 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMODNet: Moving Object Detection Network with Motion and Appearance for Autonomous Driving
Nov 12, 2017
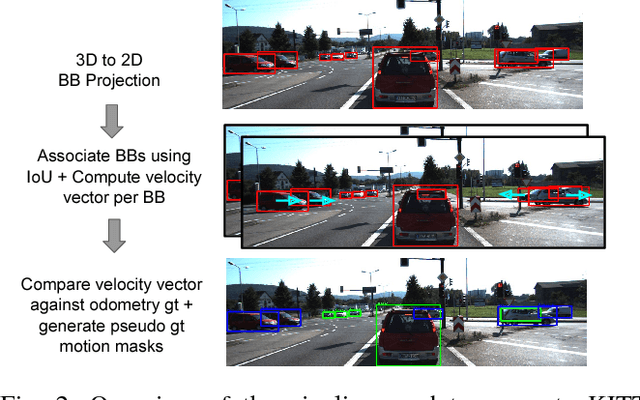
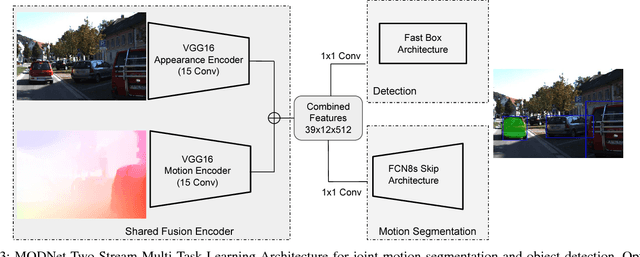
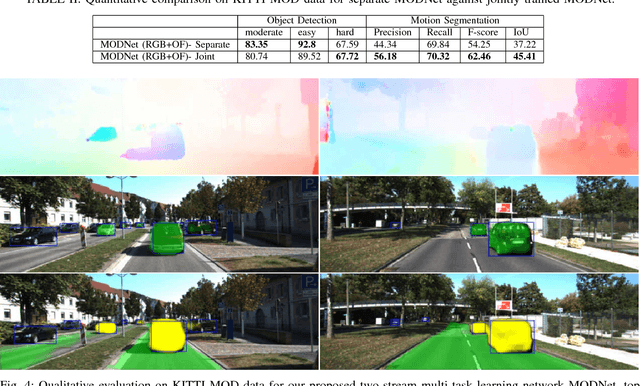
We propose a novel multi-task learning system that combines appearance and motion cues for a better semantic reasoning of the environment. A unified architecture for joint vehicle detection and motion segmentation is introduced. In this architecture, a two-stream encoder is shared among both tasks. In order to evaluate our method in autonomous driving setting, KITTI annotated sequences with detection and odometry ground truth are used to automatically generate static/dynamic annotations on the vehicles. This dataset is called KITTI Moving Object Detection dataset (KITTI MOD). The dataset will be made publicly available to act as a benchmark for the motion detection task. Our experiments show that the proposed method outperforms state of the art methods that utilize motion cue only with 21.5% in mAP on KITTI MOD. Our method performs on par with the state of the art unsupervised methods on DAVIS benchmark for generic object segmentation. One of our interesting conclusions is that joint training of motion segmentation and vehicle detection benefits motion segmentation. Motion segmentation has relatively fewer data, unlike the detection task. However, the shared fusion encoder benefits from joint training to learn a generalized representation. The proposed method runs in 120 ms per frame, which beats the state of the art motion detection/segmentation in computational efficiency.