 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiledSoilingNet: Tile-level Soiling Detection on Automotive Surround-view Cameras Using Coverage Metric
Jul 01, 2020
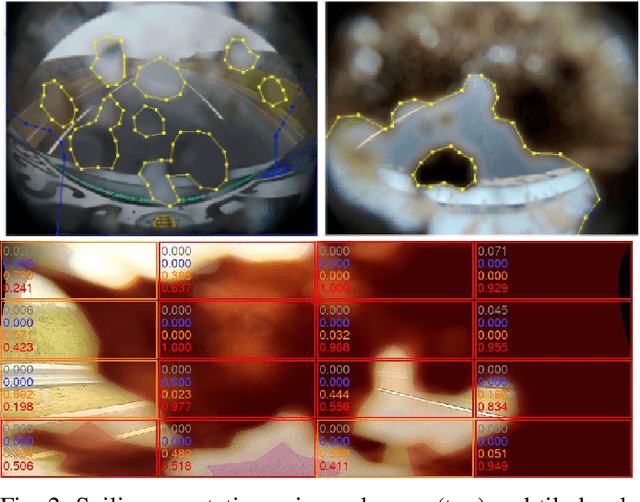
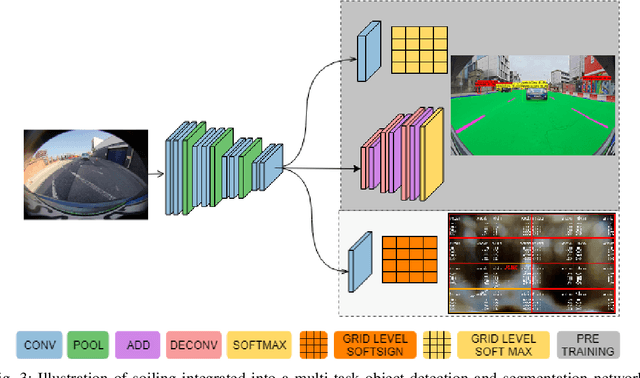
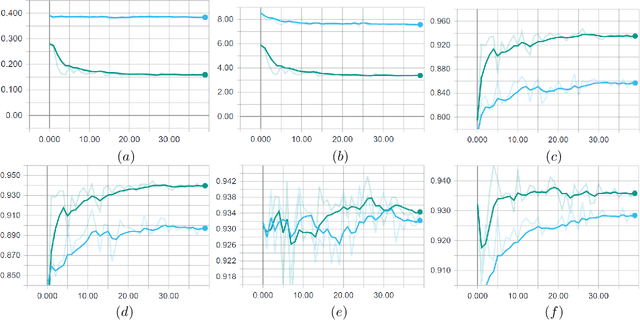
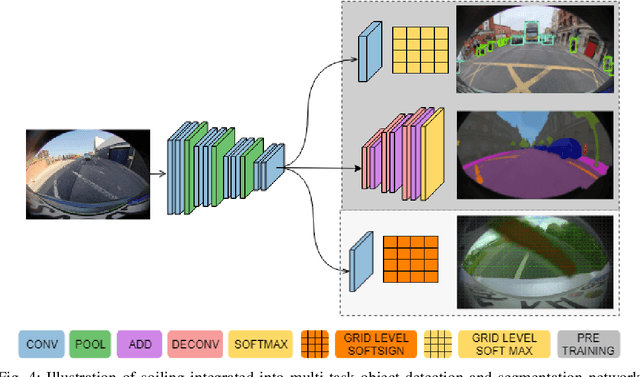
Automotive cameras, particularly surround-view cameras, tend to get soiled by mud, water, snow, etc. For higher levels of autonomous driving, it is necessary to have a soiling detection algorithm which will trigger an automatic cleaning system. Localized detection of soiling in an image is necessary to control the cleaning system. It is also necessary to enable partial functionality in unsoiled areas while reducing confidence in soiled areas. Although this can be solved using a semantic segmentation task, we explore a more efficient solution targeting deployment in low power embedded system. We propose a novel method to regress the area of each soiling type within a tile directly. We refer to this as coverage. The proposed approach is better than learning the dominant class in a tile as multiple soiling types occur within a tile commonly. It also has the advantage of dealing with coarse polygon annotation, which will cause the segmentation task. The proposed soiling coverage decoder is an order of magnitude faster than an equivalent segmentation decoder. We also integrated it into an object detection and semantic segmentation multi-task model using an asynchronous back-propagation algorithm. A portion of the dataset used will be released publicly as part of our WoodScape dataset to encourage further research.
