 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXrayGPT: Chest Radiographs Summarization using Medical Vision-Language Models
Paper and Code
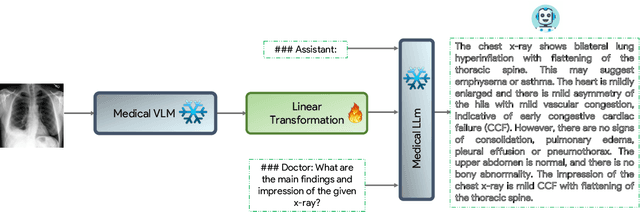
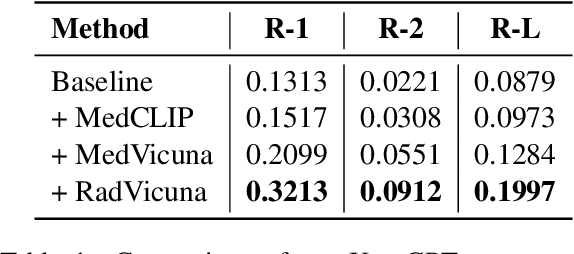


The latest breakthroughs in large vision-language models, such as Bard and GPT-4, have showcased extraordinary abilities in performing a wide range of tasks. Such models are trained on massive datasets comprising billions of public image-text pairs with diverse tasks. However, their performance on task-specific domains, such as radiology, is still under-investigated and potentially limited due to a lack of sophistication in understanding biomedical images. On the other hand, conversational medical models have exhibited remarkable success but have mainly focused on text-based analysis. In this paper, we introduce XrayGPT, a novel conversational medical vision-language model that can analyze and answer open-ended questions about chest radiographs. Specifically, we align both medical visual encoder (MedClip) with a fine-tuned large language model (Vicuna), using a simple linear transformation. This alignment enables our model to possess exceptional visual conversation abilities, grounded in a deep understanding of radiographs and medical domain knowledge. To enhance the performance of LLMs in the medical context, we generate ~217k interactive and high-quality summaries from free-text radiology reports. These summaries serve to enhance the performance of LLMs through the fine-tuning process. Our approach opens up new avenues the research for advancing the automated analysis of chest radiographs. Our open-source demos, models, and instruction sets are available at: https://github.com/mbzuai-oryx/XrayGPT.