 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerception Encoder: The best visual embeddings are not at the output of the network
Apr 17, 2025

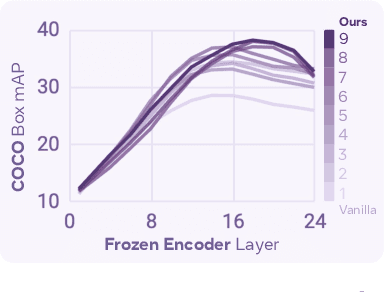
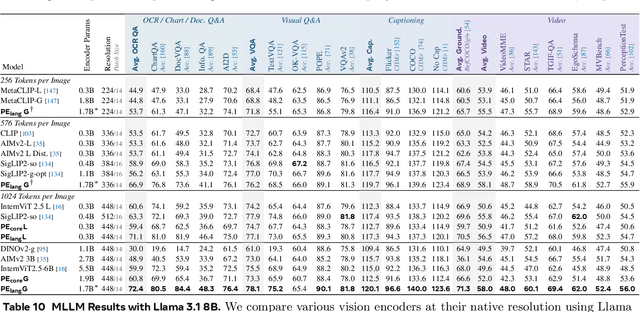
We introduce Perception Encoder (PE), a state-of-the-art encoder for image and video understanding trained via simple vision-language learning. Traditionally, vision encoders have relied on a variety of pretraining objectives, each tailored to specific downstream tasks such as classification, captioning, or localization. Surprisingly, after scaling our carefully tuned image pretraining recipe and refining with our robust video data engine, we find that contrastive vision-language training alone can produce strong, general embeddings for all of these downstream tasks. There is only one caveat: these embeddings are hidden within the intermediate layers of the network. To draw them out, we introduce two alignment methods, language alignment for multimodal language modeling, and spatial alignment for dense prediction. Together with the core contrastive checkpoint, our PE family of models achieves state-of-the-art performance on a wide variety of tasks, including zero-shot image and video classification and retrieval; document, image, and video Q&A; and spatial tasks such as detection, depth estimation, and tracking. To foster further research, we are releasing our models, code, and a novel dataset of synthetically and human-annotated videos.
Enhanced POET: Open-Ended Reinforcement Learning through Unbounded Invention of Learning Challenges and their Solutions
Apr 13, 2020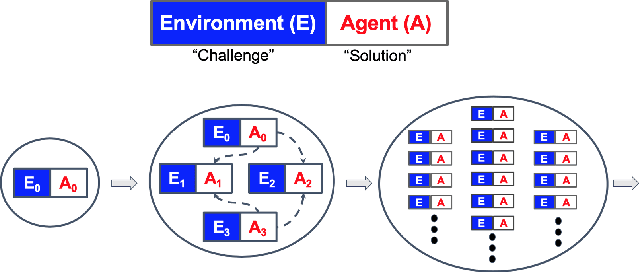

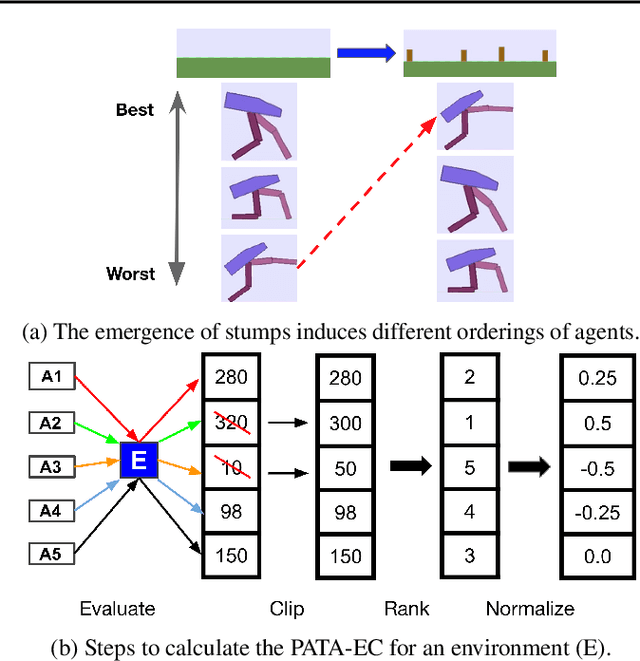
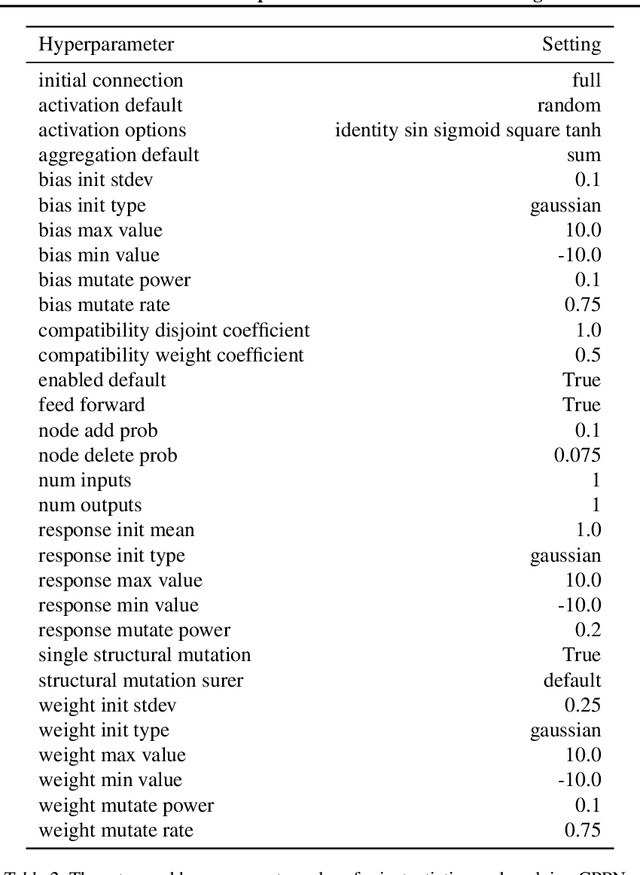
Creating open-ended algorithms, which generate their own never-ending stream of novel and appropriately challenging learning opportunities, could help to automate and accelerate progress in machine learning. A recent step in this direction is the Paired Open-Ended Trailblazer (POET), an algorithm that generates and solves its own challenges, and allows solutions to goal-switch between challenges to avoid local optima. However, the original POET was unable to demonstrate its full creative potential because of limitations of the algorithm itself and because of external issues including a limited problem space and lack of a universal