 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorldCache: Content-Aware Caching for Accelerated Video World Models
Mar 23, 2026Diffusion Transformers (DiTs) power high-fidelity video world models but remain computationally expensive due to sequential denoising and costly spatio-temporal attention. Training-free feature caching accelerates inference by reusing intermediate activations across denoising steps; however, existing methods largely rely on a Zero-Order Hold assumption i.e., reusing cached features as static snapshots when global drift is small. This often leads to ghosting artifacts, blur, and motion inconsistencies in dynamic scenes. We propose \textbf{WorldCache}, a Perception-Constrained Dynamical Caching framework that improves both when and how to reuse features. WorldCache introduces motion-adaptive thresholds, saliency-weighted drift estimation, optimal approximation via blending and warping, and phase-aware threshold scheduling across diffusion steps. Our cohesive approach enables adaptive, motion-consistent feature reuse without retraining. On Cosmos-Predict2.5-2B evaluated on PAI-Bench, WorldCache achieves \textbf{2.3$\times$} inference speedup while preserving \textbf{99.4\%} of baseline quality, substantially outperforming prior training-free caching approaches. Our code can be accessed on \href{https://umair1221.github.io/World-Cache/}{World-Cache}.
Mobile-O: Unified Multimodal Understanding and Generation on Mobile Device
Feb 24, 2026Unified multimodal models can both understand and generate visual content within a single architecture. Existing models, however, remain data-hungry and too heavy for deployment on edge devices. We present Mobile-O, a compact vision-language-diffusion model that brings unified multimodal intelligence to a mobile device. Its core module, the Mobile Conditioning Projector (MCP), fuses vision-language features with a diffusion generator using depthwise-separable convolutions and layerwise alignment. This design enables efficient cross-modal conditioning with minimal computational cost. Trained on only a few million samples and post-trained in a novel quadruplet format (generation prompt, image, question, answer), Mobile-O jointly enhances both visual understanding and generation capabilities. Despite its efficiency, Mobile-O attains competitive or superior performance compared to other unified models, achieving 74% on GenEval and outperforming Show-O and JanusFlow by 5% and 11%, while running 6x and 11x faster, respectively. For visual understanding, Mobile-O surpasses them by 15.3% and 5.1% averaged across seven benchmarks. Running in only ~3s per 512x512 image on an iPhone, Mobile-O establishes the first practical framework for real-time unified multimodal understanding and generation on edge devices. We hope Mobile-O will ease future research in real-time unified multimodal intelligence running entirely on-device with no cloud dependency. Our code, models, datasets, and mobile application are publicly available at https://amshaker.github.io/Mobile-O/
VideoMathQA: Benchmarking Mathematical Reasoning via Multimodal Understanding in Videos
Jun 05, 2025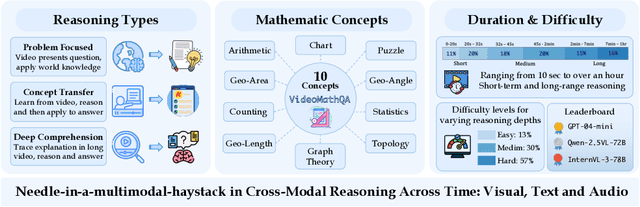
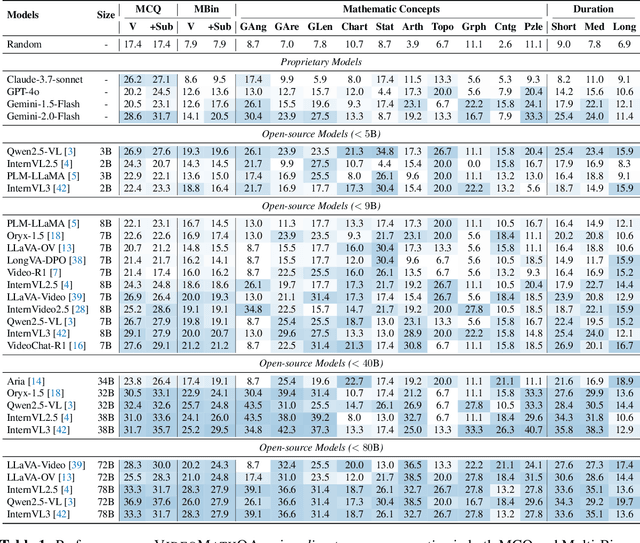

