 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on GAN Acceleration Using Memory Compression Technique
Aug 14, 2021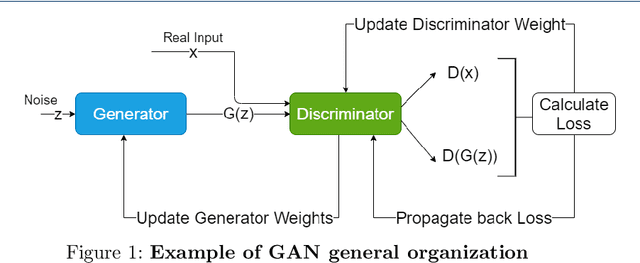
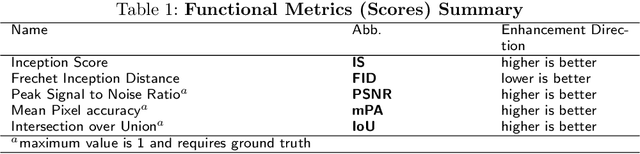
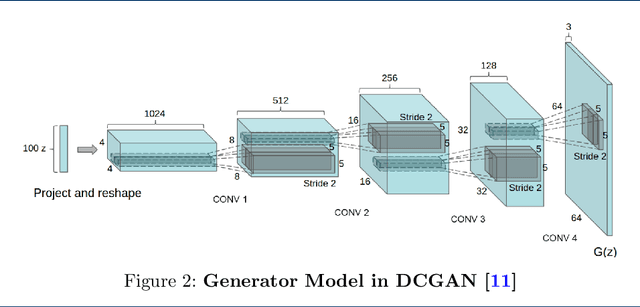

Since its invention, Generative adversarial networks (GANs) have shown outstanding results in many applications. Generative Adversarial Networks are powerful yet, resource-hungry deep-learning models. Their main difference from ordinary deep learning models is the nature of their output. For example, GAN output can be a whole image versus other models detecting objects or classifying images. Thus, the architecture and numeric precision of the network affect the quality and speed of the solution. Hence, accelerating GANs is pivotal. Accelerating GANs can be classified into three main tracks: (1) Memory compression, (2) Computation optimization, and (3) Data-flow optimization. Because data transfer is the main source of energy usage, memory compression leads to the most savings. Thus, in this paper, we survey memory compression techniques for CNN-Based GANs. Additionally, the paper summarizes opportunities and challenges in GANs acceleration and suggests open research problems to be further investigated.
FORECASTER: A Continual Lifelong Learning Approach to Improve Hardware Efficiency
Apr 27, 2020
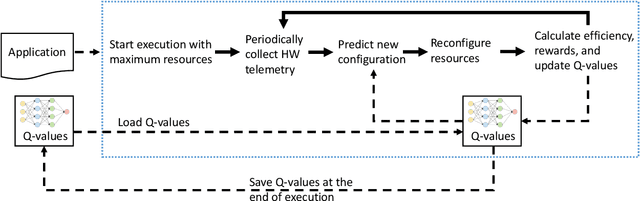
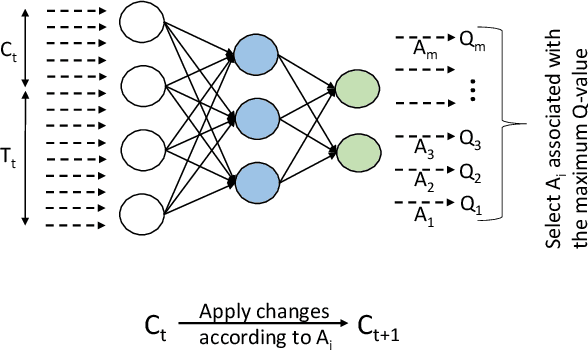
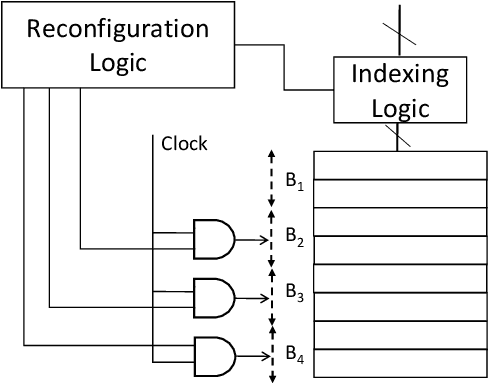
Computer applications are continuously evolving. However, significant knowledge can be harvested from older applications or versions and applied in the context of newer applications or versions. Such a vision can be realized with Continual Lifelong Learning. Therefore, we propose to employ continual lifelong learning to dynamically tune hardware configurations based on application behavior. The goal of such tuning is to maximize hardware efficiency (i.e., maximize an application performance while minimizing the hardware energy consumption). Our proposed approach, FORECASTER, uses deep reinforcement learning to continually learn during the execution of an application as well as propagate and utilize the accumulated knowledge during subsequent executions of the same or new application. We propose a novel hardware and ISA support to implement deep reinforcement learning. We implement FORECASTER and compare its performance against prior learning-based hardware reconfiguration approaches. Our results show that FORECASTER can save an average 16% of system power over the baseline setup with full usage of hardware while sacrificing an average of 4.7% of execution time.
