 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMATCNN: Infrared and Visible Image Fusion Method Based on Multi-scale CNN with Attention Transformer
Feb 04, 2025



While attention-based approaches have shown considerable progress in enhancing image fusion and addressing the challenges posed by long-range feature dependencies, their efficacy in capturing local features is compromised by the lack of diverse receptive field extraction techniques. To overcome the shortcomings of existing fusion methods in extracting multi-scale local features and preserving global features, this paper proposes a novel cross-modal image fusion approach based on a multi-scale convolutional neural network with attention Transformer (MATCNN). MATCNN utilizes the multi-scale fusion module (MSFM) to extract local features at different scales and employs the global feature extraction module (GFEM) to extract global features. Combining the two reduces the loss of detail features and improves the ability of global feature representation. Simultaneously, an information mask is used to label pertinent details within the images, aiming to enhance the proportion of preserving significant information in infrared images and background textures in visible images in fused images. Subsequently, a novel optimization algorithm is developed, leveraging the mask to guide feature extraction through the integration of content, structural similarity index measurement, and global feature loss. Quantitative and qualitative evaluations are conducted across various datasets, revealing that MATCNN effectively highlights infrared salient targets, preserves additional details in visible images, and achieves better fusion results for cross-modal images. The code of MATCNN will be available at https://github.com/zhang3849/MATCNN.git.
FAVER: Blind Quality Prediction of Variable Frame Rate Videos
Jan 05, 2022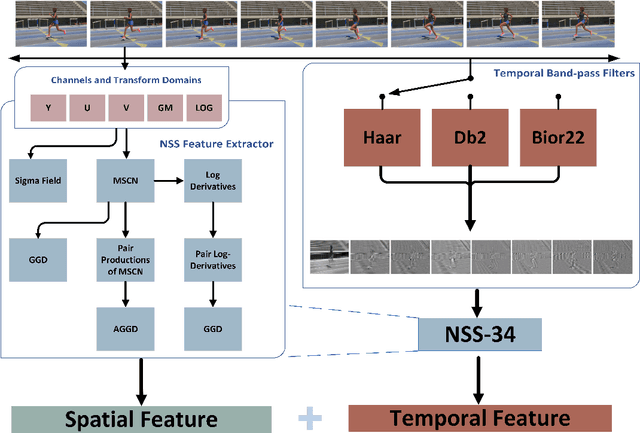
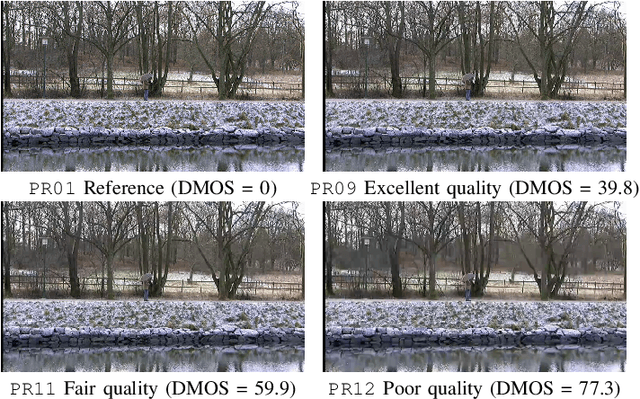
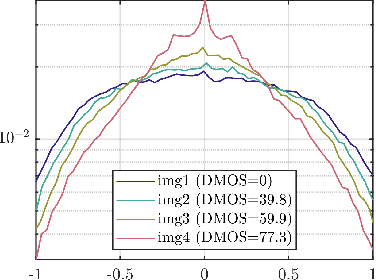
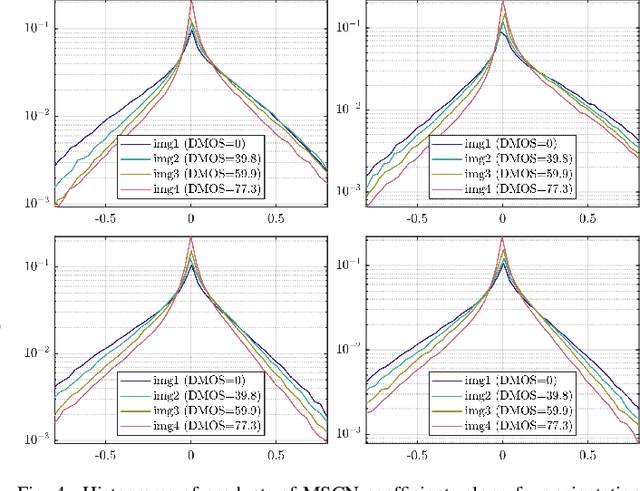
