 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Feasibility and Opportunity of Autoregressive 3D Object Detection
Mar 09, 2026LiDAR-based 3D object detectors typically rely on proposal heads with hand-crafted components like anchor assignment and non-maximum suppression (NMS), complicating training and limiting extensibility. We present AutoReg3D, an autoregressive 3D detector that casts detection as sequence generation. Given point-cloud features, AutoReg3D emits objects in a range-causal (near-to-far) order and encodes each object as a short, discrete-token sequence consisting of its center, size, orientation, velocity, and class. This near-to-far ordering mirrors LiDAR geometry--near objects occlude far ones but not vice versa--enabling straightforward teacher forcing during training and autoregressive decoding at test time. AutoReg3D is compatible across diverse point-cloud or backbones and attains competitive nuScenes performance without anchors or NMS. Beyond parity, the sequential formulation unlocks language-model advances for 3D perception, including GRPO-style reinforcement learning for task-aligned objectives. These results position autoregressive decoding as a viable, flexible alternative for LiDAR-based detection and open a path to importing modern sequence-modeling tools into 3D perception.
Benchmark Datasets for Lead-Lag Forecasting on Social Platforms
Nov 05, 2025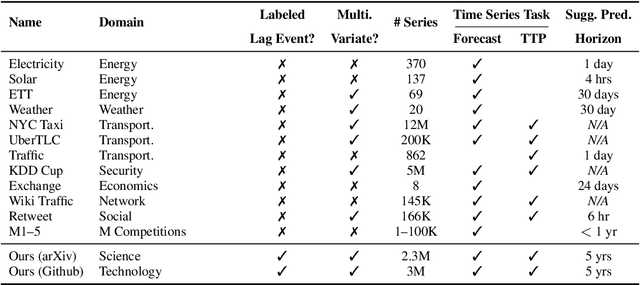
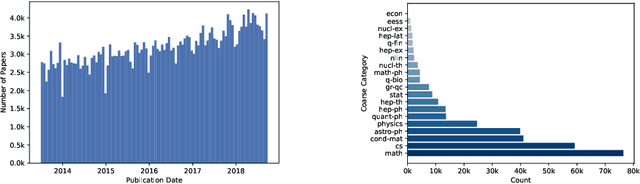
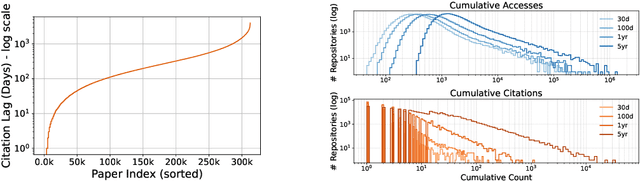
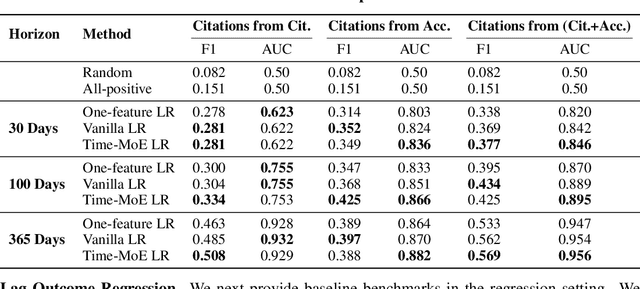
Social and collaborative platforms emit multivariate time-series traces in which early interactions-such as views, likes, or downloads-are followed, sometimes months or years later, by higher impact like citations, sales, or reviews. We formalize this setting as Lead-Lag Forecasting (LLF): given an early usage channel (the lead), predict a correlated but temporally shifted outcome channel (the lag). Despite the ubiquity of such patterns, LLF has not been treated as a unified forecasting problem within the time-series community, largely due to the absence of standardized datasets. To anchor research in LLF, here we present two high-volume benchmark datasets-arXiv (accesses -> citations of 2.3M papers) and GitHub (pushes/stars -> forks of 3M repositories)-and outline additional domains with analogous lead-lag dynamics, including Wikipedia (page views -> edits), Spotify (streams -> concert attendance), e-commerce (click-throughs -> purchases), and LinkedIn profile (views -> messages). Our datasets provide ideal testbeds for lead-lag forecasting, by capturing long-horizon dynamics across years, spanning the full spectrum of outcomes, and avoiding survivorship bias in sampling. We documented all technical details of data curation and cleaning, verified the presence of lead-lag dynamics through statistical and classification tests, and benchmarked parametric and non-parametric baselines for regression. Our study establishes LLF as a novel forecasting paradigm and lays an empirical foundation for its systematic exploration in social and usage data. Our data portal with downloads and documentation is available at https://lead-lag-forecasting.github.io/.