Unsupervised Neural Sensor Models for Synthetic LiDAR Data Augmentation
Nov 24, 2019

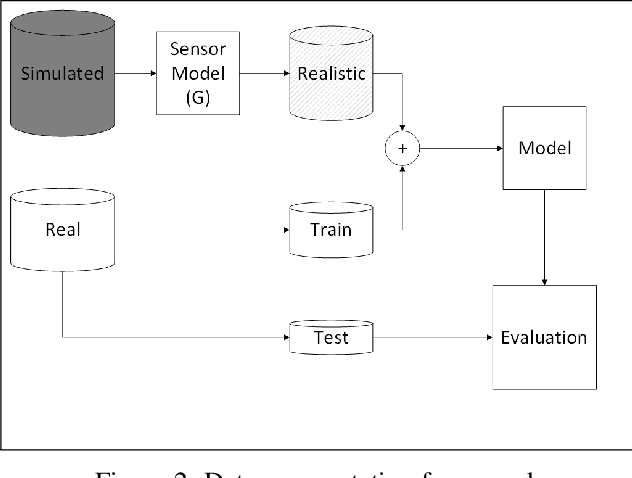

Data scarcity is a bottleneck to machine learning-based perception modules, usually tackled by augmenting real data with synthetic data from simulators. Realistic models of the vehicle perception sensors are hard to formulate in closed form, and at the same time, they require the existence of paired data to be learned. In this work, we propose two unsupervised neural sensor models based on unpaired domain translations with CycleGANs and Neural Style Transfer techniques. We employ CARLA as the simulation environment to obtain simulated LiDAR point clouds, together with their annotations for data augmentation, and we use KITTI dataset as the real LiDAR dataset from which we learn the realistic sensor model mapping. Moreover, we provide a framework for data augmentation and evaluation of the developed sensor models, through extrinsic object detection task evaluation using YOLO network adapted to provide oriented bounding boxes for LiDAR Bird-eye-View projected point clouds. Evaluation is performed on unseen real LiDAR frames from KITTI dataset, with different amounts of simulated data augmentation using the two proposed approaches, showing improvement of 6% mAP for the object detection task, in favor of the augmenting LiDAR point clouds adapted with the proposed neural sensor models over the raw simulated LiDAR.
End-to-end sensor modeling for LiDAR Point Cloud
Jul 17, 2019



Advanced sensors are a key to enable self-driving cars technology. Laser scanner sensors (LiDAR, Light Detection And Ranging) became a fundamental choice due to its long-range and robustness to low light driving conditions. The problem of designing a control software for self-driving cars is a complex task to explicitly formulate in rule-based systems, thus recent approaches rely on machine learning that can learn those rules from data. The major problem with such approaches is that the amount of training data required for generalizing a machine learning model is big, and on the other hand LiDAR data annotation is very costly compared to other car sensors. An accurate LiDAR sensor model can cope with such problem. Moreover, its value goes beyond this because existing LiDAR development, validation, and evaluation platforms and processes are very costly, and virtual testing and development environments are still immature in terms of physical properties representation. In this work we propose a novel Deep Learning-based LiDAR sensor model. This method models the sensor echos, using a Deep Neural Network to model echo pulse widths learned from real data using Polar Grid Maps (PGM). We benchmark our model performance against comprehensive real sensor data and very promising results are achieved that sets a baseline for future works.