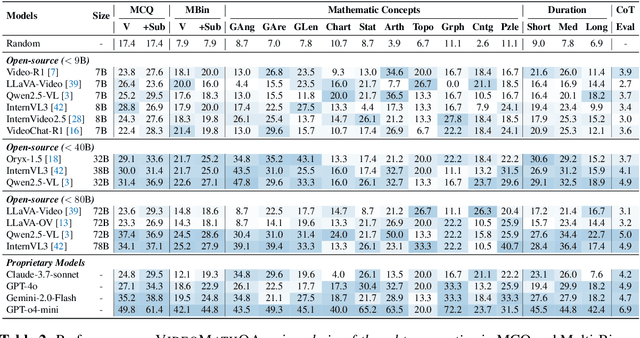
Mathematical reasoning in real-world video settings presents a fundamentally different challenge than in static images or text. It requires interpreting fine-grained visual information, accurately reading handwritten or digital text, and integrating spoken cues, often dispersed non-linearly over time. In such multimodal contexts, success hinges not just on perception, but on selectively identifying and integrating the right contextual details from a rich and noisy stream of content. To this end, we introduce VideoMathQA, a benchmark designed to evaluate whether models can perform such temporally extended cross-modal reasoning on videos. The benchmark spans 10 diverse mathematical domains, covering videos ranging from 10 seconds to over 1 hour. It requires models to interpret structured visual content, understand instructional narratives, and jointly ground concepts across visual, audio, and textual modalities. We employ graduate-level experts to ensure high quality, totaling over $920$ man-hours of annotation. To reflect real-world scenarios, questions are designed around three core reasoning challenges: direct problem solving, where answers are grounded in the presented question; conceptual transfer, which requires applying learned methods to new problems; and deep instructional comprehension, involving multi-step reasoning over extended explanations and partially worked-out solutions. Each question includes multi-step reasoning annotations, enabling fine-grained diagnosis of model capabilities. Through this benchmark, we highlight the limitations of existing approaches and establish a systematic evaluation framework for models that must reason, rather than merely perceive, across temporally extended and modality-rich mathematical problem settings. Our benchmark and evaluation code are available at: https://mbzuai-oryx.github.io/VideoMathQA
VideoMolmo: Spatio-Temporal Grounding Meets Pointing
Jun 05, 2025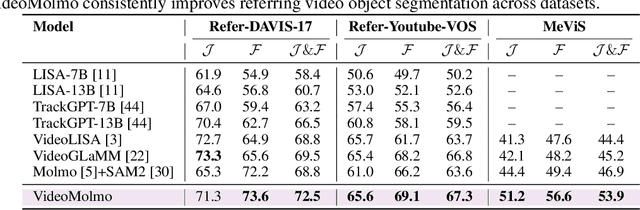
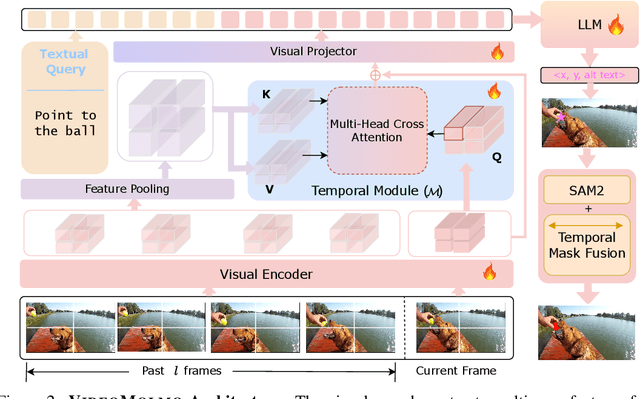

