 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeST-DETR: Spatio-Temporal Object Traces Attention Detection Transformer
Jul 24, 2021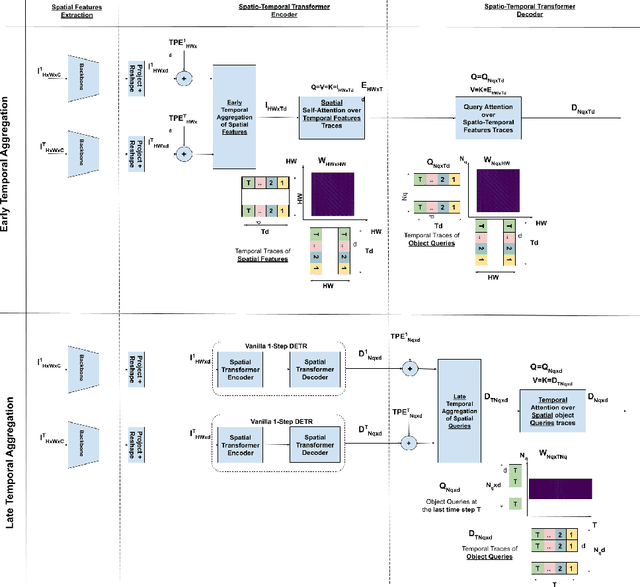


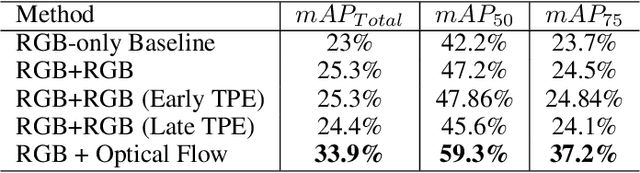
We propose ST-DETR, a Spatio-Temporal Transformer-based architecture for object detection from a sequence of temporal frames. We treat the temporal frames as sequences in both space and time and employ the full attention mechanisms to take advantage of the features correlations over both dimensions. This treatment enables us to deal with frames sequence as temporal object features traces over every location in the space. We explore two possible approaches; the early spatial features aggregation over the temporal dimension, and the late temporal aggregation of object query spatial features. Moreover, we propose a novel Temporal Positional Embedding technique to encode the time sequence information. To evaluate our approach, we choose the Moving Object Detection (MOD)task, since it is a perfect candidate to showcase the importance of the temporal dimension. Results show a significant 5% mAP improvement on the KITTI MOD dataset over the 1-step spatial baseline.
MODETR: Moving Object Detection with Transformers
Jun 21, 2021

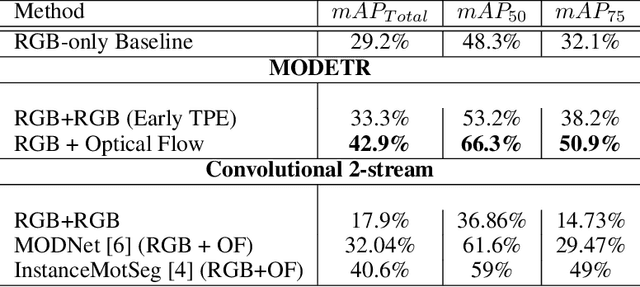
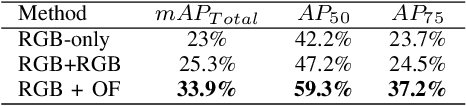
Moving Object Detection (MOD) is a crucial task for the Autonomous Driving pipeline. MOD is usually handled via 2-stream convolutional architectures that incorporates both appearance and motion cues, without considering the inter-relations between the spatial or motion features. In this paper, we tackle this problem through multi-head attention mechanisms, both across the spatial and motion streams. We propose MODETR; a Moving Object DEtection TRansformer network, comprised of multi-stream transformer encoders for both spatial and motion modalities, and an object transformer decoder that produces the moving objects bounding boxes using set predictions. The whole architecture is trained end-to-end using bi-partite loss. Several methods of incorporating motion cues with the Transformer model are explored, including two-stream RGB and Optical Flow (OF) methods, and multi-stream architectures that take advantage of sequence information. To incorporate the temporal information, we propose a new Temporal Positional Encoding (TPE) approach to extend the Spatial Positional Encoding(SPE) in DETR. We explore two architectural choices for that, balancing between speed and time. To evaluate the our network, we perform the MOD task on the KITTI MOD [6] data set. Results show significant 5% mAP of the Transformer network for MOD over the state-of-the art methods. Moreover, the proposed TPE encoding provides 10% mAP improvement over the SPE baseline.
