidents are caused by distracted drivers. Existing work of distracted driver detection is concerned with a small set of distractions (mostly, cell phone usage). Unreliable ad-hoc methods are often used.In this paper, we present the first publicly available dataset for driver distraction identification with more distraction postures than existing alternatives. In addition, we propose a reliable deep learning-based solution that achieves a 90% accuracy. The system consists of a genetically-weighted ensemble of convolutional neural networks, we show that a weighted ensemble of classifiers using a genetic algorithm yields in a better classification confidence. We also study the effect of different visual elements in distraction detection by means of face and hand localizations, and skin segmentation. Finally, we present a thinned version of our ensemble that could achieve 84.64% classification accuracy and operate in a real-time environment.
* arXiv admin note: substantial text overlap with arXiv:1706.09498
End-to-End Deep Learning for Steering Autonomous Vehicles Considering Temporal Dependencies
Nov 22, 2017
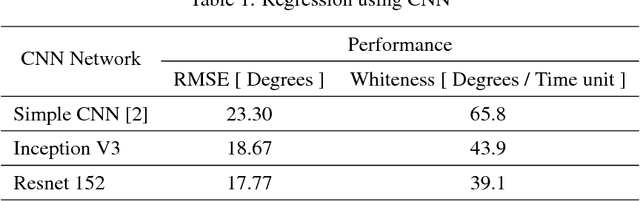


Steering a car through traffic is a complex task that is difficult to cast into algorithms. Therefore, researchers turn to training artificial neural networks from front-facing camera data stream along with the associated steering angles. Nevertheless, most existing solutions consider only the visual camera frames as input, thus ignoring the temporal relationship between frames. In this work, we propose a Convolutional Long Short-Term Memory Recurrent Neural Network (C-LSTM), that is end-to-end trainable, to learn both visual and dynamic temporal dependencies of driving. Additionally, We introduce posing the steering angle regression problem as classification while imposing a spatial relationship between the output layer neurons. Such method is based on learning a sinusoidal function that encodes steering angles. To train and validate our proposed methods, we used the publicly available Comma.ai dataset. Our solution improved steering root mean square error by 35% over recent methods, and led to a more stable steering by 87%.
Real-time Distracted Driver Posture Classification
Oct 21, 2017

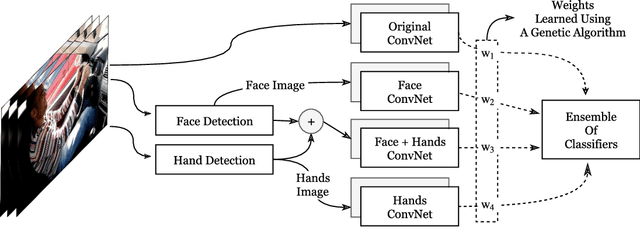

Distracted driving is a worldwide problem leading to an astoundingly increasing number of accidents and deaths. Existing work is concerned with a very small set of distractions (mostly, cell phone usage). Also, for the most part, it uses unreliable ad-hoc methods to detect those distractions. In this paper, we present the first publicly available dataset for "distracted driver" posture estimation with more distraction postures than existing alternatives. In addition, we propose a reliable system that achieves a 95.98% driving posture classification accuracy. The system consists of a genetically-weighted ensemble of Convolutional Neural Networks (CNNs). We show that a weighted ensemble of classifiers using a genetic algorithm yields in better classification confidence. We also study the effect of different visual elements (i.e. hands and face) in distraction detection by means of face and hand localizations. Finally, we present a thinned version of our ensemble that could achieve a 94.29% classification accuracy and operate in a real-time environment.