 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoMathQA: Benchmarking Mathematical Reasoning via Multimodal Understanding in Videos
Jun 05, 2025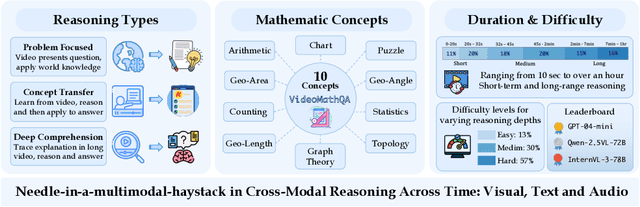
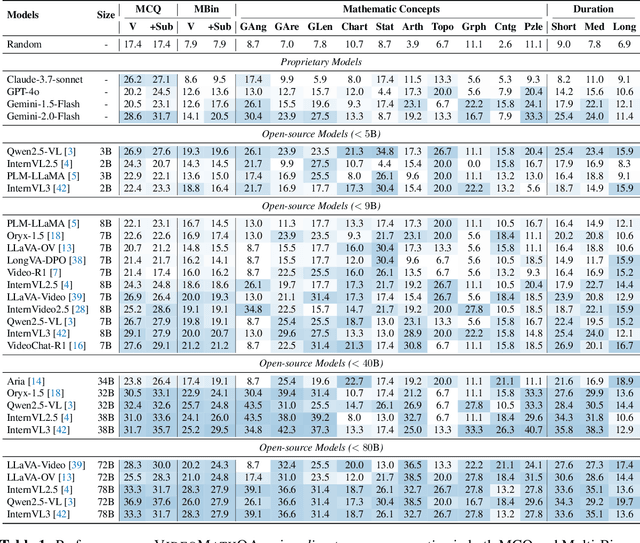

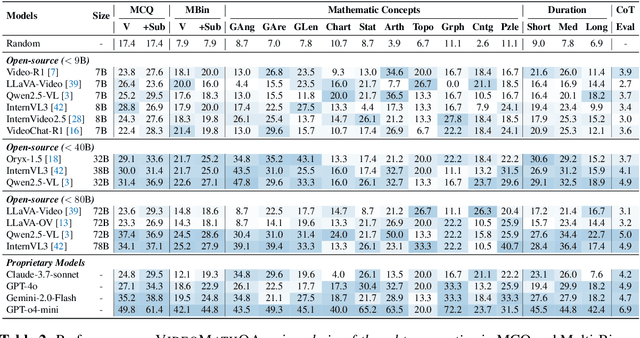
Mathematical reasoning in real-world video settings presents a fundamentally different challenge than in static images or text. It requires interpreting fine-grained visual information, accurately reading handwritten or digital text, and integrating spoken cues, often dispersed non-linearly over time. In such multimodal contexts, success hinges not just on perception, but on selectively identifying and integrating the right contextual details from a rich and noisy stream of content. To this end, we introduce VideoMathQA, a benchmark designed to evaluate whether models can perform such temporally extended cross-modal reasoning on videos. The benchmark spans 10 diverse mathematical domains, covering videos ranging from 10 seconds to over 1 hour. It requires models to interpret structured visual content, understand instructional narratives, and jointly ground concepts across visual, audio, and textual modalities. We employ graduate-level experts to ensure high quality, totaling over $920$ man-hours of annotation. To reflect real-world scenarios, questions are designed around three core reasoning challenges: direct problem solving, where answers are grounded in the presented question; conceptual transfer, which requires applying learned methods to new problems; and deep instructional comprehension, involving multi-step reasoning over extended explanations and partially worked-out solutions. Each question includes multi-step reasoning annotations, enabling fine-grained diagnosis of model capabilities. Through this benchmark, we highlight the limitations of existing approaches and establish a systematic evaluation framework for models that must reason, rather than merely perceive, across temporally extended and modality-rich mathematical problem settings. Our benchmark and evaluation code are available at: https://mbzuai-oryx.github.io/VideoMathQA
Perception Encoder: The best visual embeddings are not at the output of the network
Apr 17, 2025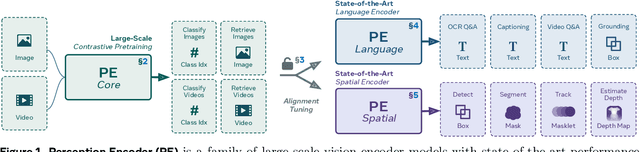

