 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Perception Encoder: The best visual embeddings are not at the output of the network
Apr 17, 2025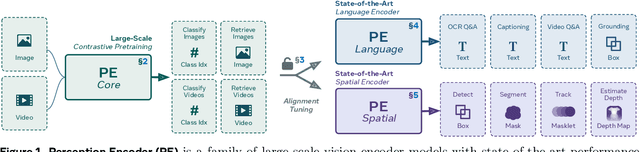

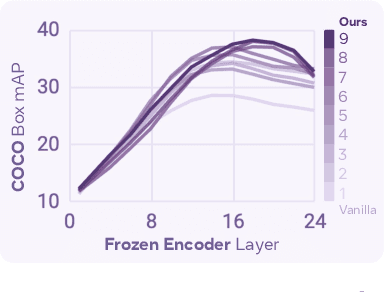
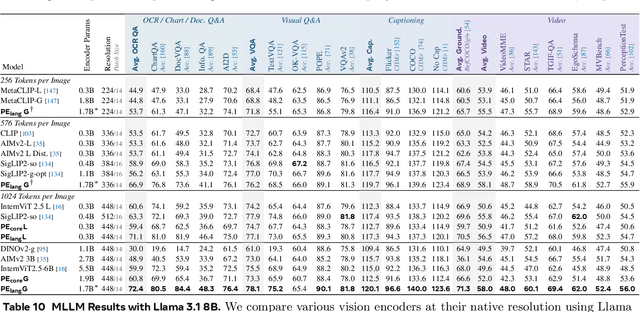
We introduce Perception Encoder (PE), a state-of-the-art encoder for image and video understanding trained via simple vision-language learning. Traditionally, vision encoders have relied on a variety of pretraining objectives, each tailored to specific downstream tasks such as classification, captioning, or localization. Surprisingly, after scaling our carefully tuned image pretraining recipe and refining with our robust video data engine, we find that contrastive vision-language training alone can produce strong, general embeddings for all of these downstream tasks. There is only one caveat: these embeddings are hidden within the intermediate layers of the network. To draw them out, we introduce two alignment methods, language alignment for multimodal language modeling, and spatial alignment for dense prediction. Together with the core contrastive checkpoint, our PE family of models achieves state-of-the-art performance on a wide variety of tasks, including zero-shot image and video classification and retrieval; document, image, and video Q&A; and spatial tasks such as detection, depth estimation, and tracking. To foster further research, we are releasing our models, code, and a novel dataset of synthetically and human-annotated videos.
PerceptionLM: Open-Access Data and Models for Detailed Visual Understanding
Apr 17, 2025



Vision-language models are integral to computer vision research, yet many high-performing models remain closed-source, obscuring their data, design and training recipe. The research community has responded by using distillation from black-box models to label training data, achieving strong benchmark results, at the cost of measurable scientific progress. However, without knowing the details of the teacher model and its data sources, scientific progress remains difficult to measure. In this paper, we study building a Perception Language Model (PLM) in a fully open and reproducible framework for transparent research in image and video understanding. We analyze standard training pipelines without distillation from proprietary models and explore large-scale synthetic data to identify critical data gaps, particularly in detailed video understanding. To bridge these gaps, we release 2.8M human-labeled instances of fine-grained video question-answer pairs and spatio-temporally grounded video captions. Additionally, we introduce PLM-VideoBench, a suite for evaluating challenging video understanding tasks focusing on the ability to reason about "what", "where", "when", and "how" of a video. We make our work fully reproducible by providing data, training recipes, code & models.
$VILA^2$: VILA Augmented VILA
Jul 24, 2024Visual language models (VLMs) have rapidly progressed, driven by the success of large language models (LLMs). While model architectures and training infrastructures advance rapidly, data curation remains under-explored. When data quantity and quality become a bottleneck, existing work either directly crawls more raw data from the Internet that does not have a guarantee of data quality or distills from black-box commercial models (e.g., GPT-4V / Gemini) causing the performance upper bounded by that model. In this work, we introduce a novel approach that includes a self-augment step and a specialist-augment step to iteratively improve data quality and model performance. In the self-augment step, a VLM recaptions its own pretraining data to enhance data quality, and then retrains from scratch using this refined dataset to improve model performance. This process can iterate for several rounds. Once self-augmentation saturates, we employ several specialist VLMs finetuned from the self-augmented VLM with domain-specific expertise, to further infuse specialist knowledge into the generalist VLM through task-oriented recaptioning and retraining. With the combined self-augmented and specialist-augmented training, we introduce $VILA^2$ (VILA-augmented-VILA), a VLM family that consistently improves the accuracy on a wide range of tasks over prior art, and achieves new state-of-the-art results on MMMU leaderboard among open-sourced models.