Video quality assessment (VQA) remains an important and challenging problem that affects many applications at the widest scales. Recent advances in mobile devices and cloud computing techniques have made it possible to capture, process, and share high resolution, high frame rate (HFR) videos across the Internet nearly instantaneously. Being able to monitor and control the quality of these streamed videos can enable the delivery of more enjoyable content and perceptually optimized rate control. Accordingly, there is a pressing need to develop VQA models that can be deployed at enormous scales. While some recent effects have been applied to full-reference (FR) analysis of variable frame rate and HFR video quality, the development of no-reference (NR) VQA algorithms targeting frame rate variations has been little studied. Here, we propose a first-of-a-kind blind VQA model for evaluating HFR videos, which we dub the Framerate-Aware Video Evaluator w/o Reference (FAVER). FAVER uses extended models of spatial natural scene statistics that encompass space-time wavelet-decomposed video signals, to conduct efficient frame rate sensitive quality prediction. Our extensive experiments on several HFR video quality datasets show that FAVER outperforms other blind VQA algorithms at a reasonable computational cost. To facilitate reproducible research and public evaluation, an implementation of FAVER is being made freely available online: \url{https://github.com/uniqzheng/HFR-BVQA}.
Learned Image Compression with Separate Hyperprior Decoders
Oct 31, 2021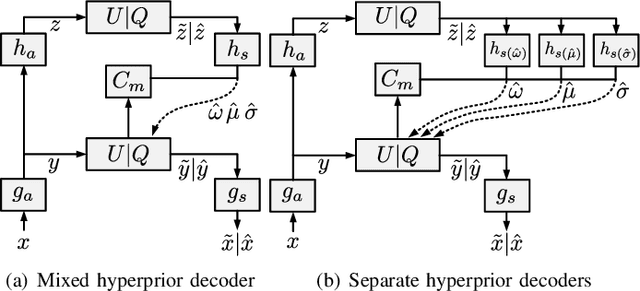
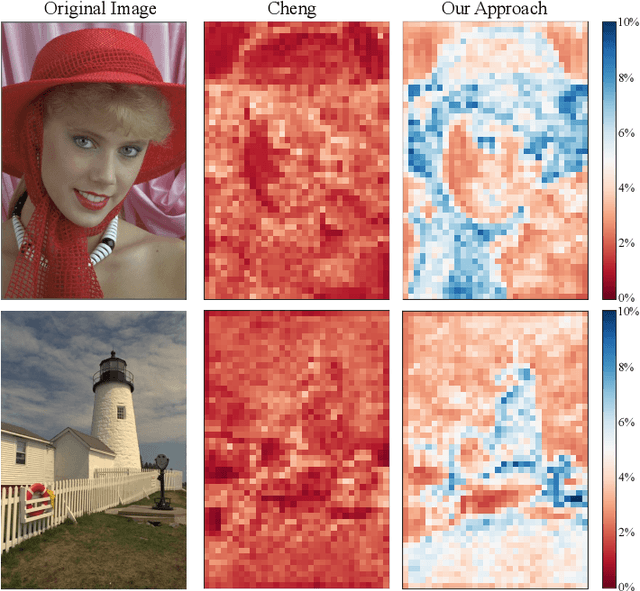
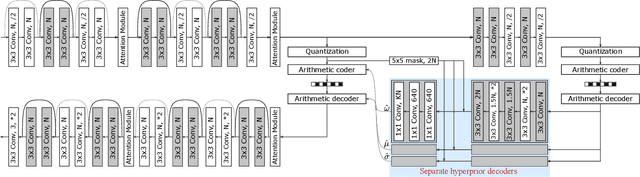
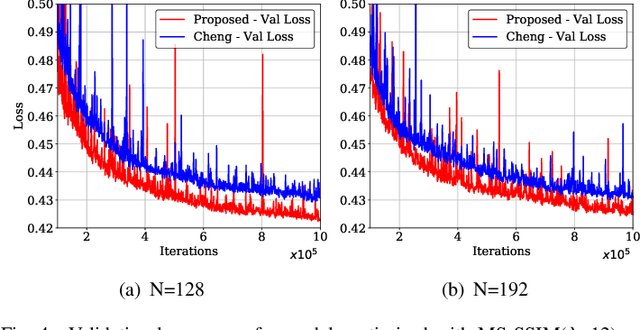
Learned image compression techniques have achieved considerable development in recent years. In this paper, we find that the performance bottleneck lies in the use of a single hyperprior decoder, in which case the ternary Gaussian model collapses to a binary one. To solve this, we propose to use three hyperprior decoders to separate the decoding process of the mixed parameters in discrete Gaussian mixture likelihoods, achieving more accurate parameters estimation. Experimental results demonstrate the proposed method optimized by MS-SSIM achieves on average 3.36% BD-rate reduction compared with state-of-the-art approach. The contribution of the proposed method to the coding time and FLOPs is negligible.
