 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Uncertainty Quantification of Prediction Models with Application to Visual Localization
May 31, 2023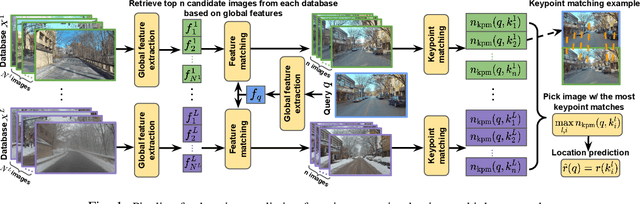



The uncertainty quantification of prediction models (e.g., neural networks) is crucial for their adoption in many robotics applications. This is arguably as important as making accurate predictions, especially for safety-critical applications such as self-driving cars. This paper proposes our approach to uncertainty quantification in the context of visual localization for autonomous driving, where we predict locations from images. Our proposed framework estimates probabilistic uncertainty by creating a sensor error model that maps an internal output of the prediction model to the uncertainty. The sensor error model is created using multiple image databases of visual localization, each with ground-truth location. We demonstrate the accuracy of our uncertainty prediction framework using the Ithaca365 dataset, which includes variations in lighting, weather (sunny, snowy, night), and alignment errors between databases. We analyze both the predicted uncertainty and its incorporation into a Kalman-based localization filter. Our results show that prediction error variations increase with poor weather and lighting condition, leading to greater uncertainty and outliers, which can be predicted by our proposed uncertainty model. Additionally, our probabilistic error model enables the filter to remove ad hoc sensor gating, as the uncertainty automatically adjusts the model to the input data
Vision-based Vineyard Navigation Solution with Automatic Annotation
Mar 25, 2023



Autonomous navigation is the key to achieving the full automation of agricultural research and production management (e.g., disease management and yield prediction) using agricultural robots. In this paper, we introduced a vision-based autonomous navigation framework for agriculture robots in trellised cropping systems such as vineyards. To achieve this, we proposed a novel learning-based method to estimate the path traversibility heatmap directly from an RGB-D image and subsequently convert the heatmap to a preferred traversal path. An automatic annotation pipeline was developed to form a training dataset by projecting RTK GPS paths collected during the first setup in a vineyard in corresponding RGB-D images as ground-truth path annotations, allowing a fast model training and fine-tuning without costly human annotation. The trained path detection model was used to develop a full navigation framework consisting of row tracking and row switching modules, enabling a robot to traverse within a crop row and transit between crop rows to cover an entire vineyard autonomously. Extensive field trials were conducted in three different vineyards to demonstrate that the developed path detection model and navigation framework provided a cost-effective, accurate, and robust autonomous navigation solution in the vineyard and could be generalized to unseen vineyards with stable performance.
Image-to-Image Translation for Autonomous Driving from Coarsely-Aligned Image Pairs
Sep 23, 2022
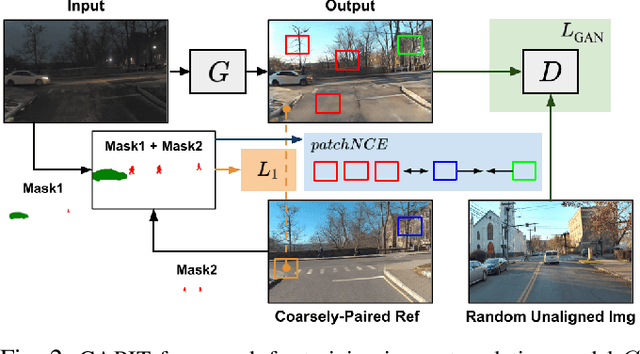