Better Monocular 3D Detectors with LiDAR from the Past
Apr 09, 2024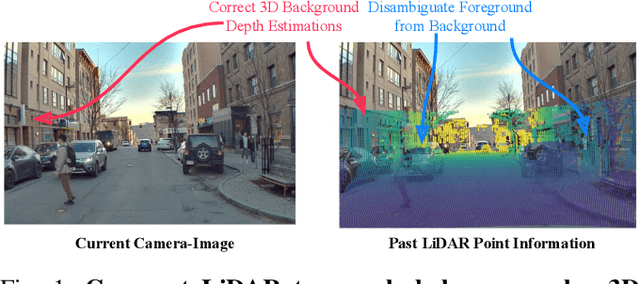
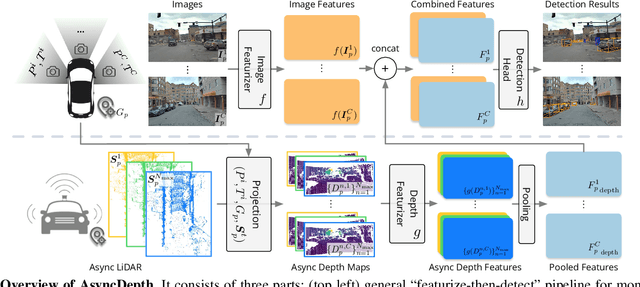
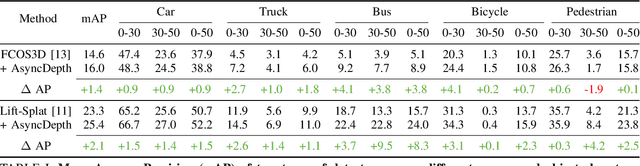
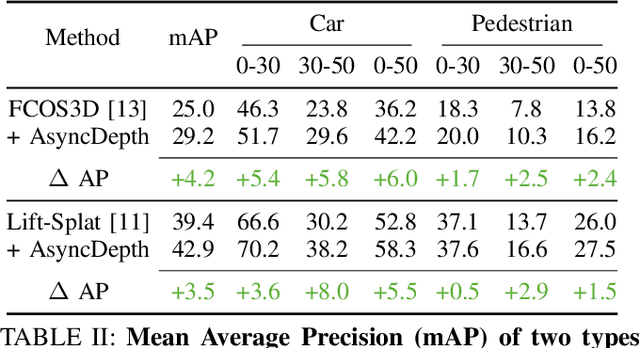
Accurate 3D object detection is crucial to autonomous driving. Though LiDAR-based detectors have achieved impressive performance, the high cost of LiDAR sensors precludes their widespread adoption in affordable vehicles. Camera-based detectors are cheaper alternatives but often suffer inferior performance compared to their LiDAR-based counterparts due to inherent depth ambiguities in images. In this work, we seek to improve monocular 3D detectors by leveraging unlabeled historical LiDAR data. Specifically, at inference time, we assume that the camera-based detectors have access to multiple unlabeled LiDAR scans from past traversals at locations of interest (potentially from other high-end vehicles equipped with LiDAR sensors). Under this setup, we proposed a novel, simple, and end-to-end trainable framework, termed AsyncDepth, to effectively extract relevant features from asynchronous LiDAR traversals of the same location for monocular 3D detectors. We show consistent and significant performance gain (up to 9 AP) across multiple state-of-the-art models and datasets with a negligible additional latency of 9.66 ms and a small storage cost.