LiDAR Sensor modeling and Data augmentation with GANs for Autonomous driving
May 17, 2019



In the autonomous driving domain, data collection and annotation from real vehicles are expensive and sometimes unsafe. Simulators are often used for data augmentation, which requires realistic sensor models that are hard to formulate and model in closed forms. Instead, sensors models can be learned from real data. The main challenge is the absence of paired data set, which makes traditional supervised learning techniques not suitable. In this work, we formulate the problem as image translation from unpaired data and employ CycleGANs to solve the sensor modeling problem for LiDAR, to produce realistic LiDAR from simulated LiDAR (sim2real). Further, we generate high-resolution, realistic LiDAR from lower resolution one (real2real). The LiDAR 3D point cloud is processed in Bird-eye View and Polar 2D representations. The experimental results show a high potential of the proposed approach.
YOLO3D: End-to-end real-time 3D Oriented Object Bounding Box Detection from LiDAR Point Cloud
Aug 07, 2018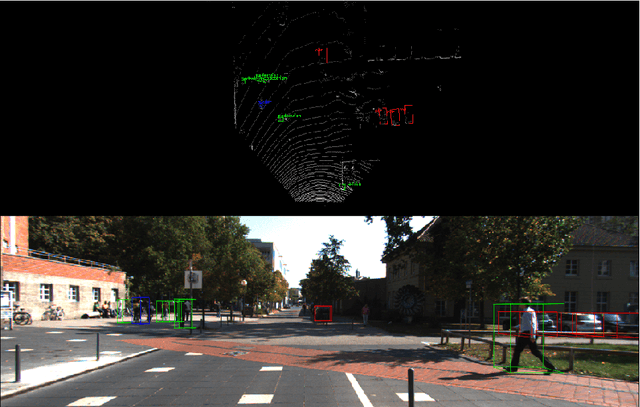
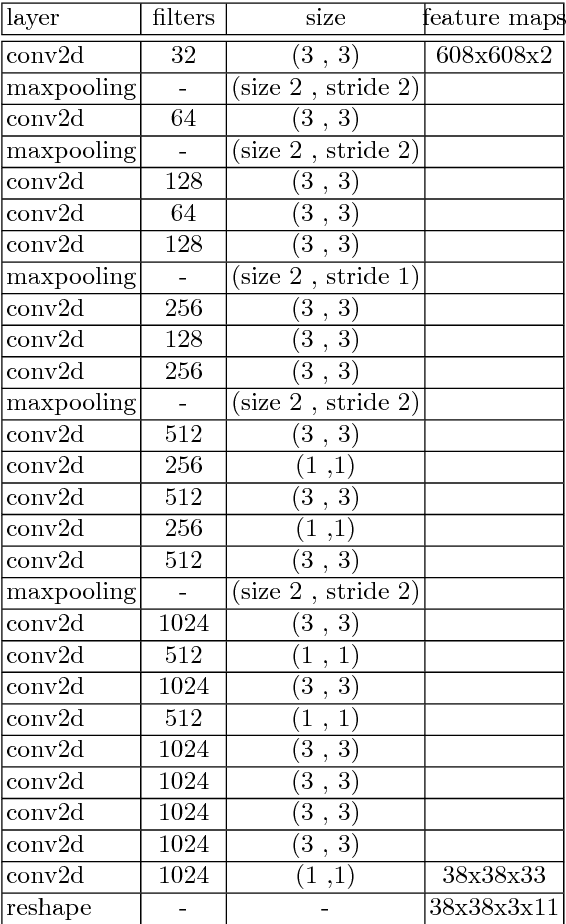

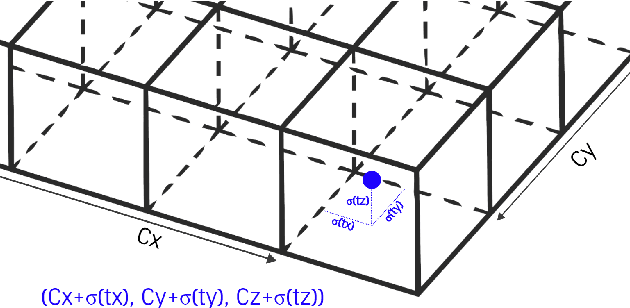
Object detection and classification in 3D is a key task in Automated Driving (AD). LiDAR sensors are employed to provide the 3D point cloud reconstruction of the surrounding environment, while the task of 3D object bounding box detection in real time remains a strong algorithmic challenge. In this paper, we build on the success of the one-shot regression meta-architecture in the 2D perspective image space and extend it to generate oriented 3D object bounding boxes from LiDAR point cloud. Our main contribution is in extending the loss function of YOLO v2 to include the yaw angle, the 3D box center in Cartesian coordinates and the height of the box as a direct regression problem. This formulation enables real-time performance, which is essential for automated driving. Our results are showing promising figures on KITTI benchmark, achieving real-time performance (40 fps) on Titan X GPU.
