 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge2D-3D Deformable Image Registration of Histology Slide and Micro-CT with ML-based Initialization
Oct 18, 2024Recent developments in the registration of histology and micro-computed tomography ({\mu}CT) have broadened the perspective of pathological applications such as virtual histology based on {\mu}CT. This topic remains challenging because of the low image quality of soft tissue CT. Additionally, soft tissue samples usually deform during the histology slide preparation, making it difficult to correlate the structures between histology slide and {\mu}CT. In this work, we propose a novel 2D-3D multi-modal deformable image registration method. The method uses a machine learning (ML) based initialization followed by the registration. The registration is finalized by an analytical out-of-plane deformation refinement. The method is evaluated on datasets acquired from tonsil and tumor tissues. {\mu}CTs of both phase-contrast and conventional absorption modalities are investigated. The registration results from the proposed method are compared with those from intensity- and keypoint-based methods. The comparison is conducted using both visual and fiducial-based evaluations. The proposed method demonstrates superior performance compared to the other two methods.
Probabilistic Uncertainty Quantification of Prediction Models with Application to Visual Localization
May 31, 2023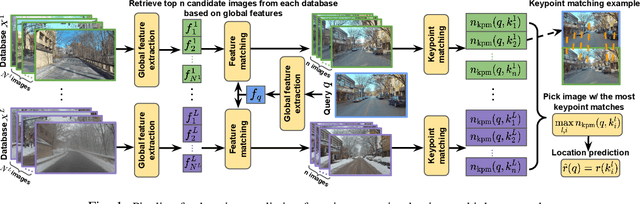



The uncertainty quantification of prediction models (e.g., neural networks) is crucial for their adoption in many robotics applications. This is arguably as important as making accurate predictions, especially for safety-critical applications such as self-driving cars. This paper proposes our approach to uncertainty quantification in the context of visual localization for autonomous driving, where we predict locations from images. Our proposed framework estimates probabilistic uncertainty by creating a sensor error model that maps an internal output of the prediction model to the uncertainty. The sensor error model is created using multiple image databases of visual localization, each with ground-truth location. We demonstrate the accuracy of our uncertainty prediction framework using the Ithaca365 dataset, which includes variations in lighting, weather (sunny, snowy, night), and alignment errors between databases. We analyze both the predicted uncertainty and its incorporation into a Kalman-based localization filter. Our results show that prediction error variations increase with poor weather and lighting condition, leading to greater uncertainty and outliers, which can be predicted by our proposed uncertainty model. Additionally, our probabilistic error model enables the filter to remove ad hoc sensor gating, as the uncertainty automatically adjusts the model to the input data
Ithaca365: Dataset and Driving Perception under Repeated and Challenging Weather Conditions
Aug 01, 2022
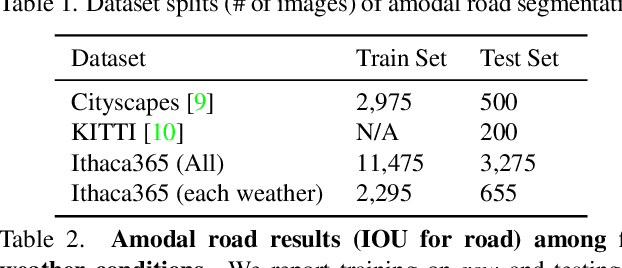
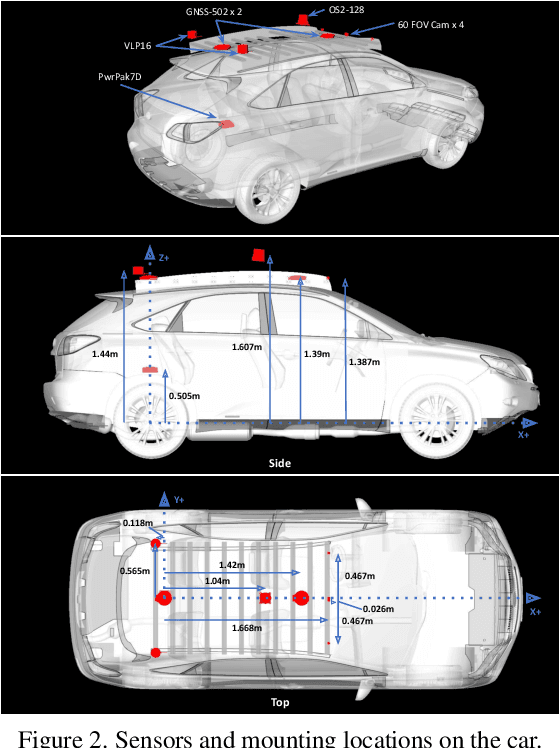
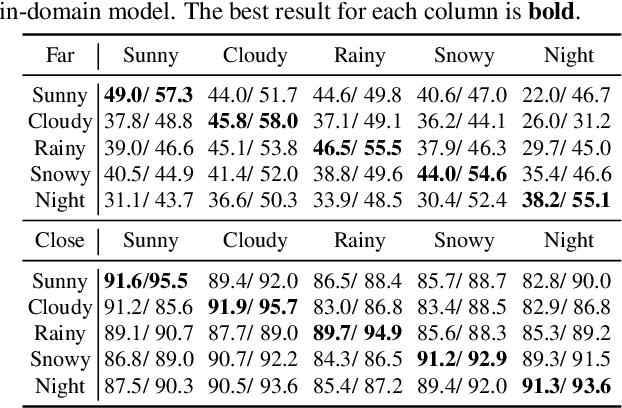
Advances in perception for self-driving cars have accelerated in recent years due to the availability of large-scale datasets, typically collected at specific locations and under nice weather conditions. Yet, to achieve the high safety requirement, these perceptual systems must operate robustly under a wide variety of weather conditions including snow and rain. In this paper, we present a new dataset to enable robust autonomous driving via a novel data collection process - data is repeatedly recorded along a 15 km route under diverse scene (urban, highway, rural, campus), weather (snow, rain, sun), time (day/night), and traffic conditions (pedestrians, cyclists and cars). The dataset includes images and point clouds from cameras and LiDAR sensors, along with high-precision GPS/INS to establish correspondence across routes. The dataset includes road and object annotations using amodal masks to capture partial occlusions and 3D bounding boxes. We demonstrate the uniqueness of this dataset by analyzing the performance of baselines in amodal segmentation of road and objects, depth estimation, and 3D object detection. The repeated routes opens new research directions in object discovery, continual learning, and anomaly detection. Link to Ithaca365: https://ithaca365.mae.cornell.edu/
Hindsight is 20/20: Leveraging Past Traversals to Aid 3D Perception
Mar 22, 2022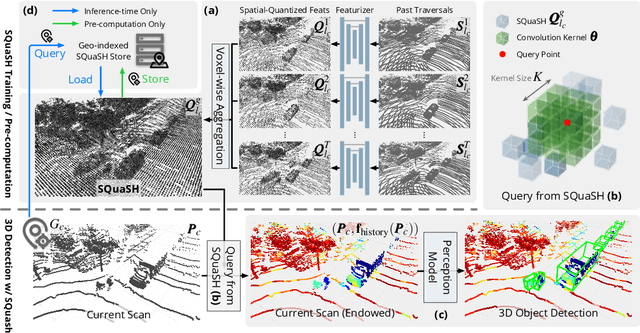