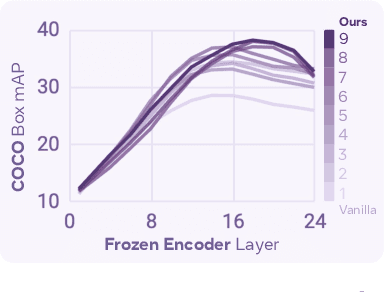
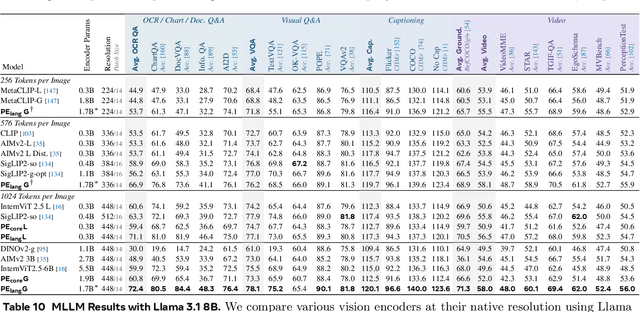
We introduce Perception Encoder (PE), a state-of-the-art encoder for image and video understanding trained via simple vision-language learning. Traditionally, vision encoders have relied on a variety of pretraining objectives, each tailored to specific downstream tasks such as classification, captioning, or localization. Surprisingly, after scaling our carefully tuned image pretraining recipe and refining with our robust video data engine, we find that contrastive vision-language training alone can produce strong, general embeddings for all of these downstream tasks. There is only one caveat: these embeddings are hidden within the intermediate layers of the network. To draw them out, we introduce two alignment methods, language alignment for multimodal language modeling, and spatial alignment for dense prediction. Together with the core contrastive checkpoint, our PE family of models achieves state-of-the-art performance on a wide variety of tasks, including zero-shot image and video classification and retrieval; document, image, and video Q&A; and spatial tasks such as detection, depth estimation, and tracking. To foster further research, we are releasing our models, code, and a novel dataset of synthetically and human-annotated videos.
PerceptionLM: Open-Access Data and Models for Detailed Visual Understanding
Apr 17, 2025



Vision-language models are integral to computer vision research, yet many high-performing models remain closed-source, obscuring their data, design and training recipe. The research community has responded by using distillation from black-box models to label training data, achieving strong benchmark results, at the cost of measurable scientific progress. However, without knowing the details of the teacher model and its data sources, scientific progress remains difficult to measure. In this paper, we study building a Perception Language Model (PLM) in a fully open and reproducible framework for transparent research in image and video understanding. We analyze standard training pipelines without distillation from proprietary models and explore large-scale synthetic data to identify critical data gaps, particularly in detailed video understanding. To bridge these gaps, we release 2.8M human-labeled instances of fine-grained video question-answer pairs and spatio-temporally grounded video captions. Additionally, we introduce PLM-VideoBench, a suite for evaluating challenging video understanding tasks focusing on the ability to reason about "what", "where", "when", and "how" of a video. We make our work fully reproducible by providing data, training recipes, code & models.
VideoGPT+: Integrating Image and Video Encoders for Enhanced Video Understanding
Jun 13, 2024



Building on the advances of language models, Large Multimodal Models (LMMs) have contributed significant improvements in video understanding. While the current video LMMs utilize advanced Large Language Models (LLMs), they rely on either image or video encoders to process visual inputs, each of which has its own limitations. Image encoders excel at capturing rich spatial details from frame sequences but lack explicit temporal context, which can be important in videos with intricate action sequences. On the other hand, video encoders provide temporal context but are often limited by computational constraints that lead to processing only sparse frames at lower resolutions, resulting in reduced contextual and spatial understanding. To this end, we introduce VideoGPT+, which combines the complementary benefits of the image encoder (for detailed spatial understanding) and the video encoder (for global temporal context modeling). The model processes videos by dividing them into smaller segments and applies an adaptive pooling strategy on features extracted by both image and video encoders. Our architecture showcases improved performance across multiple video benchmarks, including VCGBench, MVBench and Zero-shot question-answering. Further, we develop 112K video-instruction set using a novel semi-automatic annotation pipeline which further improves the model performance. Additionally, to comprehensively evaluate video LMMs, we present VCGBench-Diverse, covering 18 broad video categories such as lifestyle, sports, science, gaming, and surveillance videos. This benchmark with 4,354 question-answer pairs evaluates the generalization of existing LMMs on dense video captioning, spatial and temporal understanding, and complex reasoning, ensuring comprehensive assessment across diverse video types and dynamics. Code: https://github.com/mbzuai-oryx/VideoGPT-plus.
PALO: A Polyglot Large Multimodal Model for 5B People
Mar 05, 2024