Language-Image Models with 3D Understanding
May 06, 2024Multi-modal large language models (MLLMs) have shown incredible capabilities in a variety of 2D vision and language tasks. We extend MLLMs' perceptual capabilities to ground and reason about images in 3-dimensional space. To that end, we first develop a large-scale pre-training dataset for 2D and 3D called LV3D by combining multiple existing 2D and 3D recognition datasets under a common task formulation: as multi-turn question-answering. Next, we introduce a new MLLM named Cube-LLM and pre-train it on LV3D. We show that pure data scaling makes a strong 3D perception capability without 3D specific architectural design or training objective. Cube-LLM exhibits intriguing properties similar to LLMs: (1) Cube-LLM can apply chain-of-thought prompting to improve 3D understanding from 2D context information. (2) Cube-LLM can follow complex and diverse instructions and adapt to versatile input and output formats. (3) Cube-LLM can be visually prompted such as 2D box or a set of candidate 3D boxes from specialists. Our experiments on outdoor benchmarks demonstrate that Cube-LLM significantly outperforms existing baselines by 21.3 points of AP-BEV on the Talk2Car dataset for 3D grounded reasoning and 17.7 points on the DriveLM dataset for complex reasoning about driving scenarios, respectively. Cube-LLM also shows competitive results in general MLLM benchmarks such as refCOCO for 2D grounding with (87.0) average score, as well as visual question answering benchmarks such as VQAv2, GQA, SQA, POPE, etc. for complex reasoning. Our project is available at https://janghyuncho.github.io/Cube-LLM.
Language-conditioned Detection Transformer
Nov 29, 2023We present a new open-vocabulary detection framework. Our framework uses both image-level labels and detailed detection annotations when available. Our framework proceeds in three steps. We first train a language-conditioned object detector on fully-supervised detection data. This detector gets to see the presence or absence of ground truth classes during training, and conditions prediction on the set of present classes. We use this detector to pseudo-label images with image-level labels. Our detector provides much more accurate pseudo-labels than prior approaches with its conditioning mechanism. Finally, we train an unconditioned open-vocabulary detector on the pseudo-annotated images. The resulting detector, named DECOLA, shows strong zero-shot performance in open-vocabulary LVIS benchmark as well as direct zero-shot transfer benchmarks on LVIS, COCO, Object365, and OpenImages. DECOLA outperforms the prior arts by 17.1 AP-rare and 9.4 mAP on zero-shot LVIS benchmark. DECOLA achieves state-of-the-art results in various model sizes, architectures, and datasets by only training on open-sourced data and academic-scale computing. Code is available at https://github.com/janghyuncho/DECOLA.
Long-tail Detection with Effective Class-Margins
Jan 23, 2023Large-scale object detection and instance segmentation face a severe data imbalance. The finer-grained object classes become, the less frequent they appear in our datasets. However, at test-time, we expect a detector that performs well for all classes and not just the most frequent ones. In this paper, we provide a theoretical understanding of the long-trail detection problem. We show how the commonly used mean average precision evaluation metric on an unknown test set is bound by a margin-based binary classification error on a long-tailed object detection training set. We optimize margin-based binary classification error with a novel surrogate objective called \textbf{Effective Class-Margin Loss} (ECM). The ECM loss is simple, theoretically well-motivated, and outperforms other heuristic counterparts on LVIS v1 benchmark over a wide range of architecture and detectors. Code is available at \url{https://github.com/janghyuncho/ECM-Loss}.