Let's Get Dirty: GAN Based Data Augmentation for Soiling and Adverse Weather Classification in Autonomous Driving
Dec 04, 2019

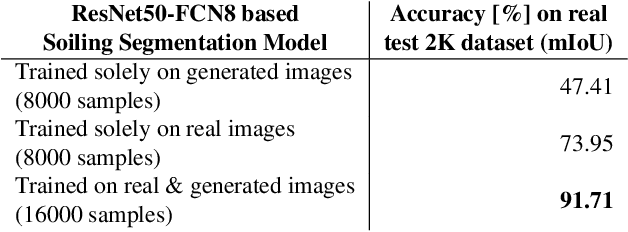

Cameras are getting more and more important in autonomous driving. Wide-angle fisheye cameras are relatively cheap sensors and very suitable for automated parking and low-speed navigation tasks. Four of such cameras form a surround-view system that provides a complete and detailed view around the vehicle. These cameras are usually directly exposed to harsh environmental settings and therefore can get soiled very easily by mud, dust, water, frost, etc. The soiling on the camera lens has a direct impact on the further processing of the images they provide. While adverse weather conditions, such as rain, are getting attention recently, there is limited work on lens soiling. We believe that one of the reasons is that it is difficult to build a diverse dataset for this task, which is moreover expensive to annotate. We propose a novel GAN based algorithm for generating artificial soiling data along with the corresponding annotation masks. The manually annotated soiling dataset and the generated augmentation dataset will be made public. We demonstrate the generalization of our fisheye trained soiling GAN model on the Cityscapes dataset. Additionally, we provide an empirical evaluation of the degradation of the semantic segmentation algorithm with the soiled data.
SoilingNet: Soiling Detection on Automotive Surround-View Cameras
May 04, 2019

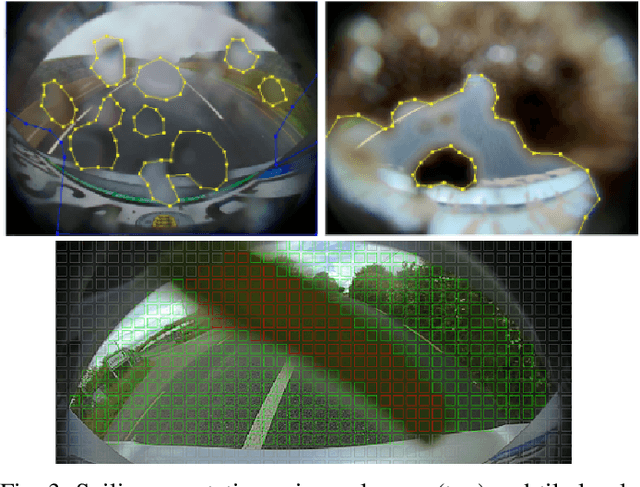
Cameras are an essential part of sensor suite in autonomous driving. Surround-view cameras are directly exposed to external environment and are vulnerable to get soiled. Cameras have a much higher degradation in performance due to soiling compared to other sensors. Thus it is critical to accurately detect soiling on the cameras, particularly for higher levels of autonomous driving. We created a new dataset having multiple types of soiling namely opaque and transparent. As there is no public dataset available for this task, we will release a public dataset to encourage further research. We demonstrate high accuracy using a Convolutional Neural Network (CNN) based architecture. We also show that it can be combined with the existing object detection task in a multi-task learning framework. Finally, we make use of Generative Adversarial Networks (GANs) to generate more images for data augmentation and show that it works successfully similar to the style transfer.
Yes, we GAN: Applying Adversarial Techniques for Autonomous Driving
Feb 09, 2019
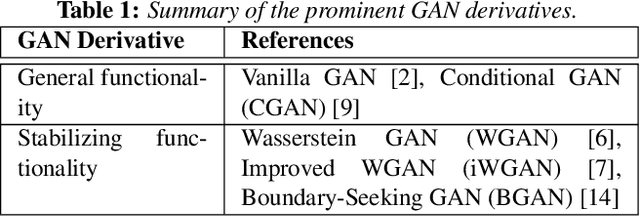
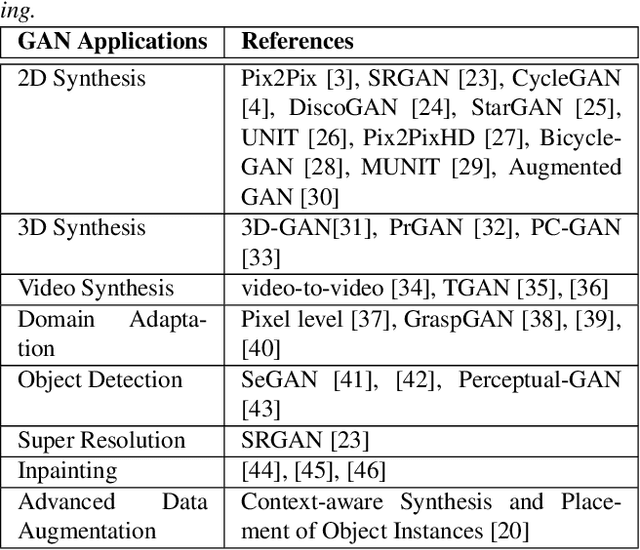
Generative Adversarial Networks (GAN) have gained a lot of popularity from their introduction in 2014 till present. Research on GAN is rapidly growing and there are many variants of the original GAN focusing on various aspects of deep learning. GAN are perceived as the most impactful direction of machine learning in the last decade. This paper focuses on the application of GAN in autonomous driving including topics such as advanced data augmentation, loss function learning, semi-supervised learning, etc. We formalize and review key applications of adversarial techniques and discuss challenges and open problems to be addressed.
