 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanning-aligned Token Compression for Long-Context Autonomous Driving
Jun 05, 2026Monolithic vision-action models represent an emerging paradigm in autonomous driving. However, this architecture produces token sequences that quickly exceed real-time computational budgets when encoding extended temporal context for complex interactions. While approaches like linear transformers and external memory try to make the context lightweight, token compression is most compatible with the architecture as it requires no backbone modifications. Yet existing compression adopts rule-based heuristics like temporal decay, decoupled from planning, risking loss of decision-critical information. We propose COMPACT-VA, a planning-aligned working memory framework built on conditional VQ-VAE, compressing extended context into bounded representations. Compression is conditioned on both historical trajectory and a learned planning intent that the posterior encoder distills from future trajectories during training, while the prior encoder learns to predict it from compressed observations. The compressed memory, concatenated with the predicted latent, feeds the policy for end-to-end optimization, planning with retained decision-critical information. We evaluate on high-signal dynamic scenarios where historical context is most critical for behavior correctness (e.g., stop, yield, or proceed), and accordingly design behavioral metrics. Under comparable token budgets, we achieve $>$6% improvement (68.3%) on success rates with consistent gains across metrics. Ablations validate planning-aligned coupling effectiveness. Closed-loop evaluation confirms that COMPACT-VA maintained general driving performance with 3.3* speedup and 2.7* memory reduction over uncompressed processing.
Cosmos 3: Omnimodal World Models for Physical AI
Jun 01, 2026We introduce Cosmos 3, a family of omnimodal world models designed to jointly process and generate language, image, video, audio, and action sequences within a unified mixture-of-transformers architecture. By supporting highly flexible input-output configurations, Cosmos 3 seamlessly unifies critical modalities for Physical AI -- effectively subsuming vision-language models, video generators, world simulators, and world-action models into a single framework. Our evaluation demonstrates that Cosmos 3 establishes a new state-of-the-art across a diverse suite of understanding and generation tasks, demonstrating omnimodal world models as scalable, general-purpose backbones for embodied agents. Our post-trained Cosmos 3 models were ranked as the best open-source Text-to-Image and Image-to-Video models by Artificial Analysis, and the best policy model by RoboArena at the time the technical report was written. To accelerate open research and deployment in Physical AI, we make our code, model checkpoints, curated synthetic datasets, and evaluation benchmark available under the Linux Foundation's OpenMDW-1.1 https://openmdw.ai/license/1-1/ License at https://github.com/nvidia/cosmos}{github.com/nvidia/cosmos and https://huggingface.co/collections/nvidia/cosmos3 . The project website is available at https://research.nvidia.com/labs/cosmos-lab/cosmos3 .
Accelerating Structured Chain-of-Thought in Autonomous Vehicles
Feb 02, 2026Chain-of-Thought (CoT) reasoning enhances the decision-making capabilities of vision-language-action models in autonomous driving, but its autoregressive nature introduces significant inference latency, making it impractical for real-time applications. To address this, we introduce FastDriveCoT, a novel parallel decoding method that accelerates template-structured CoT. Our approach decomposes the reasoning process into a dependency graph of distinct sub-tasks, such as identifying critical objects and summarizing traffic rules, some of which can be generated in parallel. By generating multiple independent reasoning steps concurrently within a single forward pass, we significantly reduce the number of sequential computations. Experiments demonstrate a 3-4$\times$ speedup in CoT generation and a substantial reduction in end-to-end latency across various model architectures, all while preserving the original downstream task improvements brought by incorporating CoT reasoning.
Counterfactual VLA: Self-Reflective Vision-Language-Action Model with Adaptive Reasoning
Dec 30, 2025Recent reasoning-augmented Vision-Language-Action (VLA) models have improved the interpretability of end-to-end autonomous driving by generating intermediate reasoning traces. Yet these models primarily describe what they perceive and intend to do, rarely questioning whether their planned actions are safe or appropriate. This work introduces Counterfactual VLA (CF-VLA), a self-reflective VLA framework that enables the model to reason about and revise its planned actions before execution. CF-VLA first generates time-segmented meta-actions that summarize driving intent, and then performs counterfactual reasoning conditioned on both the meta-actions and the visual context. This step simulates potential outcomes, identifies unsafe behaviors, and outputs corrected meta-actions that guide the final trajectory generation. To efficiently obtain such self-reflective capabilities, we propose a rollout-filter-label pipeline that mines high-value scenes from a base (non-counterfactual) VLA's rollouts and labels counterfactual reasoning traces for subsequent training rounds. Experiments on large-scale driving datasets show that CF-VLA improves trajectory accuracy by up to 17.6%, enhances safety metrics by 20.5%, and exhibits adaptive thinking: it only enables counterfactual reasoning in challenging scenarios. By transforming reasoning traces from one-shot descriptions to causal self-correction signals, CF-VLA takes a step toward self-reflective autonomous driving agents that learn to think before they act.