NMS Strikes Back
Dec 12, 2022Detection Transformer (DETR) directly transforms queries to unique objects by using one-to-one bipartite matching during training and enables end-to-end object detection. Recently, these models have surpassed traditional detectors on COCO with undeniable elegance. However, they differ from traditional detectors in multiple designs, including model architecture and training schedules, and thus the effectiveness of one-to-one matching is not fully understood. In this work, we conduct a strict comparison between the one-to-one Hungarian matching in DETRs and the one-to-many label assignments in traditional detectors with non-maximum supervision (NMS). Surprisingly, we observe one-to-many assignments with NMS consistently outperform standard one-to-one matching under the same setting, with a significant gain of up to 2.5 mAP. Our detector that trains Deformable-DETR with traditional IoU-based label assignment achieved 50.2 COCO mAP within 12 epochs (1x schedule) with ResNet50 backbone, outperforming all existing traditional or transformer-based detectors in this setting. On multiple datasets, schedules, and architectures, we consistently show bipartite matching is unnecessary for performant detection transformers. Furthermore, we attribute the success of detection transformers to their expressive transformer architecture. Code is available at https://github.com/jozhang97/DETA.
PiCIE: Unsupervised Semantic Segmentation using Invariance and Equivariance in Clustering
Mar 30, 2021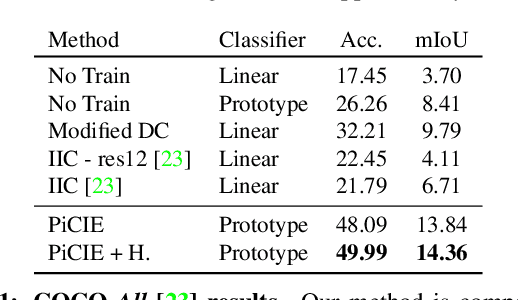
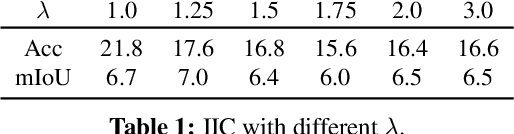
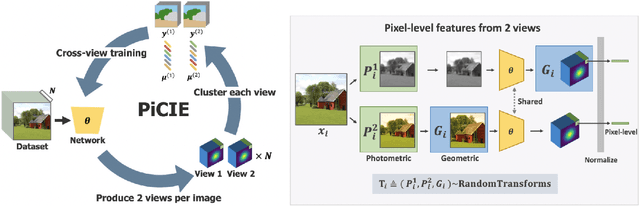
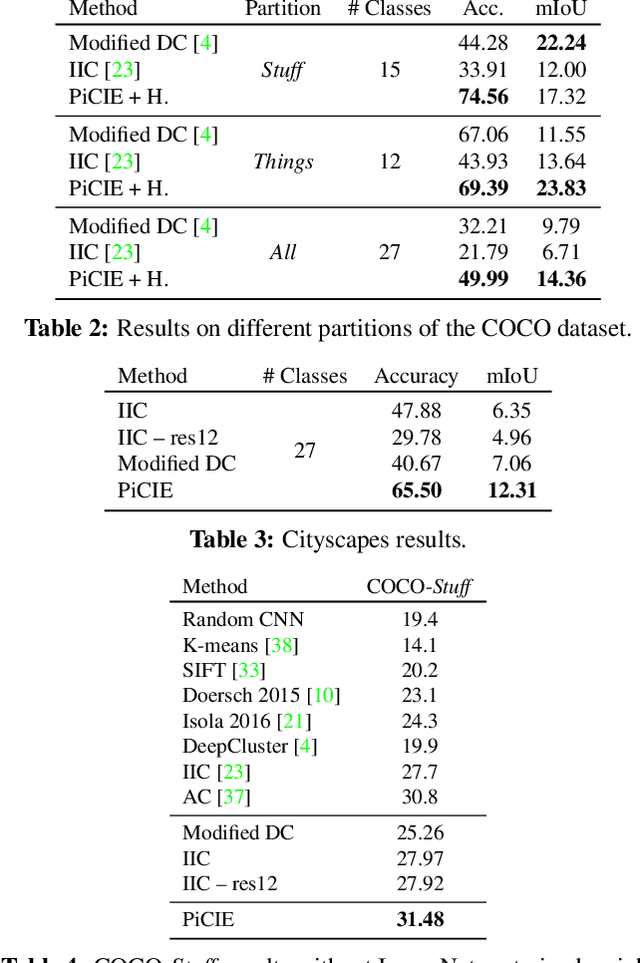
We present a new framework for semantic segmentation without annotations via clustering. Off-the-shelf clustering methods are limited to curated, single-label, and object-centric images yet real-world data are dominantly uncurated, multi-label, and scene-centric. We extend clustering from images to pixels and assign separate cluster membership to different instances within each image. However, solely relying on pixel-wise feature similarity fails to learn high-level semantic concepts and overfits to low-level visual cues. We propose a method to incorporate geometric consistency as an inductive bias to learn invariance and equivariance for photometric and geometric variations. With our novel learning objective, our framework can learn high-level semantic concepts. Our method, PiCIE (Pixel-level feature Clustering using Invariance and Equivariance), is the first method capable of segmenting both things and stuff categories without any hyperparameter tuning or task-specific pre-processing. Our method largely outperforms existing baselines on COCO and Cityscapes with +17.5 Acc. and +4.5 mIoU. We show that PiCIE gives a better initialization for standard supervised training. The code is available at https://github.com/janghyuncho/PiCIE.