INSTA-YOLO: Real-Time Instance Segmentation
Feb 12, 2021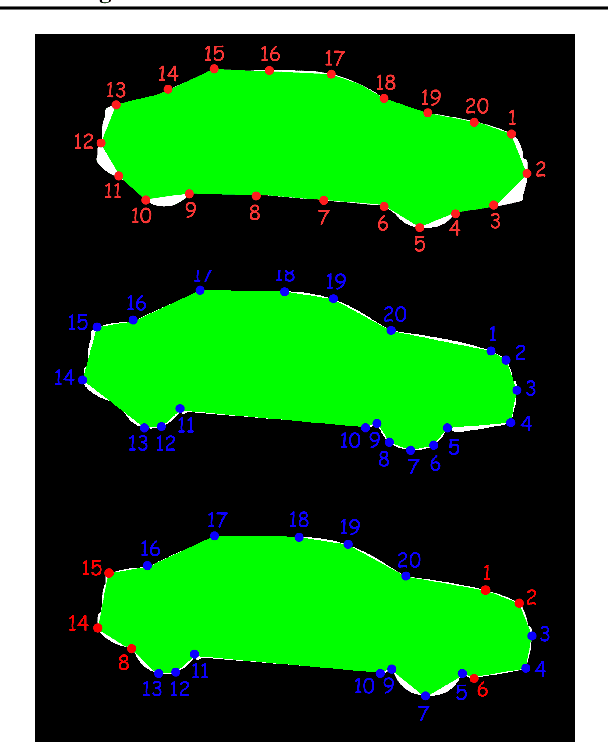
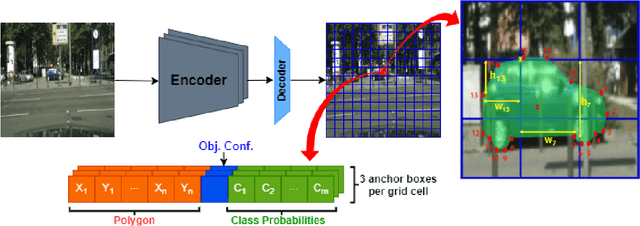
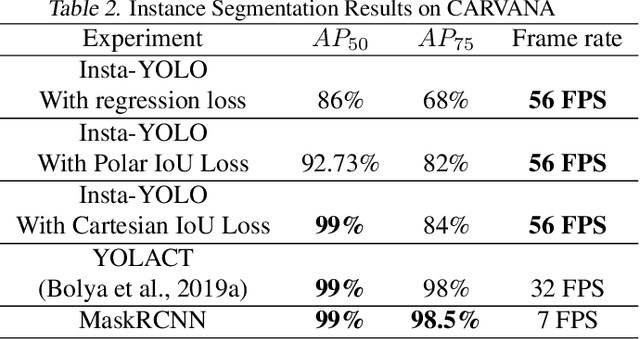

Instance segmentation has gained recently huge attention in various computer vision applications. It aims at providing different IDs to different objects of the scene, even if they belong to the same class. Instance segmentation is usually performed as a two-stage pipeline. First, an object is detected, then semantic segmentation within the detected box area is performed which involves costly up-sampling. In this paper, we propose Insta-YOLO, a novel one-stage end-to-end deep learning model for real-time instance segmentation. Instead of pixel-wise prediction, our model predicts instances as object contours represented by 2D points in Cartesian space. We evaluate our model on three datasets, namely, Carvana,Cityscapes and Airbus. We compare our results to the state-of-the-art models for instance segmentation. The results show our model achieves competitive accuracy in terms of mAP at twice the speed on GTX-1080 GPU.