Challenges in Designing Datasets and Validation for Autonomous Driving
Jan 26, 2019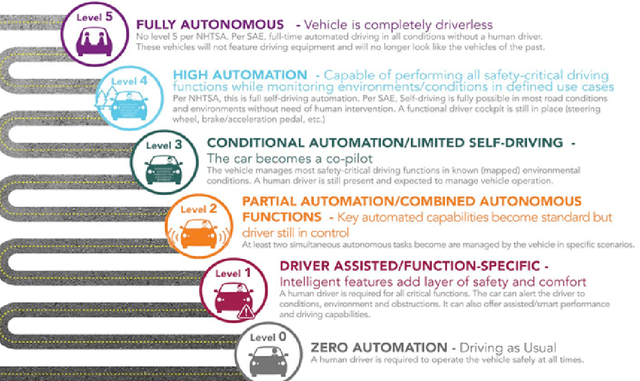

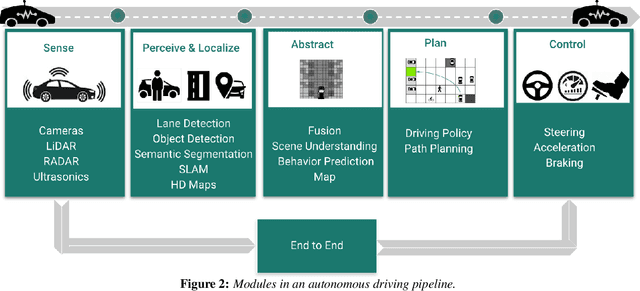
Autonomous driving is getting a lot of attention in the last decade and will be the hot topic at least until the first successful certification of a car with Level 5 autonomy. There are many public datasets in the academic community. However, they are far away from what a robust industrial production system needs. There is a large gap between academic and industrial setting and a substantial way from a research prototype, built on public datasets, to a deployable solution which is a challenging task. In this paper, we focus on bad practices that often happen in the autonomous driving from an industrial deployment perspective. Data design deserves at least the same amount of attention as the model design. There is very little attention paid to these issues in the scientific community, and we hope this paper encourages better formalization of dataset design. More specifically, we focus on the datasets design and validation scheme for autonomous driving, where we would like to highlight the common problems, wrong assumptions, and steps towards avoiding them, as well as some open problems.
Design of Real-time Semantic Segmentation Decoder for Automated Driving
Jan 19, 2019
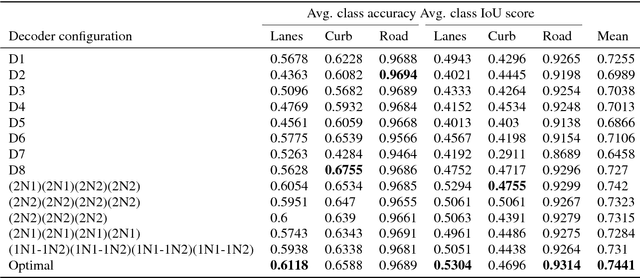


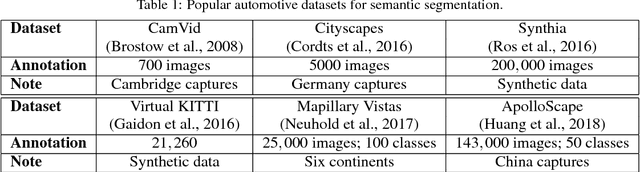
Semantic segmentation remains a computationally intensive algorithm for embedded deployment even with the rapid growth of computation power. Thus efficient network design is a critical aspect especially for applications like automated driving which requires real-time performance. Recently, there has been a lot of research on designing efficient encoders that are mostly task agnostic. Unlike image classification and bounding box object detection tasks, decoders are computationally expensive as well for semantic segmentation task. In this work, we focus on efficient design of the segmentation decoder and assume that an efficient encoder is already designed to provide shared features for a multi-task learning system. We design a novel efficient non-bottleneck layer and a family of decoders which fit into a small run-time budget using VGG10 as efficient encoder. We demonstrate in our dataset that experimentation with various design choices led to an improvement of 10\% from a baseline performance.
