 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSR: Pushing the Limit of Spatial Intelligence with Structured Scene Reasoning
Feb 28, 2026While Multimodal Large Language Models (MLLMs) excel in semantic tasks, they frequently lack the "spatial sense" essential for sophisticated geometric reasoning. Current models typically suffer from exorbitant modality-alignment costs and deficiency in fine-grained structural modeling precision.We introduce SSR, a framework designed for Structured Scene Reasoning that seamlessly integrates 2D and 3D representations via a lightweight alignment mechanism. To minimize training overhead, our framework anchors 3D geometric features to the large language model's pre-aligned 2D visual semantics through cross-modal addition and token interleaving, effectively obviating the necessity for large-scale alignment pre-training. To underpin complex spatial reasoning, we propose a novel scene graph generation pipeline that represents global layouts as a chain of independent local triplets defined by relative coordinates. This is complemented by an incremental generation algorithm, enabling the model to construct "language-model-friendly" structural scaffolds for complex environments. Furthermore, we extend these capabilities to global-scale 3D global grounding task, achieving absolute metric precision across heterogeneous data sources. At a 7B parameter scale, SSR achieves state-of-the-art performance on multiple spatial intelligence benchmarks, notably scoring 73.9 on VSI-Bench. Our approach significantly outperforms much larger models, demonstrating that efficient feature alignment and structured scene reasoning are the cornerstones of authentic spatial intelligence.
Planning Paths through Occlusions in Urban Environments
Dec 29, 2022



This paper presents a novel framework for planning in unknown and occluded urban spaces. We specifically focus on turns and intersections where occlusions significantly impact navigability. Our approach uses an inpainting model to fill in a sparse, occluded, semantic lidar point cloud and plans dynamically feasible paths for a vehicle to traverse through the open and inpainted spaces. We demonstrate our approach using a car's lidar data with real-time occlusions, and show that by inpainting occluded areas, we can plan longer paths, with more turn options compared to without inpainting; in addition, our approach more closely follows paths derived from a planner with no occlusions (called the ground truth) compared to other state of the art approaches.
Image-to-Image Translation for Autonomous Driving from Coarsely-Aligned Image Pairs
Sep 23, 2022
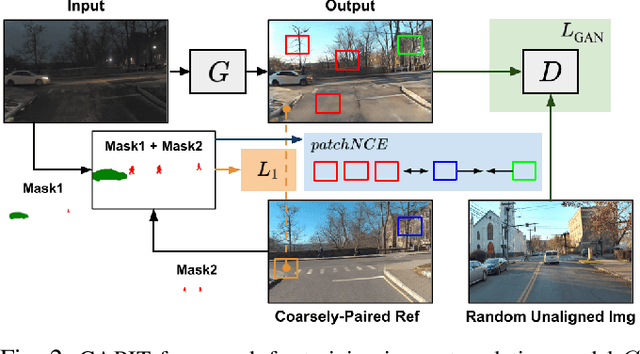