Generalized Object Detection on Fisheye Cameras for Autonomous Driving: Dataset, Representations and Baseline
Dec 03, 2020
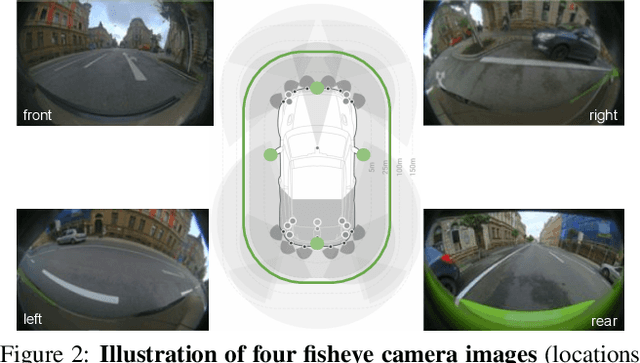
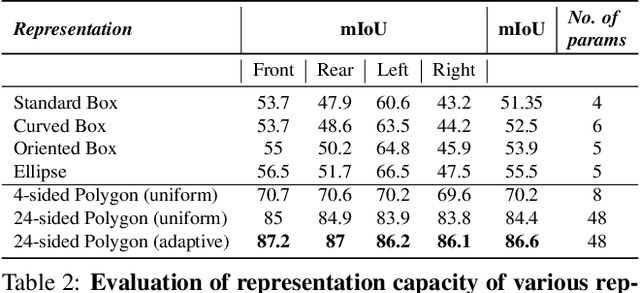
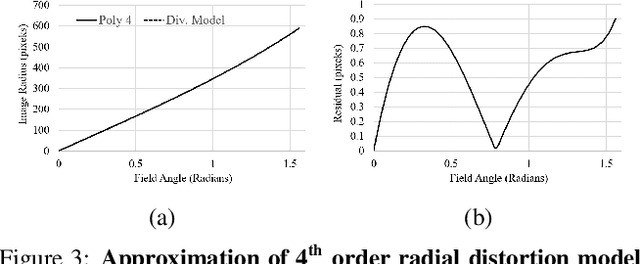
Object detection is a comprehensively studied problem in autonomous driving. However, it has been relatively less explored in the case of fisheye cameras. The standard bounding box fails in fisheye cameras due to the strong radial distortion, particularly in the image's periphery. We explore better representations like oriented bounding box, ellipse, and generic polygon for object detection in fisheye images in this work. We use the IoU metric to compare these representations using accurate instance segmentation ground truth. We design a novel curved bounding box model that has optimal properties for fisheye distortion models. We also design a curvature adaptive perimeter sampling method for obtaining polygon vertices, improving relative mAP score by 4.9% compared to uniform sampling. Overall, the proposed polygon model improves mIoU relative accuracy by 40.3%. It is the first detailed study on object detection on fisheye cameras for autonomous driving scenarios to the best of our knowledge. The dataset comprising of 10,000 images along with all the object representations ground truth will be made public to encourage further research. We summarize our work in a short video with qualitative results at https://youtu.be/iLkOzvJpL-A.