MODNet: Moving Object Detection Network with Motion and Appearance for Autonomous Driving
Nov 12, 2017
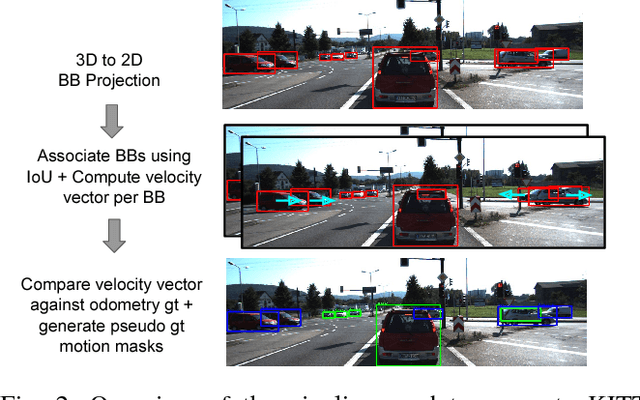
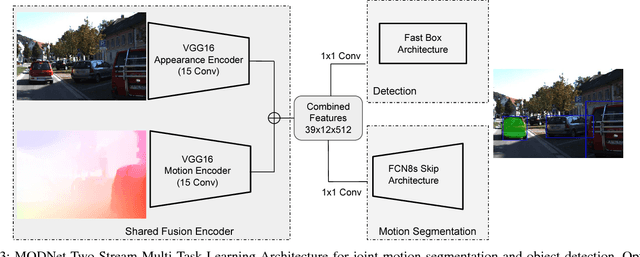
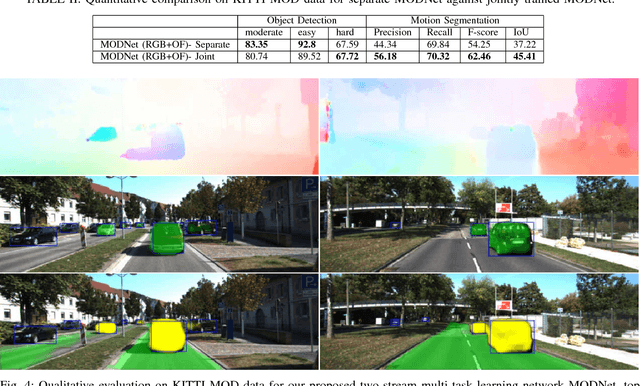
We propose a novel multi-task learning system that combines appearance and motion cues for a better semantic reasoning of the environment. A unified architecture for joint vehicle detection and motion segmentation is introduced. In this architecture, a two-stream encoder is shared among both tasks. In order to evaluate our method in autonomous driving setting, KITTI annotated sequences with detection and odometry ground truth are used to automatically generate static/dynamic annotations on the vehicles. This dataset is called KITTI Moving Object Detection dataset (KITTI MOD). The dataset will be made publicly available to act as a benchmark for the motion detection task. Our experiments show that the proposed method outperforms state of the art methods that utilize motion cue only with 21.5% in mAP on KITTI MOD. Our method performs on par with the state of the art unsupervised methods on DAVIS benchmark for generic object segmentation. One of our interesting conclusions is that joint training of motion segmentation and vehicle detection benefits motion segmentation. Motion segmentation has relatively fewer data, unlike the detection task. However, the shared fusion encoder benefits from joint training to learn a generalized representation. The proposed method runs in 120 ms per frame, which beats the state of the art motion detection/segmentation in computational efficiency.