Towards Efficient and Effective Multi-Camera Encoding for End-to-End Driving
Dec 12, 2025We present Flex, an efficient and effective scene encoder that addresses the computational bottleneck of processing high-volume multi-camera data in end-to-end autonomous driving. Flex employs a small set of learnable scene tokens to jointly encode information from all image tokens across different cameras and timesteps. By design, our approach is geometry-agnostic, learning a compact scene representation directly from data without relying on the explicit 3D inductive biases, such as Bird-Eye-View (BEV), occupancy or tri-plane representations, which are common in prior work. This holistic encoding strategy aggressively compresses the visual input for the downstream Large Language Model (LLM) based policy model. Evaluated on a large-scale proprietary dataset of 20,000 driving hours, our Flex achieves 2.2x greater inference throughput while improving driving performance by a large margin compared to state-of-the-art methods. Furthermore, we show that these compact scene tokens develop an emergent capability for scene decomposition without any explicit supervision. Our findings challenge the prevailing assumption that 3D priors are necessary, demonstrating that a data-driven, joint encoding strategy offers a more scalable, efficient and effective path for future autonomous driving systems.
Latent Chain-of-Thought World Modeling for End-to-End Driving
Dec 11, 2025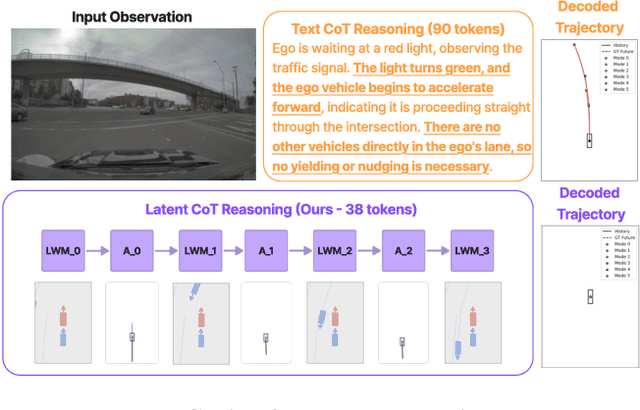
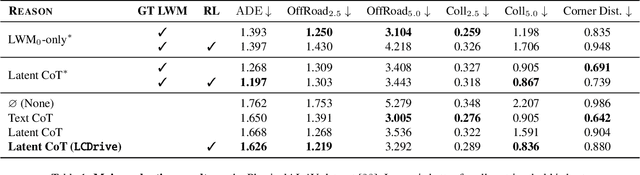
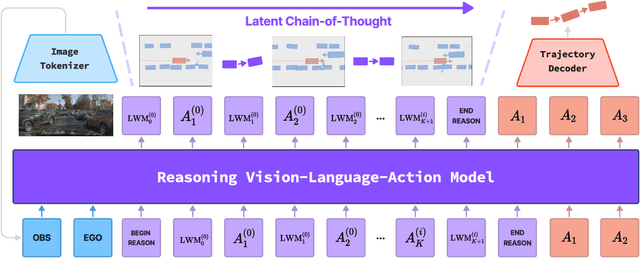
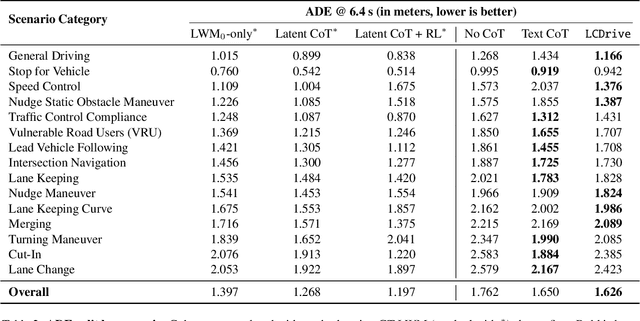
Recent Vision-Language-Action (VLA) models for autonomous driving explore inference-time reasoning as a way to improve driving performance and safety in challenging scenarios. Most prior work uses natural language to express chain-of-thought (CoT) reasoning before producing driving actions. However, text may not be the most efficient representation for reasoning. In this work, we present Latent-CoT-Drive (LCDrive): a model that expresses CoT in a latent language that captures possible outcomes of the driving actions being considered. Our approach unifies CoT reasoning and decision making by representing both in an action-aligned latent space. Instead of natural language, the model reasons by interleaving (1) action-proposal tokens, which use the same vocabulary as the model's output actions; and (2) world model tokens, which are grounded in a learned latent world model and express future outcomes of these actions. We cold start latent CoT by supervising the model's action proposals and world model tokens based on ground-truth future rollouts of the scene. We then post-train with closed-loop reinforcement learning to strengthen reasoning capabilities. On a large-scale end-to-end driving benchmark, LCDrive achieves faster inference, better trajectory quality, and larger improvements from interactive reinforcement learning compared to both non-reasoning and text-reasoning baselines.