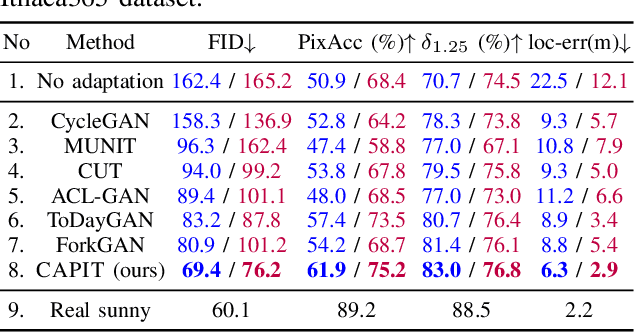
A self-driving car must be able to reliably handle adverse weather conditions (e.g., snowy) to operate safely. In this paper, we investigate the idea of turning sensor inputs (i.e., images) captured in an adverse condition into a benign one (i.e., sunny), upon which the downstream tasks (e.g., semantic segmentation) can attain high accuracy. Prior work primarily formulates this as an unpaired image-to-image translation problem due to the lack of paired images captured under the exact same camera poses and semantic layouts. While perfectly-aligned images are not available, one can easily obtain coarsely-paired images. For instance, many people drive the same routes daily in both good and adverse weather; thus, images captured at close-by GPS locations can form a pair. Though data from repeated traversals are unlikely to capture the same foreground objects, we posit that they provide rich contextual information to supervise the image translation model. To this end, we propose a novel training objective leveraging coarsely-aligned image pairs. We show that our coarsely-aligned training scheme leads to a better image translation quality and improved downstream tasks, such as semantic segmentation, monocular depth estimation, and visual localization.
Ithaca365: Dataset and Driving Perception under Repeated and Challenging Weather Conditions
Aug 01, 2022
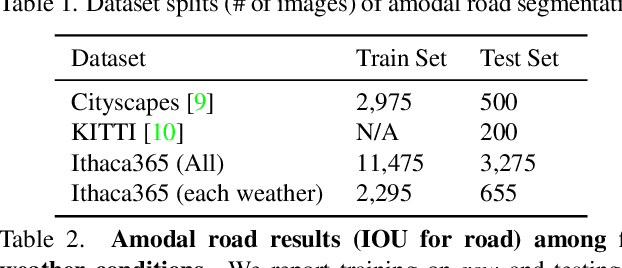
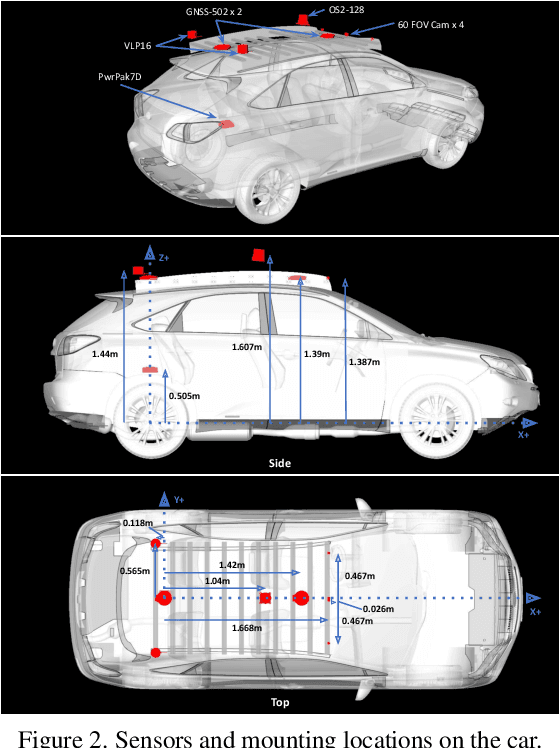
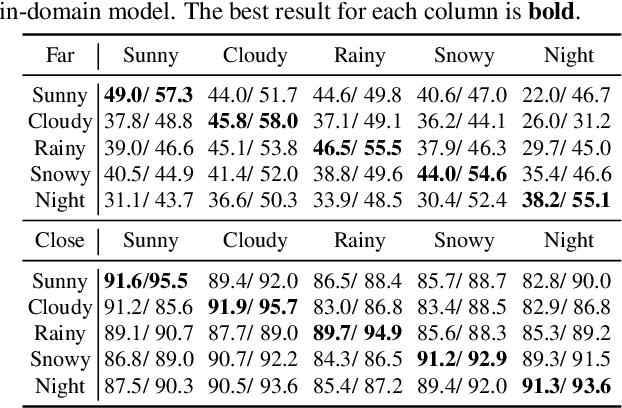
Advances in perception for self-driving cars have accelerated in recent years due to the availability of large-scale datasets, typically collected at specific locations and under nice weather conditions. Yet, to achieve the high safety requirement, these perceptual systems must operate robustly under a wide variety of weather conditions including snow and rain. In this paper, we present a new dataset to enable robust autonomous driving via a novel data collection process - data is repeatedly recorded along a 15 km route under diverse scene (urban, highway, rural, campus), weather (snow, rain, sun), time (day/night), and traffic conditions (pedestrians, cyclists and cars). The dataset includes images and point clouds from cameras and LiDAR sensors, along with high-precision GPS/INS to establish correspondence across routes. The dataset includes road and object annotations using amodal masks to capture partial occlusions and 3D bounding boxes. We demonstrate the uniqueness of this dataset by analyzing the performance of baselines in amodal segmentation of road and objects, depth estimation, and 3D object detection. The repeated routes opens new research directions in object discovery, continual learning, and anomaly detection. Link to Ithaca365: https://ithaca365.mae.cornell.edu/
Sequential Joint Shape and Pose Estimation of Vehicles with Application to Automatic Amodal Segmentation Labeling
Sep 20, 2021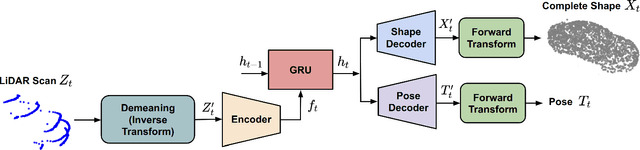