On the Efficacy of Knowledge Distillation
Oct 03, 2019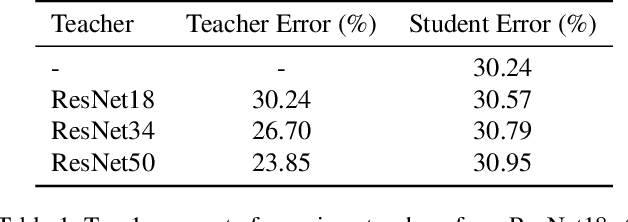
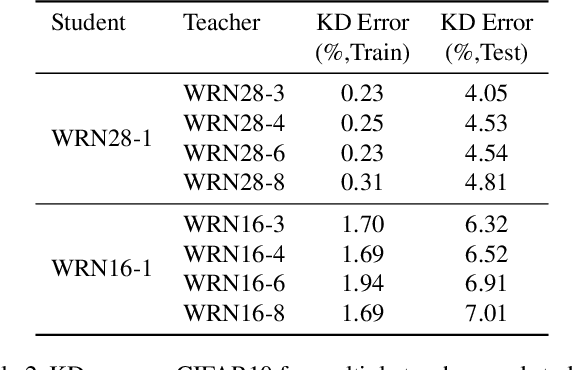
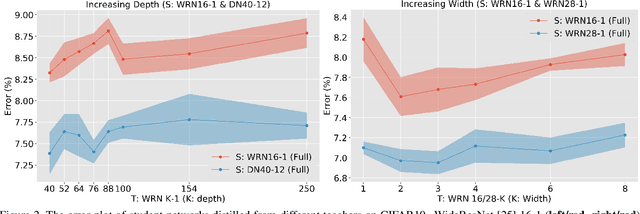
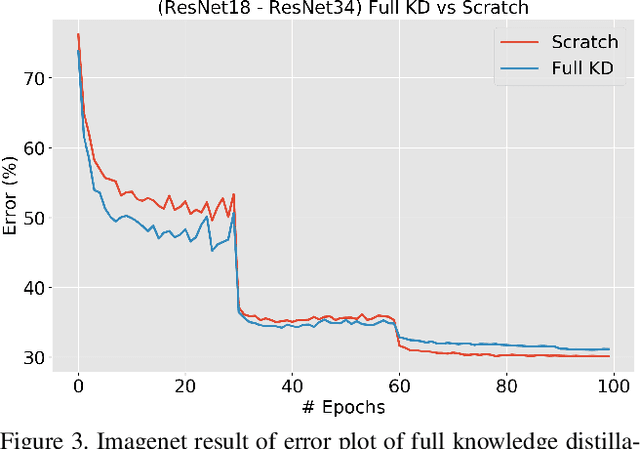
In this paper, we present a thorough evaluation of the efficacy of knowledge distillation and its dependence on student and teacher architectures. Starting with the observation that more accurate teachers often don't make good teachers, we attempt to tease apart the factors that affect knowledge distillation performance. We find crucially that larger models do not often make better teachers. We show that this is a consequence of mismatched capacity, and that small students are unable to mimic large teachers. We find typical ways of circumventing this (such as performing a sequence of knowledge distillation steps) to be ineffective. Finally, we show that this effect can be mitigated by stopping the teacher's training early. Our results generalize across datasets and models.
* 13 pages, including Appendix