InstanceMotSeg: Real-time Instance Motion Segmentation for Autonomous Driving
Aug 16, 2020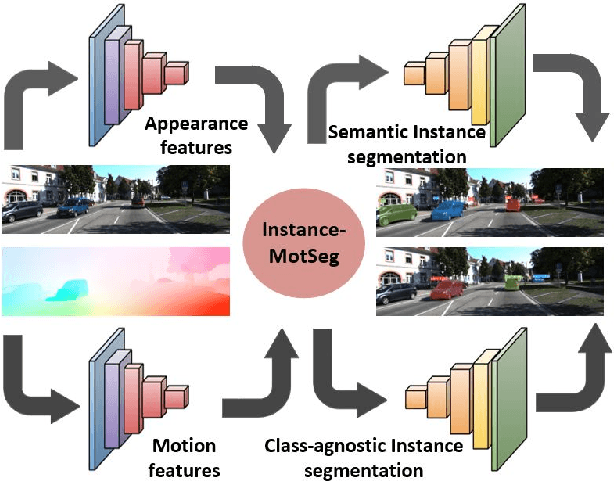
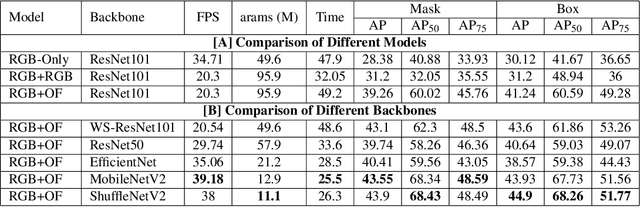
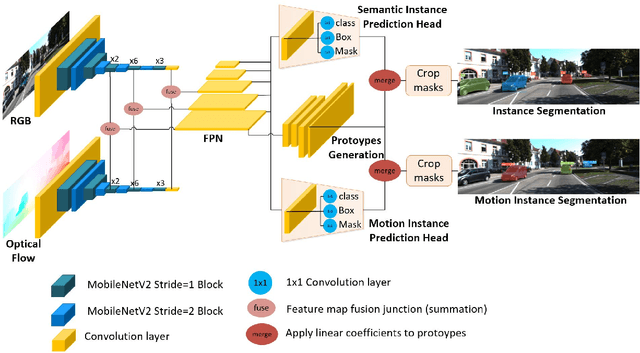
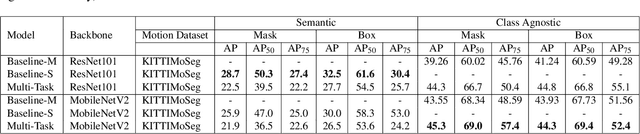
Moving object segmentation is a crucial task for autonomous vehicles as it can be used to segment objects in a class agnostic manner based on its motion cues. It will enable the detection of objects unseen during training (e.g., moose or a construction truck) generically based on their motion. Although pixel-wise motion segmentation has been studied in the literature, it is not dealt with at instance level, which would help separate connected segments of moving objects leading to better trajectory planning. In this paper, we proposed a motion-based instance segmentation task and created a new annotated dataset based on KITTI, which will be released publicly. We make use of the YOLACT model to solve the instance motion segmentation network by feeding inflow and image as input and instance motion masks as output. We extend it to a multi-task model that learns semantic and motion instance segmentation in a computationally efficient manner. Our model is based on sharing a prototype generation network between the two tasks and learning separate prototype coefficients per task. To obtain real-time performance, we study different efficient encoders and obtain 39 fps on a Titan Xp GPU using MobileNetV2 with an improvement of 10% mAP relative to the baseline. A video demonstration of our work is available in https://youtu.be/CWGZibugD9g.
Exploring applications of deep reinforcement learning for real-world autonomous driving systems
Jan 16, 2019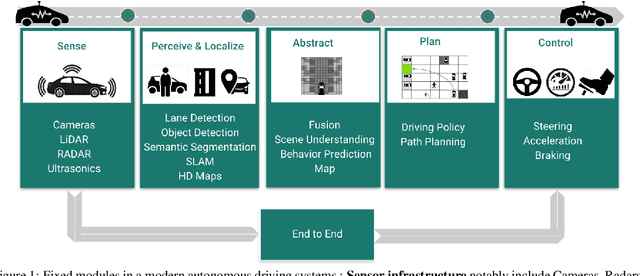
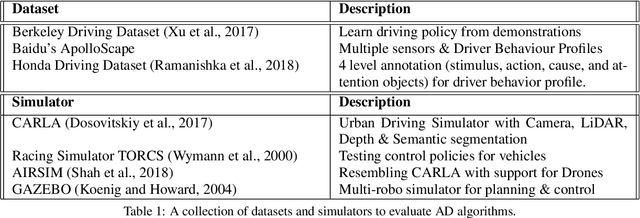
Deep Reinforcement Learning (DRL) has become increasingly powerful in recent years, with notable achievements such as Deepmind's AlphaGo. It has been successfully deployed in commercial vehicles like Mobileye's path planning system. However, a vast majority of work on DRL is focused on toy examples in controlled synthetic car simulator environments such as TORCS and CARLA. In general, DRL is still at its infancy in terms of usability in real-world applications. Our goal in this paper is to encourage real-world deployment of DRL in various autonomous driving (AD) applications. We first provide an overview of the tasks in autonomous driving systems, reinforcement learning algorithms and applications of DRL to AD systems. We then discuss the challenges which must be addressed to enable further progress towards real-world deployment.