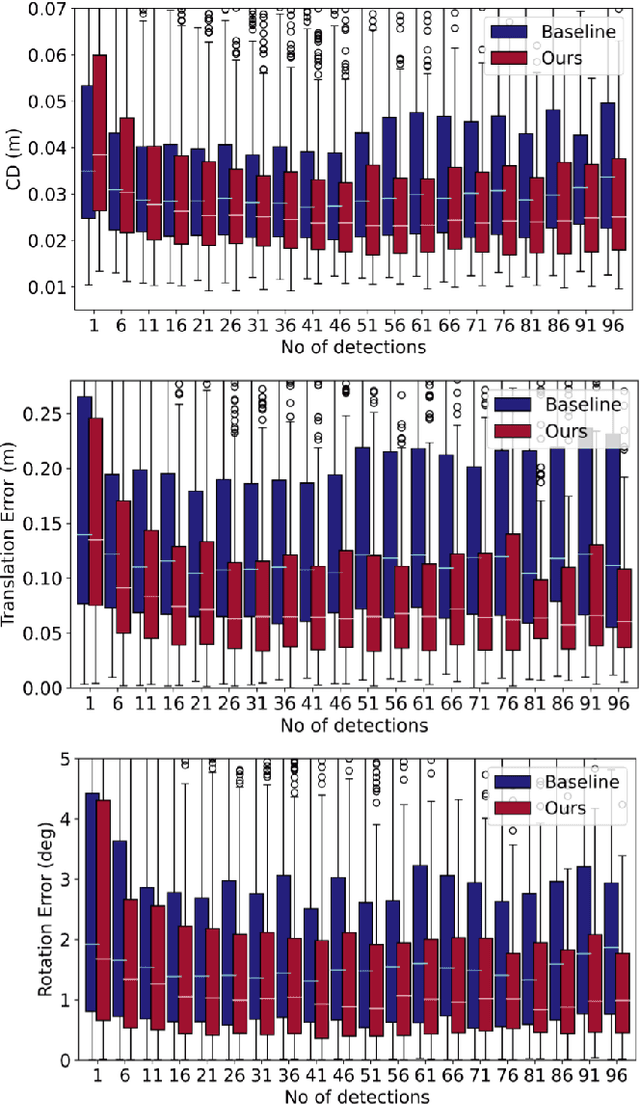

Shape and pose estimation is a critical perception problem for a self-driving car to fully understand its surrounding environment. One fundamental challenge in solving this problem is the incomplete sensor signal (e.g., LiDAR scans), especially for faraway or occluded objects. In this paper, we propose a novel algorithm to address this challenge, we explicitly leverage the sensor signal captured over consecutive time: the consecutive signals can provide more information of an object, including different viewpoints and its motion. By encoding the consecutive signal via a recurrent neural network, our algorithm not only improves shape and pose estimation, but also produces a labeling tool that can benefit other tasks in autonomous driving research. Specifically, building upon our algorithm, we propose a novel pipeline to automatically annotate high-quality labels for amodal segmentation on images, which are hard and laborious to annotate manually. Our code and data will be made publicly available.