Optical Flow augmented Semantic Segmentation networks for Automated Driving
Jan 11, 2019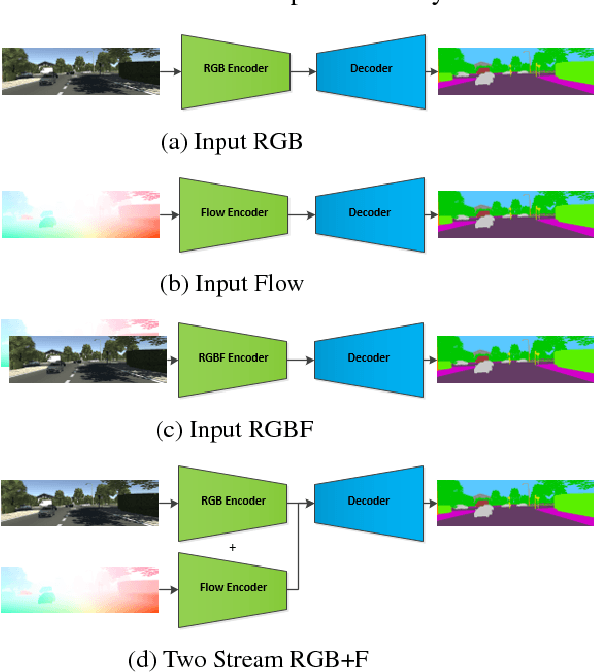
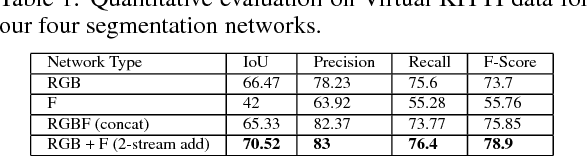
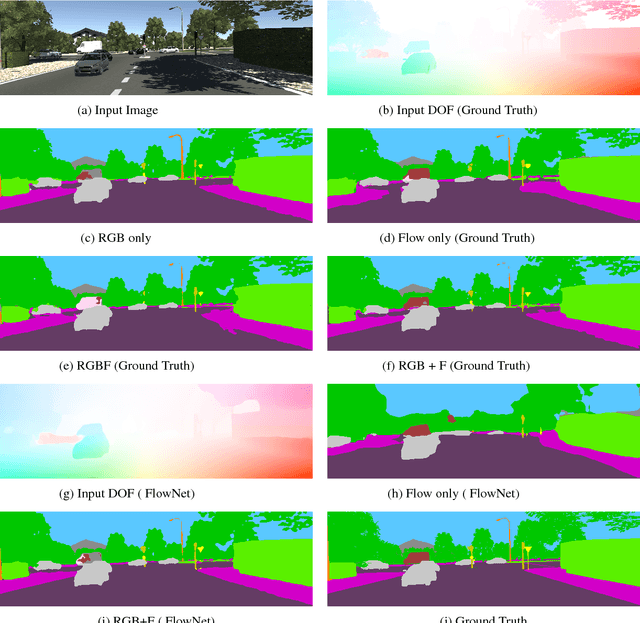

Motion is a dominant cue in automated driving systems. Optical flow is typically computed to detect moving objects and to estimate depth using triangulation. In this paper, our motivation is to leverage the existing dense optical flow to improve the performance of semantic segmentation. To provide a systematic study, we construct four different architectures which use RGB only, flow only, RGBF concatenated and two-stream RGB + flow. We evaluate these networks on two automotive datasets namely Virtual KITTI and Cityscapes using the state-of-the-art flow estimator FlowNet v2. We also make use of the ground truth optical flow in Virtual KITTI to serve as an ideal estimator and a standard Farneback optical flow algorithm to study the effect of noise. Using the flow ground truth in Virtual KITTI, two-stream architecture achieves the best results with an improvement of 4% IoU. As expected, there is a large improvement for moving objects like trucks, vans and cars with 38%, 28% and 6% increase in IoU. FlowNet produces an improvement of 2.4% in average IoU with larger improvement in the moving objects corresponding to 26%, 11% and 5% in trucks, vans and cars. In Cityscapes, flow augmentation provided an improvement for moving objects like motorcycle and train with an increase of 17% and 7% in IoU.