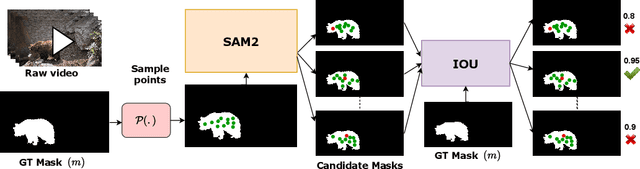
Spatio-temporal localization is vital for precise interactions across diverse domains, from biological research to autonomous navigation and interactive interfaces. Current video-based approaches, while proficient in tracking, lack the sophisticated reasoning capabilities of large language models, limiting their contextual understanding and generalization. We introduce VideoMolmo, a large multimodal model tailored for fine-grained spatio-temporal pointing conditioned on textual descriptions. Building upon the Molmo architecture, VideoMolmo incorporates a temporal module utilizing an attention mechanism to condition each frame on preceding frames, ensuring temporal consistency. Additionally, our novel temporal mask fusion pipeline employs SAM2 for bidirectional point propagation, significantly enhancing coherence across video sequences. This two-step decomposition, i.e., first using the LLM to generate precise pointing coordinates, then relying on a sequential mask-fusion module to produce coherent segmentation, not only simplifies the task for the language model but also enhances interpretability. Due to the lack of suitable datasets, we curate a comprehensive dataset comprising 72k video-caption pairs annotated with 100k object points. To evaluate the generalization of VideoMolmo, we introduce VPoS-Bench, a challenging out-of-distribution benchmark spanning five real-world scenarios: Cell Tracking, Egocentric Vision, Autonomous Driving, Video-GUI Interaction, and Robotics. We also evaluate our model on Referring Video Object Segmentation (Refer-VOS) and Reasoning VOS tasks. In comparison to existing models, VideoMolmo substantially improves spatio-temporal pointing accuracy and reasoning capability. Our code and models are publicly available at https://github.com/mbzuai-oryx/VideoMolmo.
Mobile-VideoGPT: Fast and Accurate Video Understanding Language Model
Mar 27, 2025Video understanding models often struggle with high computational requirements, extensive parameter counts, and slow inference speed, making them inefficient for practical use. To tackle these challenges, we propose Mobile-VideoGPT, an efficient multimodal framework designed to operate with fewer than a billion parameters. Unlike traditional video large multimodal models (LMMs), Mobile-VideoGPT consists of lightweight dual visual encoders, efficient projectors, and a small language model (SLM), enabling real-time throughput. To further improve efficiency, we present an Attention-Based Frame Scoring mechanism to select the key-frames, along with an efficient token projector that prunes redundant visual tokens and preserves essential contextual cues. We evaluate our model across well-established six video understanding benchmarks (e.g., MVBench, EgoSchema, NextQA, and PercepTest). Our results show that Mobile-VideoGPT-0.5B can generate up to 46 tokens per second while outperforming existing state-of-the-art 0.5B-parameter models by 6 points on average with 40% fewer parameters and more than 2x higher throughput. Our code and models are publicly available at: https://github.com/Amshaker/Mobile-VideoGPT.
GroupMamba: Parameter-Efficient and Accurate Group Visual State Space Model
Jul 18, 2024



Recent advancements in state-space models (SSMs) have showcased effective performance in modeling long-range dependencies with subquadratic complexity. However, pure SSM-based models still face challenges related to stability and achieving optimal performance on computer vision tasks. Our paper addresses the challenges of scaling SSM-based models for computer vision, particularly the instability and inefficiency of large model sizes. To address this, we introduce a Modulated Group Mamba layer which divides the input channels into four groups and applies our proposed SSM-based efficient Visual Single Selective Scanning (VSSS) block independently to each group, with each VSSS block scanning in one of the four spatial directions. The Modulated Group Mamba layer also wraps the four VSSS blocks into a channel modulation operator to improve cross-channel communication. Furthermore, we introduce a distillation-based training objective to stabilize the training of large models, leading to consistent performance gains. Our comprehensive experiments demonstrate the merits of the proposed contributions, leading to superior performance over existing methods for image classification on ImageNet-1K, object detection, instance segmentation on MS-COCO, and semantic segmentation on ADE20K. Our tiny variant with 23M parameters achieves state-of-the-art performance with a classification top-1 accuracy of 83.3% on ImageNet-1K, while being 26% efficient in terms of parameters, compared to the best existing Mamba design of same model size. Our code and models are available at: https://github.com/Amshaker/GroupMamba.
Efficient Video Object Segmentation via Modulated Cross-Attention Memory
Mar 26, 2024



Recently, transformer-based approaches have shown promising results for semi-supervised video object segmentation. However, these approaches typically struggle on long videos due to increased GPU memory demands, as they frequently expand the memory bank every few frames. We propose a transformer-based approach, named MAVOS, that introduces an optimized and dynamic long-term modulated cross-attention (MCA) memory to model temporal smoothness without requiring frequent memory expansion. The proposed MCA effectively encodes both local and global features at various levels of granularity while efficiently maintaining consistent speed regardless of the video length. Extensive experiments on multiple benchmarks, LVOS, Long-Time Video, and DAVIS 2017, demonstrate the effectiveness of our proposed contributions leading to real-time inference and markedly reduced memory demands without any degradation in segmentation accuracy on long videos. Compared to the best existing transformer-based approach, our MAVOS increases the speed by 7.6x, while significantly reducing the GPU memory by 87% with comparable segmentation performance on short and long video datasets. Notably on the LVOS dataset, our MAVOS achieves a J&F score of 63.3% while operating at 37 frames per second (FPS) on a single V100 GPU. Our code and models will be publicly available at: https://github.com/Amshaker/MAVOS.
PALO: A Polyglot Large Multimodal Model for 5B People
Mar 05, 2024