Efficient Multi-Camera Tokenization with Triplanes for End-to-End Driving
Jun 13, 2025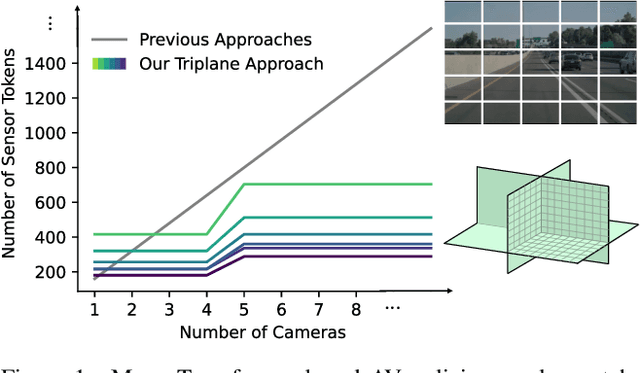
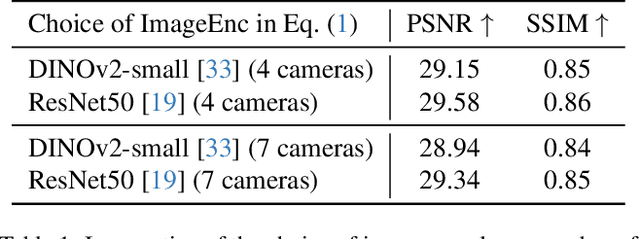
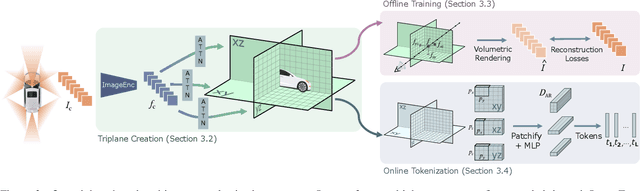
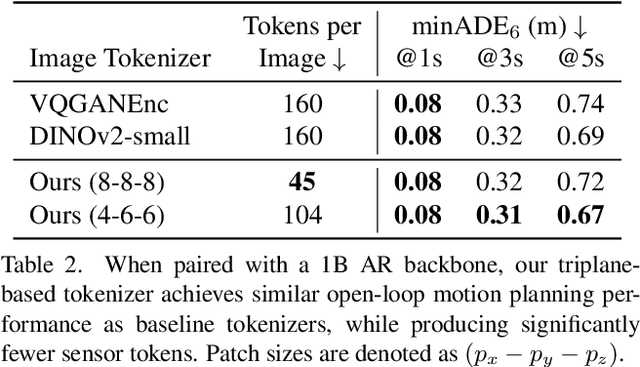
Autoregressive Transformers are increasingly being deployed as end-to-end robot and autonomous vehicle (AV) policy architectures, owing to their scalability and potential to leverage internet-scale pretraining for generalization. Accordingly, tokenizing sensor data efficiently is paramount to ensuring the real-time feasibility of such architectures on embedded hardware. To this end, we present an efficient triplane-based multi-camera tokenization strategy that leverages recent advances in 3D neural reconstruction and rendering to produce sensor tokens that are agnostic to the number of input cameras and their resolution, while explicitly accounting for their geometry around an AV. Experiments on a large-scale AV dataset and state-of-the-art neural simulator demonstrate that our approach yields significant savings over current image patch-based tokenization strategies, producing up to 72% fewer tokens, resulting in up to 50% faster policy inference while achieving the same open-loop motion planning accuracy and improved offroad rates in closed-loop driving simulations.
