Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASMDD: Arabic Speech Mispronunciation Detection Dataset
Nov 01, 2021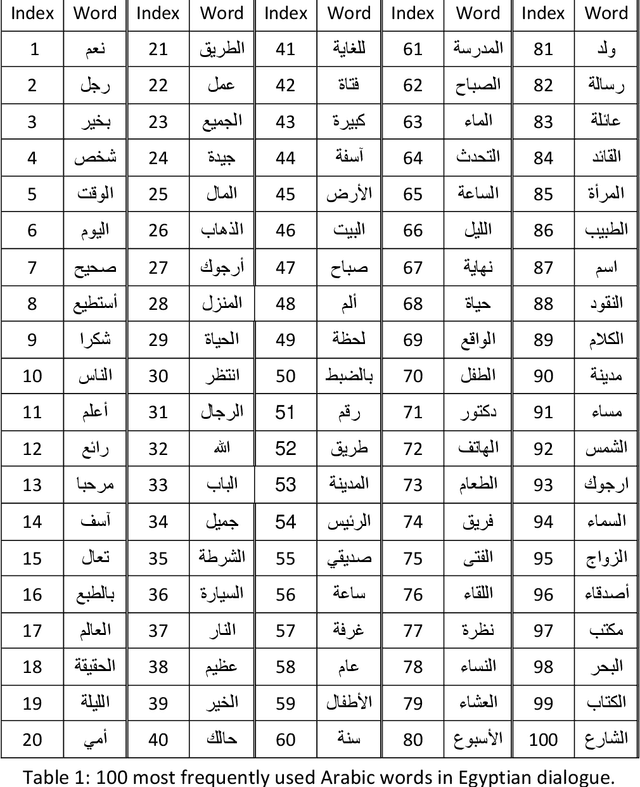
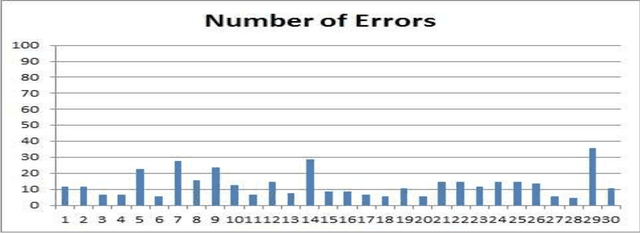
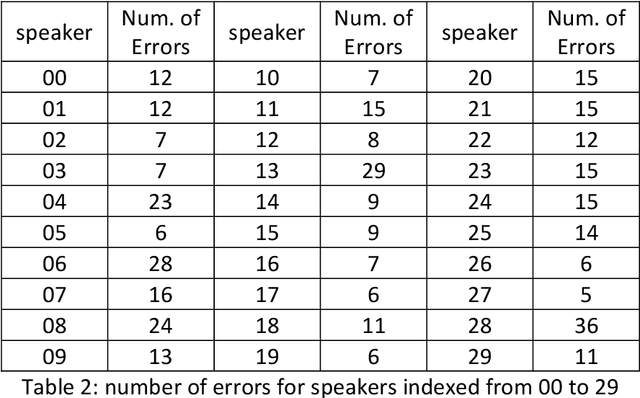

The largest dataset of Arabic speech mispronunciation detections in Egyptian dialogues is introduced. The dataset is composed of annotated audio files representing the top 100 words that are most frequently used in the Arabic language, pronounced by 100 Egyptian children (aged between 2 and 8 years old). The dataset is collected and annotated on segmental pronunciation error detections by expert listeners.
* 3 pages, 2 tables, 2 figures, dataset link:
https://drive.google.com/drive/folders/1dhlp-L0n6_RAzoosVK4bRa7hxBnzebqs
Via