In pursuit of more inclusive Vision-Language Models (VLMs), this study introduces a Large Multilingual Multimodal Model called PALO. PALO offers visual reasoning capabilities in 10 major languages, including English, Chinese, Hindi, Spanish, French, Arabic, Bengali, Russian, Urdu, and Japanese, that span a total of ~5B people (65% of the world population). Our approach involves a semi-automated translation approach to adapt the multimodal instruction dataset from English to the target languages using a fine-tuned Large Language Model, thereby ensuring high linguistic fidelity while allowing scalability due to minimal manual effort. The incorporation of diverse instruction sets helps us boost overall performance across multiple languages especially those that are underrepresented like Hindi, Arabic, Bengali, and Urdu. The resulting models are trained across three scales (1.7B, 7B and 13B parameters) to show the generalization and scalability where we observe substantial improvements compared to strong baselines. We also propose the first multilingual multimodal benchmark for the forthcoming approaches to evaluate their vision-language reasoning capabilities across languages. Code: https://github.com/mbzuai-oryx/PALO.
GLaMM: Pixel Grounding Large Multimodal Model
Nov 06, 2023



Large Multimodal Models (LMMs) extend Large Language Models to the vision domain. Initial efforts towards LMMs used holistic images and text prompts to generate ungrounded textual responses. Very recently, region-level LMMs have been used to generate visually grounded responses. However, they are limited to only referring a single object category at a time, require users to specify the regions in inputs, or cannot offer dense pixel-wise object grounding. In this work, we present Grounding LMM (GLaMM), the first model that can generate natural language responses seamlessly intertwined with corresponding object segmentation masks. GLaMM not only grounds objects appearing in the conversations but is flexible enough to accept both textual and optional visual prompts (region of interest) as input. This empowers users to interact with the model at various levels of granularity, both in textual and visual domains. Due to the lack of standard benchmarks for the novel setting of generating visually grounded detailed conversations, we introduce a comprehensive evaluation protocol with our curated grounded conversations. Our proposed Grounded Conversation Generation (GCG) task requires densely grounded concepts in natural scenes at a large-scale. To this end, we propose a densely annotated Grounding-anything Dataset (GranD) using our proposed automated annotation pipeline that encompasses 7.5M unique concepts grounded in a total of 810M regions available with segmentation masks. Besides GCG, GLaMM also performs effectively on several downstream tasks e.g., referring expression segmentation, image and region-level captioning and vision-language conversations. Project Page: https://mbzuai-oryx.github.io/groundingLMM.
Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models
Jun 08, 2023



Conversation agents fueled by Large Language Models (LLMs) are providing a new way to interact with visual data. While there have been initial attempts for image-based conversation models, this work addresses the underexplored field of video-based conversation by introducing Video-ChatGPT. It is a multimodal model that merges a video-adapted visual encoder with a LLM. The model is capable of understanding and generating human-like conversations about videos. We introduce a new dataset of 100,000 video-instruction pairs used to train Video-ChatGPT acquired via manual and semi-automated pipeline that is easily scalable and robust to label noise. We also develop a quantiative evaluation framework for video-based dialogue models to objectively analyse the strengths and weaknesses of proposed models. Our code, models, instruction-sets and demo are released at https://github.com/mbzuai-oryx/Video-ChatGPT.
SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications
Mar 27, 2023