DreamDrive: Generative 4D Scene Modeling from Street View Images
Jan 03, 2025



Synthesizing photo-realistic visual observations from an ego vehicle's driving trajectory is a critical step towards scalable training of self-driving models. Reconstruction-based methods create 3D scenes from driving logs and synthesize geometry-consistent driving videos through neural rendering, but their dependence on costly object annotations limits their ability to generalize to in-the-wild driving scenarios. On the other hand, generative models can synthesize action-conditioned driving videos in a more generalizable way but often struggle with maintaining 3D visual consistency. In this paper, we present DreamDrive, a 4D spatial-temporal scene generation approach that combines the merits of generation and reconstruction, to synthesize generalizable 4D driving scenes and dynamic driving videos with 3D consistency. Specifically, we leverage the generative power of video diffusion models to synthesize a sequence of visual references and further elevate them to 4D with a novel hybrid Gaussian representation. Given a driving trajectory, we then render 3D-consistent driving videos via Gaussian splatting. The use of generative priors allows our method to produce high-quality 4D scenes from in-the-wild driving data, while neural rendering ensures 3D-consistent video generation from the 4D scenes. Extensive experiments on nuScenes and street view images demonstrate that DreamDrive can generate controllable and generalizable 4D driving scenes, synthesize novel views of driving videos with high fidelity and 3D consistency, decompose static and dynamic elements in a self-supervised manner, and enhance perception and planning tasks for autonomous driving.
STORM: Spatio-Temporal Reconstruction Model for Large-Scale Outdoor Scenes
Dec 31, 2024



We present STORM, a spatio-temporal reconstruction model designed for reconstructing dynamic outdoor scenes from sparse observations. Existing dynamic reconstruction methods often rely on per-scene optimization, dense observations across space and time, and strong motion supervision, resulting in lengthy optimization times, limited generalization to novel views or scenes, and degenerated quality caused by noisy pseudo-labels for dynamics. To address these challenges, STORM leverages a data-driven Transformer architecture that directly infers dynamic 3D scene representations--parameterized by 3D Gaussians and their velocities--in a single forward pass. Our key design is to aggregate 3D Gaussians from all frames using self-supervised scene flows, transforming them to the target timestep to enable complete (i.e., "amodal") reconstructions from arbitrary viewpoints at any moment in time. As an emergent property, STORM automatically captures dynamic instances and generates high-quality masks using only reconstruction losses. Extensive experiments on public datasets show that STORM achieves precise dynamic scene reconstruction, surpassing state-of-the-art per-scene optimization methods (+4.3 to 6.6 PSNR) and existing feed-forward approaches (+2.1 to 4.7 PSNR) in dynamic regions. STORM reconstructs large-scale outdoor scenes in 200ms, supports real-time rendering, and outperforms competitors in scene flow estimation, improving 3D EPE by 0.422m and Acc5 by 28.02%. Beyond reconstruction, we showcase four additional applications of our model, illustrating the potential of self-supervised learning for broader dynamic scene understanding.
Extrapolated Urban View Synthesis Benchmark
Dec 10, 2024



Photorealistic simulators are essential for the training and evaluation of vision-centric autonomous vehicles (AVs). At their core is Novel View Synthesis (NVS), a crucial capability that generates diverse unseen viewpoints to accommodate the broad and continuous pose distribution of AVs. Recent advances in radiance fields, such as 3D Gaussian Splatting, achieve photorealistic rendering at real-time speeds and have been widely used in modeling large-scale driving scenes. However, their performance is commonly evaluated using an interpolated setup with highly correlated training and test views. In contrast, extrapolation, where test views largely deviate from training views, remains underexplored, limiting progress in generalizable simulation technology. To address this gap, we leverage publicly available AV datasets with multiple traversals, multiple vehicles, and multiple cameras to build the first Extrapolated Urban View Synthesis (EUVS) benchmark. Meanwhile, we conduct quantitative and qualitative evaluations of state-of-the-art Gaussian Splatting methods across different difficulty levels. Our results show that Gaussian Splatting is prone to overfitting to training views. Besides, incorporating diffusion priors and improving geometry cannot fundamentally improve NVS under large view changes, highlighting the need for more robust approaches and large-scale training. We have released our data to help advance self-driving and urban robotics simulation technology.