Denoising Vision Transformers
Jan 05, 2024
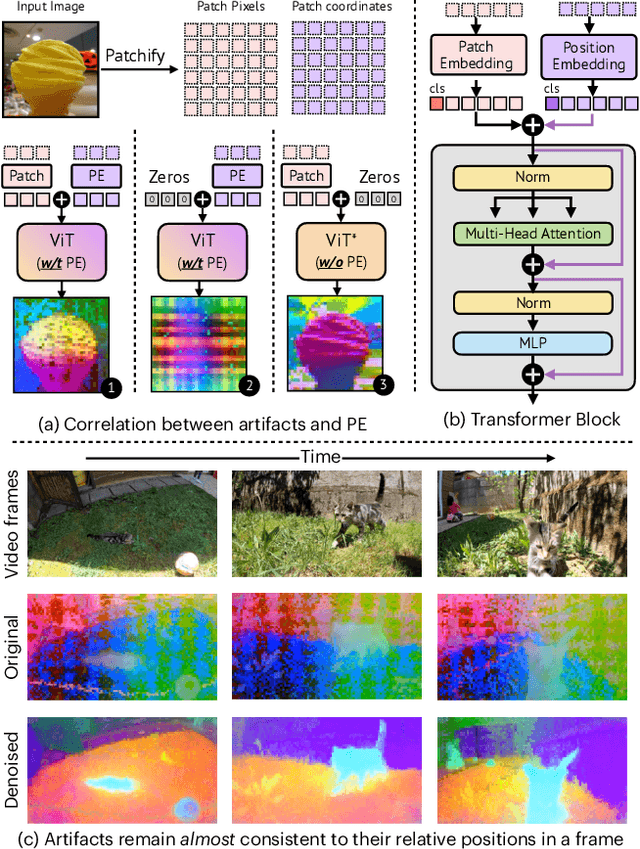
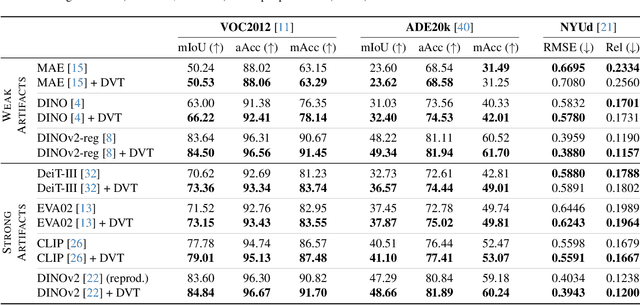
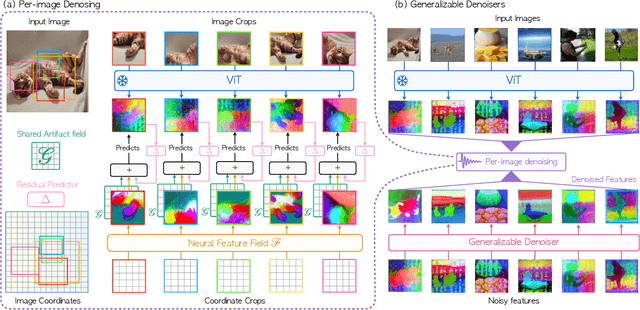
We delve into a nuanced but significant challenge inherent to Vision Transformers (ViTs): feature maps of these models exhibit grid-like artifacts, which detrimentally hurt the performance of ViTs in downstream tasks. Our investigations trace this fundamental issue down to the positional embeddings at the input stage. To address this, we propose a novel noise model, which is universally applicable to all ViTs. Specifically, the noise model dissects ViT outputs into three components: a semantics term free from noise artifacts and two artifact-related terms that are conditioned on pixel locations. Such a decomposition is achieved by enforcing cross-view feature consistency with neural fields in a per-image basis. This per-image optimization process extracts artifact-free features from raw ViT outputs, providing clean features for offline applications. Expanding the scope of our solution to support online functionality, we introduce a learnable denoiser to predict artifact-free features directly from unprocessed ViT outputs, which shows remarkable generalization capabilities to novel data without the need for per-image optimization. Our two-stage approach, termed Denoising Vision Transformers (DVT), does not require re-training existing pre-trained ViTs and is immediately applicable to any Transformer-based architecture. We evaluate our method on a variety of representative ViTs (DINO, MAE, DeiT-III, EVA02, CLIP, DINOv2, DINOv2-reg). Extensive evaluations demonstrate that our DVT consistently and significantly improves existing state-of-the-art general-purpose models in semantic and geometric tasks across multiple datasets (e.g., +3.84 mIoU). We hope our study will encourage a re-evaluation of ViT design, especially regarding the naive use of positional embeddings.