A self-driving car must be able to reliably handle adverse weather conditions (e.g., snowy) to operate safely. In this paper, we investigate the idea of turning sensor inputs (i.e., images) captured in an adverse condition into a benign one (i.e., sunny), upon which the downstream tasks (e.g., semantic segmentation) can attain high accuracy. Prior work primarily formulates this as an unpaired image-to-image translation problem due to the lack of paired images captured under the exact same camera poses and semantic layouts. While perfectly-aligned images are not available, one can easily obtain coarsely-paired images. For instance, many people drive the same routes daily in both good and adverse weather; thus, images captured at close-by GPS locations can form a pair. Though data from repeated traversals are unlikely to capture the same foreground objects, we posit that they provide rich contextual information to supervise the image translation model. To this end, we propose a novel training objective leveraging coarsely-aligned image pairs. We show that our coarsely-aligned training scheme leads to a better image translation quality and improved downstream tasks, such as semantic segmentation, monocular depth estimation, and visual localization.
Ithaca365: Dataset and Driving Perception under Repeated and Challenging Weather Conditions
Aug 01, 2022
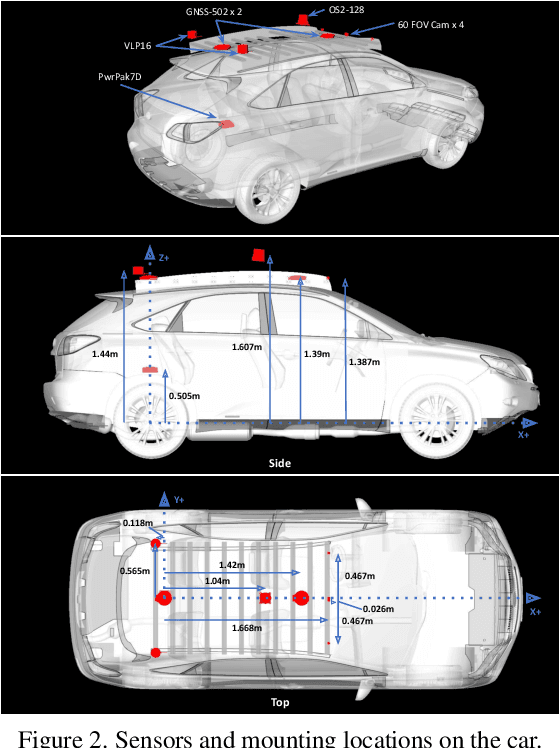
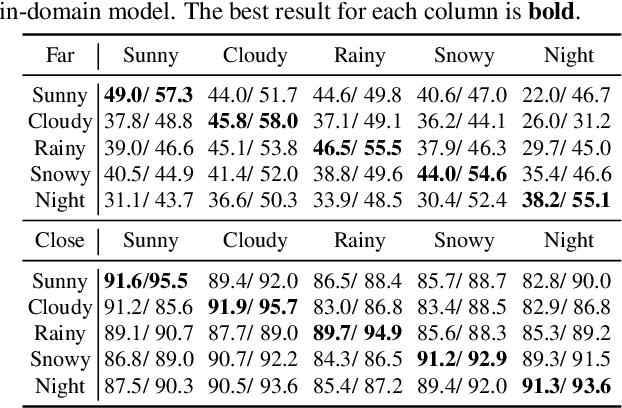
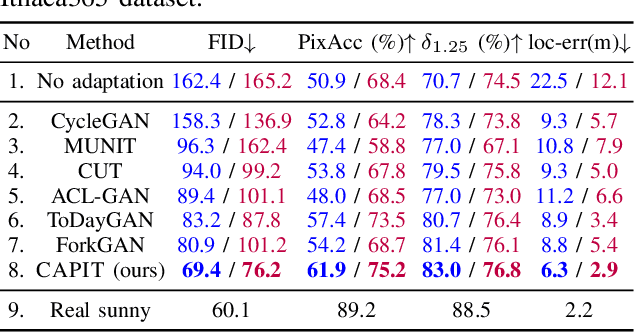
Advances in perception for self-driving cars have accelerated in recent years due to the availability of large-scale datasets, typically collected at specific locations and under nice weather conditions. Yet, to achieve the high safety requirement, these perceptual systems must operate robustly under a wide variety of weather conditions including snow and rain. In this paper, we present a new dataset to enable robust autonomous driving via a novel data collection process - data is repeatedly recorded along a 15 km route under diverse scene (urban, highway, rural, campus), weather (snow, rain, sun), time (day/night), and traffic conditions (pedestrians, cyclists and cars). The dataset includes images and point clouds from cameras and LiDAR sensors, along with high-precision GPS/INS to establish correspondence across routes. The dataset includes road and object annotations using amodal masks to capture partial occlusions and 3D bounding boxes. We demonstrate the uniqueness of this dataset by analyzing the performance of baselines in amodal segmentation of road and objects, depth estimation, and 3D object detection. The repeated routes opens new research directions in object discovery, continual learning, and anomaly detection. Link to Ithaca365: https://ithaca365.mae.cornell.edu/
Privacy-Preserving Pose Estimation for Human-Robot Interaction
Nov 14, 2020
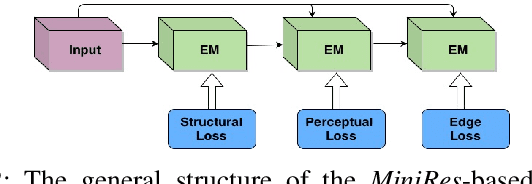