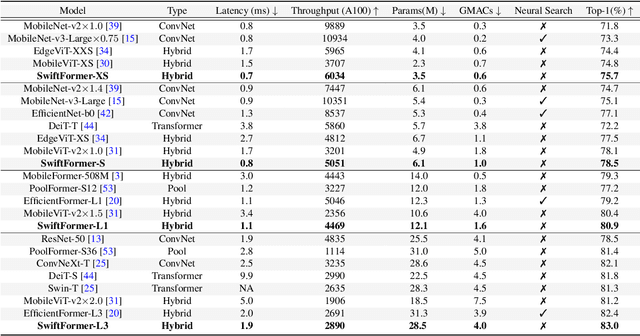
Self-attention has become a defacto choice for capturing global context in various vision applications. However, its quadratic computational complexity with respect to image resolution limits its use in real-time applications, especially for deployment on resource-constrained mobile devices. Although hybrid approaches have been proposed to combine the advantages of convolutions and self-attention for a better speed-accuracy trade-off, the expensive matrix multiplication operations in self-attention remain a bottleneck. In this work, we introduce a novel efficient additive attention mechanism that effectively replaces the quadratic matrix multiplication operations with linear element-wise multiplications. Our design shows that the key-value interaction can be replaced with a linear layer without sacrificing any accuracy. Unlike previous state-of-the-art methods, our efficient formulation of self-attention enables its usage at all stages of the network. Using our proposed efficient additive attention, we build a series of models called "SwiftFormer" which achieves state-of-the-art performance in terms of both accuracy and mobile inference speed. Our small variant achieves 78.5% top-1 ImageNet-1K accuracy with only 0.8 ms latency on iPhone 14, which is more accurate and 2x faster compared to MobileViT-v2. Code: https://github.com/Amshaker/SwiftFormer
UNETR++: Delving into Efficient and Accurate 3D Medical Image Segmentation
Dec 08, 2022



Owing to the success of transformer models, recent works study their applicability in 3D medical segmentation tasks. Within the transformer models, the self-attention mechanism is one of the main building blocks that strives to capture long-range dependencies, compared to the local convolutional-based design. However, the self-attention operation has quadratic complexity which proves to be a computational bottleneck, especially in volumetric medical imaging, where the inputs are 3D with numerous slices. In this paper, we propose a 3D medical image segmentation approach, named UNETR++, that offers both high-quality segmentation masks as well as efficiency in terms of parameters and compute cost. The core of our design is the introduction of a novel efficient paired attention (EPA) block that efficiently learns spatial and channel-wise discriminative features using a pair of inter-dependent branches based on spatial and channel attention. Our spatial attention formulation is efficient having linear complexity with respect to the input sequence length. To enable communication between spatial and channel-focused branches, we share the weights of query and key mapping functions that provide a complimentary benefit (paired attention), while also reducing the overall network parameters. Our extensive evaluations on three benchmarks, Synapse, BTCV and ACDC, reveal the effectiveness of the proposed contributions in terms of both efficiency and accuracy. On Synapse dataset, our UNETR++ sets a new state-of-the-art with a Dice Similarity Score of 87.2%, while being significantly efficient with a reduction of over 71% in terms of both parameters and FLOPs, compared to the best existing method in the literature. Code: https://github.com/Amshaker/unetr_plus_plus.
Fine-tuned CLIP Models are Efficient Video Learners
Dec 06, 2022



Large-scale multi-modal training with image-text pairs imparts strong generalization to CLIP model. Since training on a similar scale for videos is infeasible, recent approaches focus on the effective transfer of image-based CLIP to the video domain. In this pursuit, new parametric modules are added to learn temporal information and inter-frame relationships which require meticulous design efforts. Furthermore, when the resulting models are learned on videos, they tend to overfit on the given task distribution and lack in generalization aspect. This begs the following question: How to effectively transfer image-level CLIP representations to videos? In this work, we show that a simple Video Fine-tuned CLIP (ViFi-CLIP) baseline is generally sufficient to bridge the domain gap from images to videos. Our qualitative analysis illustrates that the frame-level processing from CLIP image-encoder followed by feature pooling and similarity matching with corresponding text embeddings helps in implicitly modeling the temporal cues within ViFi-CLIP. Such fine-tuning helps the model to focus on scene dynamics, moving objects and inter-object relationships. For low-data regimes where full fine-tuning is not viable, we propose a `bridge and prompt' approach that first uses fine-tuning to bridge the domain gap and then learns prompts on language and vision side to adapt CLIP representations. We extensively evaluate this simple yet strong baseline on zero-shot, base-to-novel generalization, few-shot and fully supervised settings across five video benchmarks. Our code is available at https://github.com/muzairkhattak/ViFi-CLIP.