In pursuit of more inclusive Vision-Language Models (VLMs), this study introduces a Large Multilingual Multimodal Model called PALO. PALO offers visual reasoning capabilities in 10 major languages, including English, Chinese, Hindi, Spanish, French, Arabic, Bengali, Russian, Urdu, and Japanese, that span a total of ~5B people (65% of the world population). Our approach involves a semi-automated translation approach to adapt the multimodal instruction dataset from English to the target languages using a fine-tuned Large Language Model, thereby ensuring high linguistic fidelity while allowing scalability due to minimal manual effort. The incorporation of diverse instruction sets helps us boost overall performance across multiple languages especially those that are underrepresented like Hindi, Arabic, Bengali, and Urdu. The resulting models are trained across three scales (1.7B, 7B and 13B parameters) to show the generalization and scalability where we observe substantial improvements compared to strong baselines. We also propose the first multilingual multimodal benchmark for the forthcoming approaches to evaluate their vision-language reasoning capabilities across languages. Code: https://github.com/mbzuai-oryx/PALO.
Arabic Mini-ClimateGPT : A Climate Change and Sustainability Tailored Arabic LLM
Dec 14, 2023

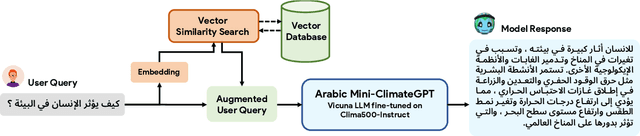
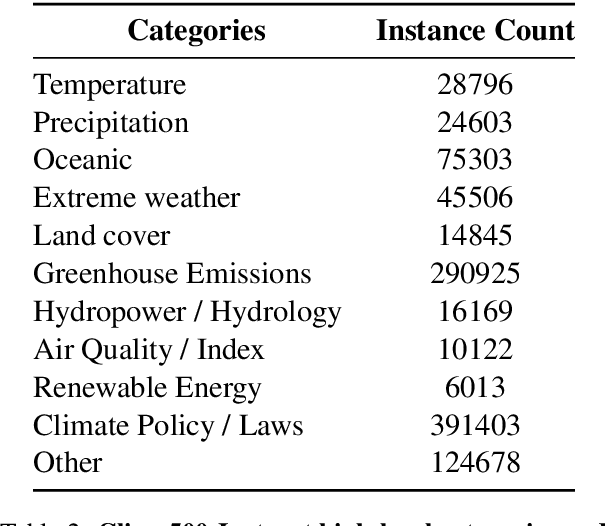
Climate change is one of the most significant challenges we face together as a society. Creating awareness and educating policy makers the wide-ranging impact of climate change is an essential step towards a sustainable future. Recently, Large Language Models (LLMs) like ChatGPT and Bard have shown impressive conversational abilities and excel in a wide variety of NLP tasks. While these models are close-source, recently alternative open-source LLMs such as Stanford Alpaca and Vicuna have shown promising results. However, these open-source models are not specifically tailored for climate related domain specific information and also struggle to generate meaningful responses in other languages such as, Arabic. To this end, we propose a light-weight Arabic Mini-ClimateGPT that is built on an open-source LLM and is specifically fine-tuned on a conversational-style instruction tuning curated Arabic dataset Clima500-Instruct with over 500k instructions about climate change and sustainability. Further, our model also utilizes a vector embedding based retrieval mechanism during inference. We validate our proposed model through quantitative and qualitative evaluations on climate-related queries. Our model surpasses the baseline LLM in 88.3% of cases during ChatGPT-based evaluation. Furthermore, our human expert evaluation reveals an 81.6% preference for our model's responses over multiple popular open-source models. Our open-source demos, code-base and models are available here https://github.com/mbzuai-oryx/ClimateGPT.
* Accepted to EMNLP 2023 (Findings)
GLaMM: Pixel Grounding Large Multimodal Model
Nov 06, 2023



Large Multimodal Models (LMMs) extend Large Language Models to the vision domain. Initial efforts towards LMMs used holistic images and text prompts to generate ungrounded textual responses. Very recently, region-level LMMs have been used to generate visually grounded responses. However, they are limited to only referring a single object category at a time, require users to specify the regions in inputs, or cannot offer dense pixel-wise object grounding. In this work, we present Grounding LMM (GLaMM), the first model that can generate natural language responses seamlessly intertwined with corresponding object segmentation masks. GLaMM not only grounds objects appearing in the conversations but is flexible enough to accept both textual and optional visual prompts (region of interest) as input. This empowers users to interact with the model at various levels of granularity, both in textual and visual domains. Due to the lack of standard benchmarks for the novel setting of generating visually grounded detailed conversations, we introduce a comprehensive evaluation protocol with our curated grounded conversations. Our proposed Grounded Conversation Generation (GCG) task requires densely grounded concepts in natural scenes at a large-scale. To this end, we propose a densely annotated Grounding-anything Dataset (GranD) using our proposed automated annotation pipeline that encompasses 7.5M unique concepts grounded in a total of 810M regions available with segmentation masks. Besides GCG, GLaMM also performs effectively on several downstream tasks e.g., referring expression segmentation, image and region-level captioning and vision-language conversations. Project Page: https://mbzuai-oryx.github.io/groundingLMM.