Augmenting Lane Perception and Topology Understanding with Standard Definition Navigation Maps
Nov 07, 2023Autonomous driving has traditionally relied heavily on costly and labor-intensive High Definition (HD) maps, hindering scalability. In contrast, Standard Definition (SD) maps are more affordable and have worldwide coverage, offering a scalable alternative. In this work, we systematically explore the effect of SD maps for real-time lane-topology understanding. We propose a novel framework to integrate SD maps into online map prediction and propose a Transformer-based encoder, SD Map Encoder Representations from transFormers, to leverage priors in SD maps for the lane-topology prediction task. This enhancement consistently and significantly boosts (by up to 60%) lane detection and topology prediction on current state-of-the-art online map prediction methods without bells and whistles and can be immediately incorporated into any Transformer-based lane-topology method. Code is available at https://github.com/NVlabs/SMERF.
Learning Iterative Neural Optimizers for Image Steganography
Mar 27, 2023



Image steganography is the process of concealing secret information in images through imperceptible changes. Recent work has formulated this task as a classic constrained optimization problem. In this paper, we argue that image steganography is inherently performed on the (elusive) manifold of natural images, and propose an iterative neural network trained to perform the optimization steps. In contrast to classical optimization methods like L-BFGS or projected gradient descent, we train the neural network to also stay close to the manifold of natural images throughout the optimization. We show that our learned neural optimization is faster and more reliable than classical optimization approaches. In comparison to previous state-of-the-art encoder-decoder-based steganography methods, it reduces the recovery error rate by multiple orders of magnitude and achieves zero error up to 3 bits per pixel (bpp) without the need for error-correcting codes.
Image-to-Image Translation for Autonomous Driving from Coarsely-Aligned Image Pairs
Sep 23, 2022
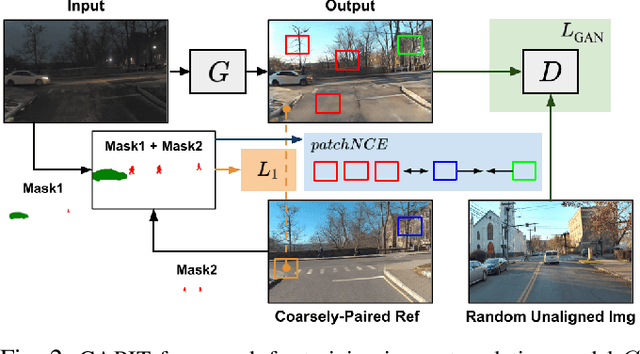

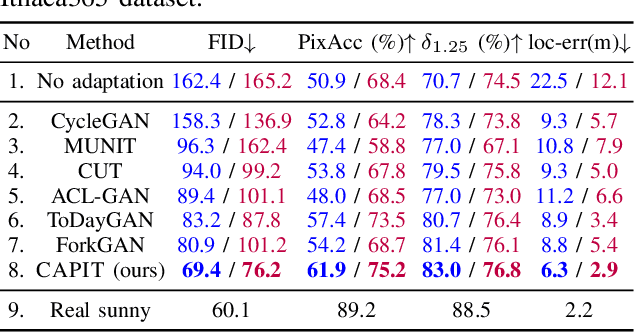
A self-driving car must be able to reliably handle adverse weather conditions (e.g., snowy) to operate safely. In this paper, we investigate the idea of turning sensor inputs (i.e., images) captured in an adverse condition into a benign one (i.e., sunny), upon which the downstream tasks (e.g., semantic segmentation) can attain high accuracy. Prior work primarily formulates this as an unpaired image-to-image translation problem due to the lack of paired images captured under the exact same camera poses and semantic layouts. While perfectly-aligned images are not available, one can easily obtain coarsely-paired images. For instance, many people drive the same routes daily in both good and adverse weather; thus, images captured at close-by GPS locations can form a pair. Though data from repeated traversals are unlikely to capture the same foreground objects, we posit that they provide rich contextual information to supervise the image translation model. To this end, we propose a novel training objective leveraging coarsely-aligned image pairs. We show that our coarsely-aligned training scheme leads to a better image translation quality and improved downstream tasks, such as semantic segmentation, monocular depth estimation, and visual localization.