progress measure. Importantly, both limitations pose impediments not only for POET, but for the pursuit of open-endedness in general. Here we introduce and empirically validate two new innovations to the original algorithm, as well as two external innovations designed to help elucidate its full potential. Together, these four advances enable the most open-ended algorithmic demonstration to date. The algorithmic innovations are (1) a domain-general measure of how meaningfully novel new challenges are, enabling the system to potentially create and solve interesting challenges endlessly, and (2) an efficient heuristic for determining when agents should goal-switch from one problem to another (helping open-ended search better scale). Outside the algorithm itself, to enable a more definitive demonstration of open-endedness, we introduce (3) a novel, more flexible way to encode environmental challenges, and (4) a generic measure of the extent to which a system continues to exhibit open-ended innovation. Enhanced POET produces a diverse range of sophisticated behaviors that solve a wide range of environmental challenges, many of which cannot be solved through other means.
Fiber: A Platform for Efficient Development and Distributed Training for Reinforcement Learning and Population-Based Methods
Mar 25, 2020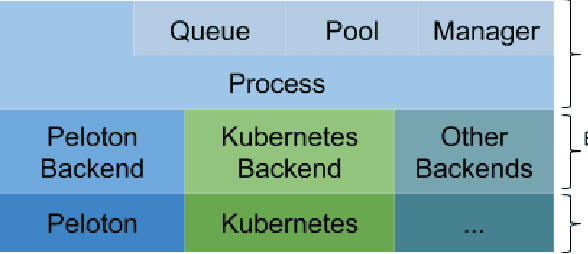
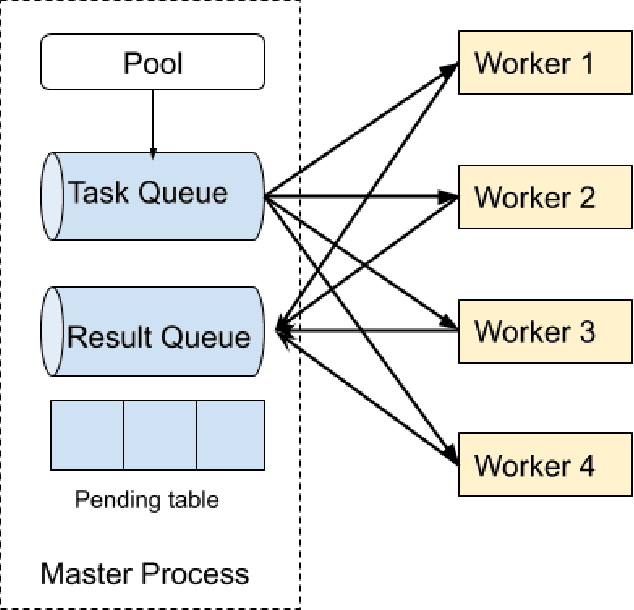
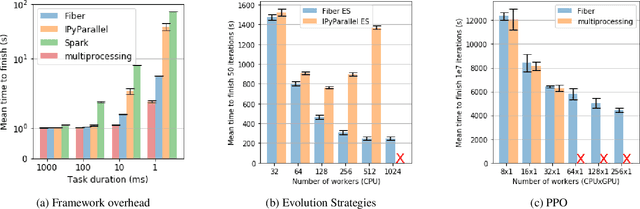
Recent advances in machine learning are consistently enabled by increasing amounts of computation. Reinforcement learning (RL) and population-based methods in particular pose unique challenges for efficiency and flexibility to the underlying distributed computing frameworks. These challenges include frequent interaction with simulations, the need for dynamic scaling, and the need for a user interface with low adoption cost and consistency across different backends. In this paper we address these challenges while still retaining development efficiency and flexibility for both research and practical applications by introducing Fiber, a scalable distributed computing framework for RL and population-based methods. Fiber aims to significantly expand the accessibility of large-scale parallel computation to users of otherwise complicated RL and population-based approaches without the need to for specialized computational expertise.