Optical Flow augmented Semantic Segmentation networks for Automated Driving
Jan 11, 2019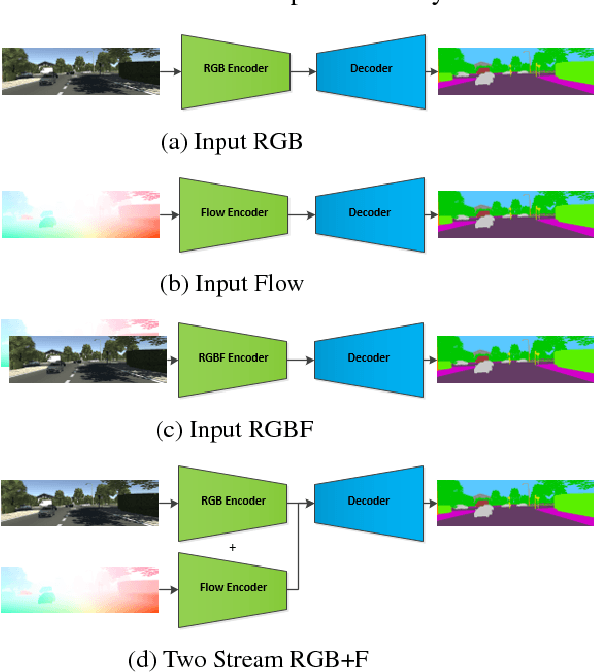
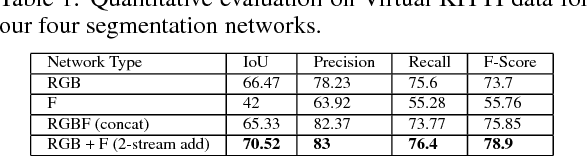
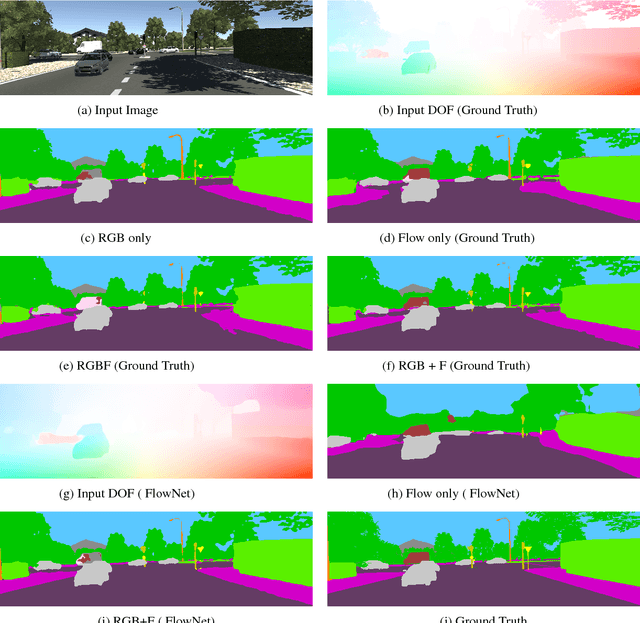

Motion is a dominant cue in automated driving systems. Optical flow is typically computed to detect moving objects and to estimate depth using triangulation. In this paper, our motivation is to leverage the existing dense optical flow to improve the performance of semantic segmentation. To provide a systematic study, we construct four different architectures which use RGB only, flow only, RGBF concatenated and two-stream RGB + flow. We evaluate these networks on two automotive datasets namely Virtual KITTI and Cityscapes using the state-of-the-art flow estimator FlowNet v2. We also make use of the ground truth optical flow in Virtual KITTI to serve as an ideal estimator and a standard Farneback optical flow algorithm to study the effect of noise. Using the flow ground truth in Virtual KITTI, two-stream architecture achieves the best results with an improvement of 4% IoU. As expected, there is a large improvement for moving objects like trucks, vans and cars with 38%, 28% and 6% increase in IoU. FlowNet produces an improvement of 2.4% in average IoU with larger improvement in the moving objects corresponding to 26%, 11% and 5% in trucks, vans and cars. In Cityscapes, flow augmentation provided an improvement for moving objects like motorcycle and train with an increase of 17% and 7% in IoU.
