 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Speeding Up Language Model Evaluation
Jul 08, 2024Large language models (LLMs) currently dominate the field of natural language processing (NLP), representing the state-of-the-art across a diverse array of tasks. Developing a model of this nature, from training to inference, requires making numerous decisions which define a combinatorial search problem. For example, selecting the optimal pre-trained LLM, prompt, or hyperparameters to attain the best performance for a task often requires evaluating multiple candidates on an entire test set. This exhaustive evaluation can be time-consuming and costly, as both inference and metric computation with LLMs are resource-intensive. In this paper, we address the challenge of identifying the best method within a limited budget for evaluating methods on test examples. By leveraging the well-studied multi-armed bandit framework, which sequentially selects the next method-example pair to evaluate, our approach, combining multi-armed bandit algorithms with low-rank factorization, significantly reduces the required resources. Experiments show that our algorithms can identify the top-performing method using only 5-15\% of the typically needed resources, resulting in an 85-95\% reduction in cost.
Unsupervised Domain Adaptation for Self-Driving from Past Traversal Features
Sep 21, 2023The rapid development of 3D object detection systems for self-driving cars has significantly improved accuracy. However, these systems struggle to generalize across diverse driving environments, which can lead to safety-critical failures in detecting traffic participants. To address this, we propose a method that utilizes unlabeled repeated traversals of multiple locations to adapt object detectors to new driving environments. By incorporating statistics computed from repeated LiDAR scans, we guide the adaptation process effectively. Our approach enhances LiDAR-based detection models using spatial quantized historical features and introduces a lightweight regression head to leverage the statistics for feature regularization. Additionally, we leverage the statistics for a novel self-training process to stabilize the training. The framework is detector model-agnostic and experiments on real-world datasets demonstrate significant improvements, achieving up to a 20-point performance gain, especially in detecting pedestrians and distant objects. Code is available at https://github.com/zhangtravis/Hist-DA.
Unsupervised Adaptation from Repeated Traversals for Autonomous Driving
Mar 27, 2023For a self-driving car to operate reliably, its perceptual system must generalize to the end-user's environment -- ideally without additional annotation efforts. One potential solution is to leverage unlabeled data (e.g., unlabeled LiDAR point clouds) collected from the end-users' environments (i.e. target domain) to adapt the system to the difference between training and testing environments. While extensive research has been done on such an unsupervised domain adaptation problem, one fundamental problem lingers: there is no reliable signal in the target domain to supervise the adaptation process. To overcome this issue we observe that it is easy to collect unsupervised data from multiple traversals of repeated routes. While different from conventional unsupervised domain adaptation, this assumption is extremely realistic since many drivers share the same roads. We show that this simple additional assumption is sufficient to obtain a potent signal that allows us to perform iterative self-training of 3D object detectors on the target domain. Concretely, we generate pseudo-labels with the out-of-domain detector but reduce false positives by removing detections of supposedly mobile objects that are persistent across traversals. Further, we reduce false negatives by encouraging predictions in regions that are not persistent. We experiment with our approach on two large-scale driving datasets and show remarkable improvement in 3D object detection of cars, pedestrians, and cyclists, bringing us a step closer to generalizable autonomous driving.
Targeted Attack on Deep RL-based Autonomous Driving with Learned Visual Patterns
Sep 16, 2021
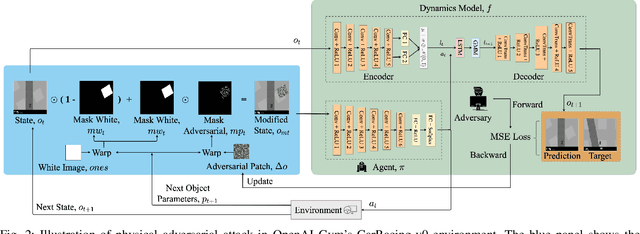
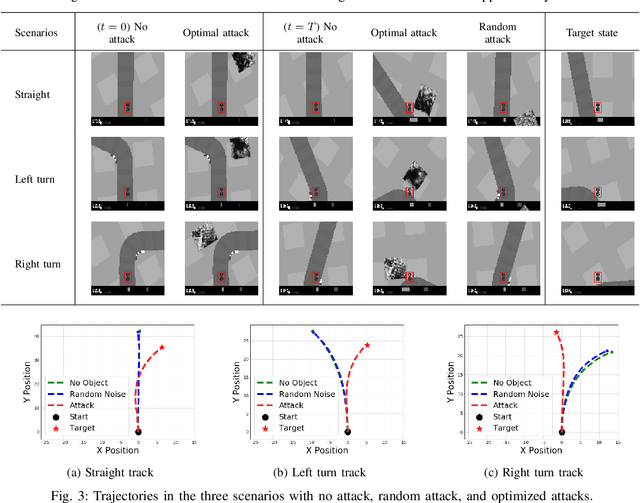
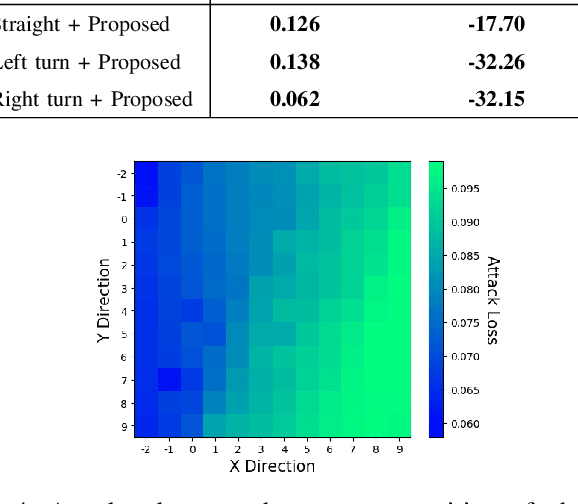
Recent studies demonstrated the vulnerability of control policies learned through deep reinforcement learning against adversarial attacks, raising concerns about the application of such models to risk-sensitive tasks such as autonomous driving. Threat models for these demonstrations are limited to (1) targeted attacks through real-time manipulation of the agent's observation, and (2) untargeted attacks through manipulation of the physical environment. The former assumes full access to the agent's states/observations at all times, while the latter has no control over attack outcomes. This paper investigates the feasibility of targeted attacks through visually learned patterns placed on physical object in the environment, a threat model that combines the practicality and effectiveness of the existing ones. Through analysis, we demonstrate that a pre-trained policy can be hijacked within a time window, e.g., performing an unintended self-parking, when an adversarial object is present. To enable the attack, we adopt an assumption that the dynamics of both the environment and the agent can be learned by the attacker. Lastly, we empirically show the effectiveness of the proposed attack on different driving scenarios, perform a location robustness test, and study the tradeoff between the attack strength and its effectiveness.