 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenges in Designing Datasets and Validation for Autonomous Driving
Paper and Code
Jan 26, 2019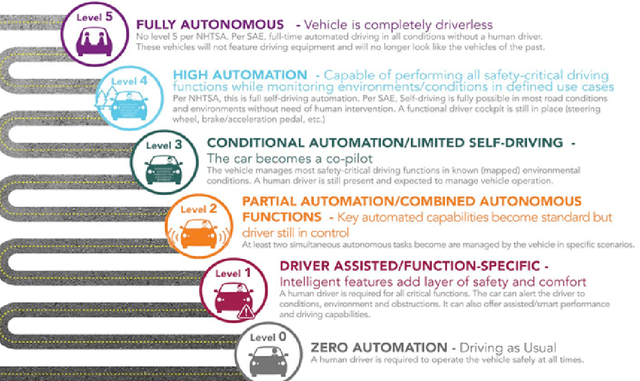
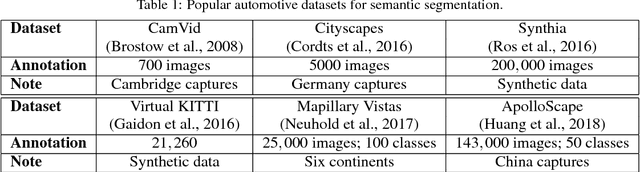
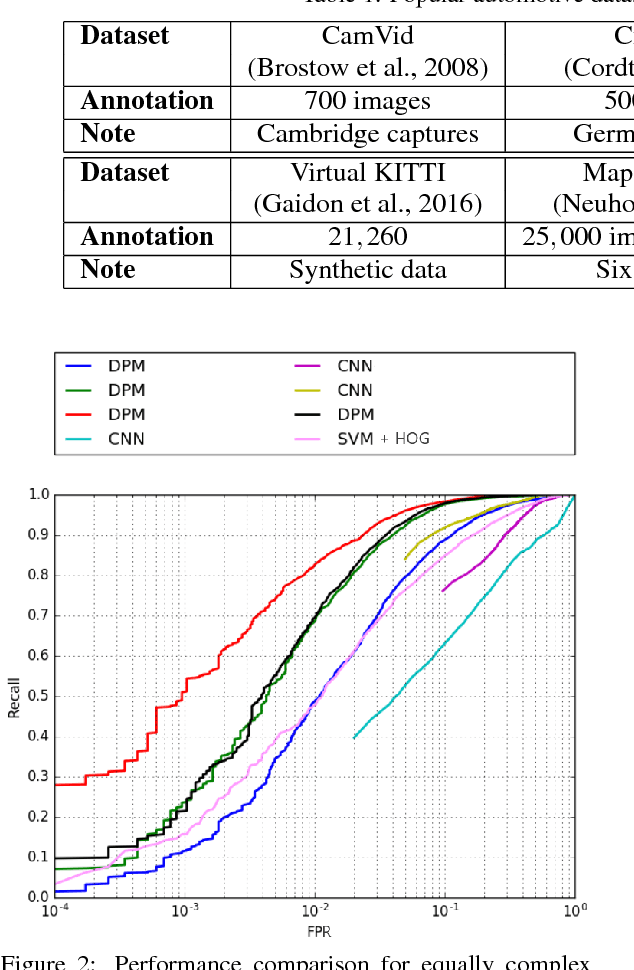

Autonomous driving is getting a lot of attention in the last decade and will be the hot topic at least until the first successful certification of a car with Level 5 autonomy. There are many public datasets in the academic community. However, they are far away from what a robust industrial production system needs. There is a large gap between academic and industrial setting and a substantial way from a research prototype, built on public datasets, to a deployable solution which is a challenging task. In this paper, we focus on bad practices that often happen in the autonomous driving from an industrial deployment perspective. Data design deserves at least the same amount of attention as the model design. There is very little attention paid to these issues in the scientific community, and we hope this paper encourages better formalization of dataset design. More specifically, we focus on the datasets design and validation scheme for autonomous driving, where we would like to highlight the common problems, wrong assumptions, and steps towards avoiding them, as well as some open problems.