Self-driving cars must detect vehicles, pedestrians, and other traffic participants accurately to operate safely. Small, far-away, or highly occluded objects are particularly challenging because there is limited information in the LiDAR point clouds for detecting them. To address this challenge, we leverage valuable information from the past: in particular, data collected in past traversals of the same scene. We posit that these past data, which are typically discarded, provide rich contextual information for disambiguating the above-mentioned challenging cases. To this end, we propose a novel, end-to-end trainable Hindsight framework to extract this contextual information from past traversals and store it in an easy-to-query data structure, which can then be leveraged to aid future 3D object detection of the same scene. We show that this framework is compatible with most modern 3D detection architectures and can substantially improve their average precision on multiple autonomous driving datasets, most notably by more than 300% on the challenging cases.
Dual Learning-based Video Coding with Inception Dense Blocks
Nov 22, 2019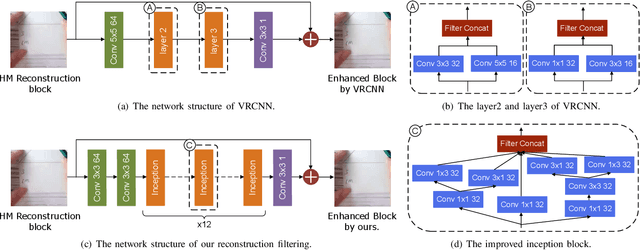

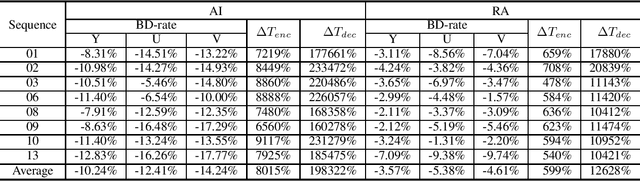
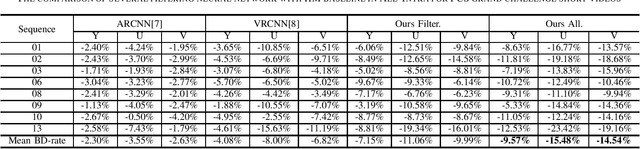
In this paper, a dual learning-based method in intra coding is introduced for PCS Grand Challenge. This method is mainly composed of two parts: intra prediction and reconstruction filtering. They use different network structures, the neural network-based intra prediction uses the full-connected network to predict the block while the neural network-based reconstruction filtering utilizes the convolutional networks. Different with the previous filtering works, we use a network with more powerful feature extraction capabilities in our reconstruction filtering network. And the filtering unit is the block-level so as to achieve a more accurate filtering compensation. To our best knowledge, among all the learning-based methods, this is the first attempt to combine two different networks in one application, and we achieve the state-of-the-art performance for AI configuration on the HEVC Test sequences. The experimental result shows that our method leads to significant BD-rate saving for provided 8 sequences compared to HM-16.20 baseline (average 10.24% and 3.57% bitrate reductions for all-intra and random-access coding, respectively). For HEVC test sequences, our model also achieved a 9.70% BD-rate saving compared to HM-16.20 baseline for all-intra configuration.