 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal Attention Mechanism and Knowledge Distillation for Lip Reading
Aug 07, 2021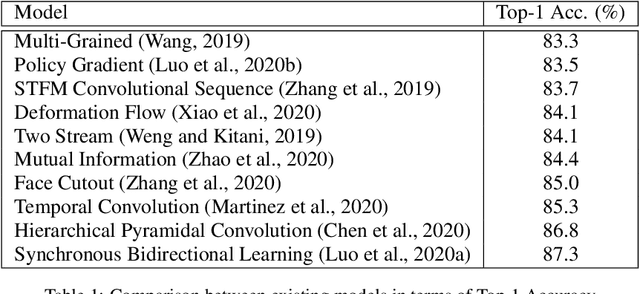

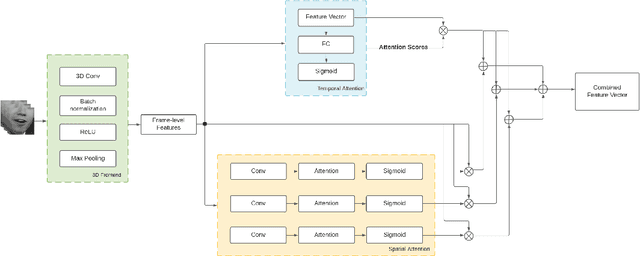

Despite the advancement in the domain of audio and audio-visual speech recognition, visual speech recognition systems are still quite under-explored due to the visual ambiguity of some phonemes. In this work, we propose a new lip-reading model that combines three contributions. First, the model front-end adopts a spatio-temporal attention mechanism to help extract the informative data from the input visual frames. Second, the model back-end utilizes a sequence-level and frame-level Knowledge Distillation (KD) techniques that allow leveraging audio data during the visual model training. Third, a data preprocessing pipeline is adopted that includes facial landmarks detection-based lip-alignment. On LRW lip-reading dataset benchmark, a noticeable accuracy improvement is demonstrated; the spatio-temporal attention, Knowledge Distillation, and lip-alignment contributions achieved 88.43%, 88.64%, and 88.37% respectively.