Pose estimation is an important technique for nonverbal human-robot interaction. That said, the presence of a camera in a person's space raises privacy concerns and could lead to distrust of the robot. In this paper, we propose a privacy-preserving camera-based pose estimation method. The proposed system consists of a user-controlled translucent filter that covers the camera and an image enhancement module designed to facilitate pose estimation from the filtered (shadow) images, while never capturing clear images of the user. We evaluate the system's performance on a new filtered image dataset, considering the effects of distance from the camera, background clutter, and film thickness. Based on our findings, we conclude that our system can protect humans' privacy while detecting humans' pose information effectively.
Fast Underwater Image Enhancement for Improved Visual Perception
Mar 23, 2019
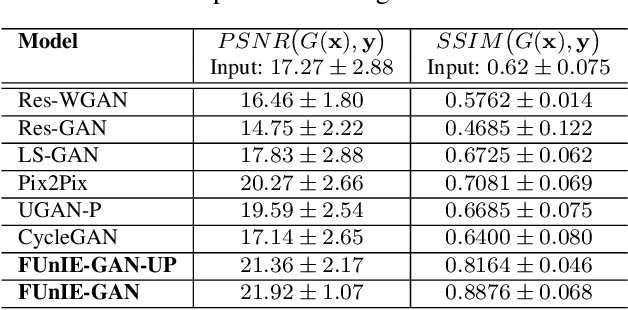

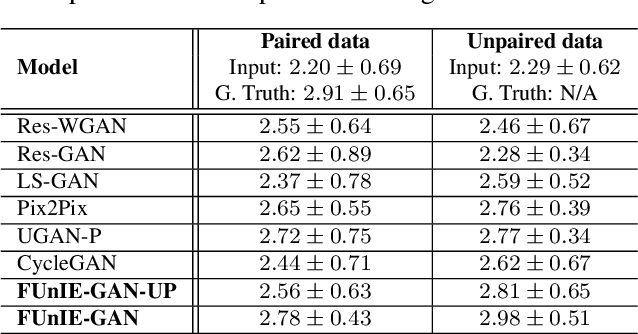
In this paper, we present a conditional generative adversarial network-based model for underwater image enhancement in real-time. In order to supervise the adversarial training, we formulate an objective function that evaluates the perceptual image quality based on its global content, color, and local style information. In addition, we present EUVP, a large-scale dataset of a paired and an unpaired collection of underwater images (of poor and good quality) that are captured using seven different cameras over various visibility conditions during oceanic explorations and human-robot collaborative experiments. Furthermore, we perform a number of qualitative and quantitative evaluations which suggest that the proposed model can learn to enhance the quality of underwater images from both paired and unpaired training. More importantly, the enhanced images provide improved performances for several standard models for underwater object detection and human pose estimation; hence, the proposed model can be used as an image processing pipeline by visually-guided underwater robots in real-time applications.
Visual Diver Recognition for Underwater Human-Robot Collaboration
Sep 19, 2018



This paper presents an approach for autonomous underwater robots to visually detect and identify divers. The proposed approach enables an autonomous underwater robot to detect multiple divers in a visual scene and distinguish between them. Such methods are useful for robots to identify a human leader, for example, in multi-human/robot teams where only designated individuals are allowed to command or lean a team of robots. Initial diver identification is performed using the Faster R-CNN algorithm with a region proposal network which produces bounding boxes around the divers' locations. Subsequently, a suite of spatial and frequency domain descriptors are extracted from the bounding boxes to create a feature vector. A K-Means clustering algorithm, with k set to the number of detected bounding boxes, thereafter identifies the detected divers based on these feature vectors. We evaluate the performance of the proposed approach on video footage of divers swimming in front of a mobile robot and demonstrate its accuracy.