Exploiting Playbacks in Unsupervised Domain Adaptation for 3D Object Detection
Mar 26, 2021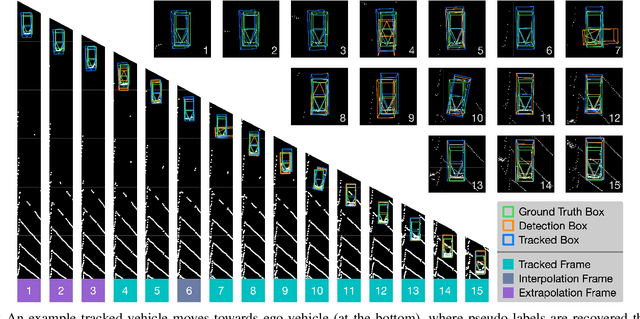


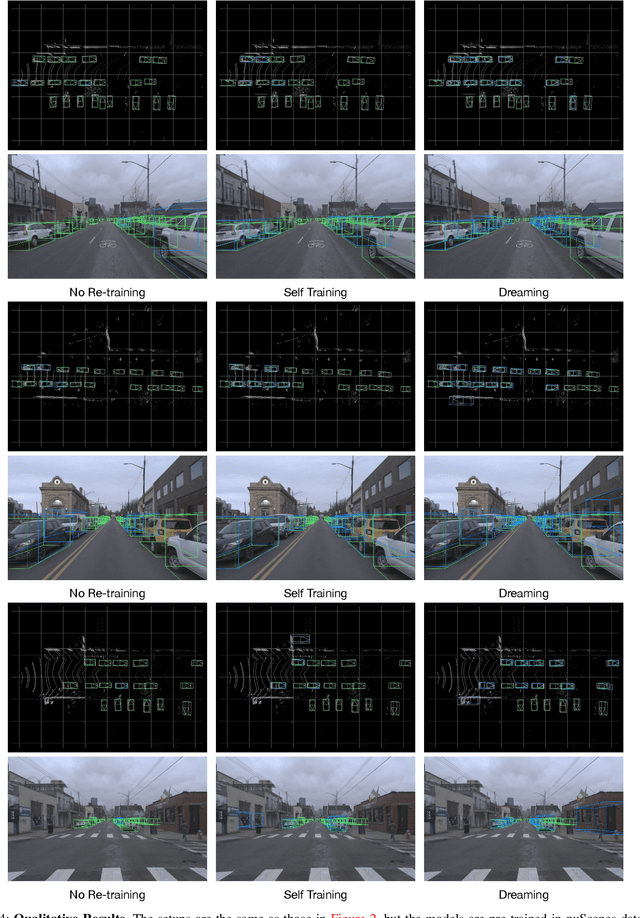
Self-driving cars must detect other vehicles and pedestrians in 3D to plan safe routes and avoid collisions. State-of-the-art 3D object detectors, based on deep learning, have shown promising accuracy but are prone to over-fit to domain idiosyncrasies, making them fail in new environments -- a serious problem if autonomous vehicles are meant to operate freely. In this paper, we propose a novel learning approach that drastically reduces this gap by fine-tuning the detector on pseudo-labels in the target domain, which our method generates while the vehicle is parked, based on replays of previously recorded driving sequences. In these replays, objects are tracked over time, and detections are interpolated and extrapolated -- crucially, leveraging future information to catch hard cases. We show, on five autonomous driving datasets, that fine-tuning the object detector on these pseudo-labels substantially reduces the domain gap to new driving environments, yielding drastic improvements in accuracy and detection reliability.