MODNet: Moving Object Detection Network with Motion and Appearance for Autonomous Driving
Nov 12, 2017
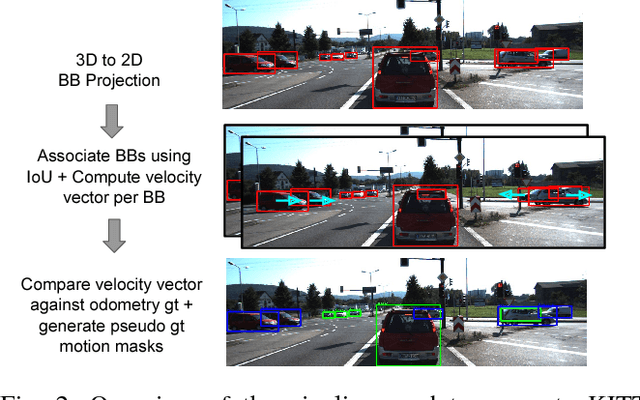
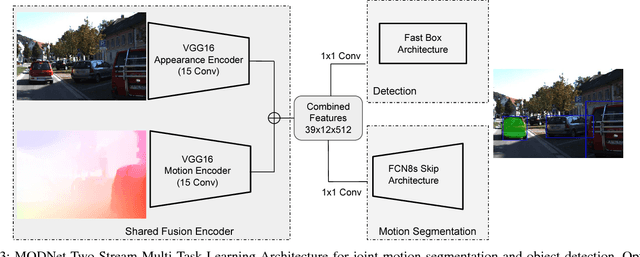
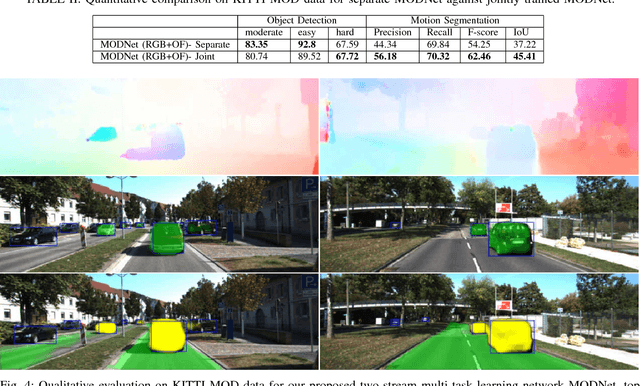
We propose a novel multi-task learning system that combines appearance and motion cues for a better semantic reasoning of the environment. A unified architecture for joint vehicle detection and motion segmentation is introduced. In this architecture, a two-stream encoder is shared among both tasks. In order to evaluate our method in autonomous driving setting, KITTI annotated sequences with detection and odometry ground truth are used to automatically generate static/dynamic annotations on the vehicles. This dataset is called KITTI Moving Object Detection dataset (KITTI MOD). The dataset will be made publicly available to act as a benchmark for the motion detection task. Our experiments show that the proposed method outperforms state of the art methods that utilize motion cue only with 21.5% in mAP on KITTI MOD. Our method performs on par with the state of the art unsupervised methods on DAVIS benchmark for generic object segmentation. One of our interesting conclusions is that joint training of motion segmentation and vehicle detection benefits motion segmentation. Motion segmentation has relatively fewer data, unlike the detection task. However, the shared fusion encoder benefits from joint training to learn a generalized representation. The proposed method runs in 120 ms per frame, which beats the state of the art motion detection/segmentation in computational efficiency.