Learned Video Compression with Residual Prediction and Loop Filter
Aug 19, 2021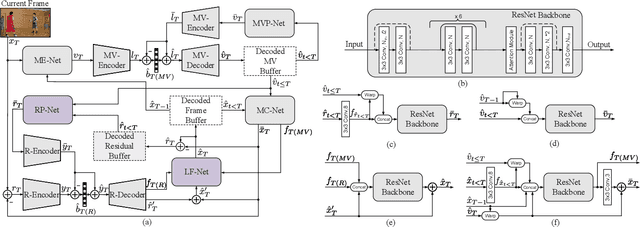
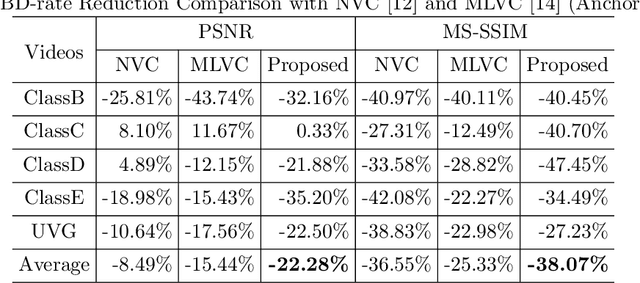
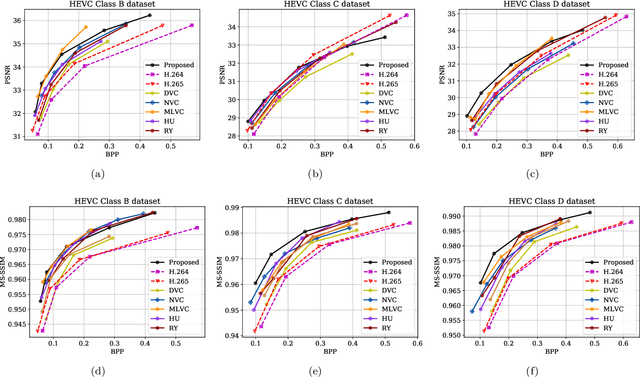
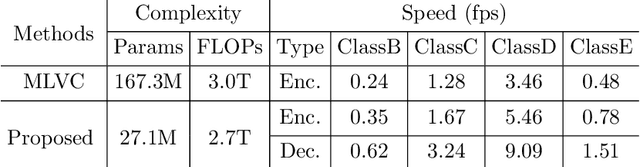
In this paper, we propose a learned video codec with a residual prediction network (RP-Net) and a feature-aided loop filter (LF-Net). For the RP-Net, we exploit the residual of previous multiple frames to further eliminate the redundancy of the current frame residual. For the LF-Net, the features from residual decoding network and the motion compensation network are used to aid the reconstruction quality. To reduce the complexity, a light ResNet structure is used as the backbone for both RP-Net and LF-Net. Experimental results illustrate that we can save about 10% BD-rate compared with previous learned video compression frameworks. Moreover, we can achieve faster coding speed due to the ResNet backbone. This project is available at https://github.com/chaoliu18/RPLVC.
A QP-adaptive Mechanism for CNN-based Filter in Video Coding
Oct 25, 2020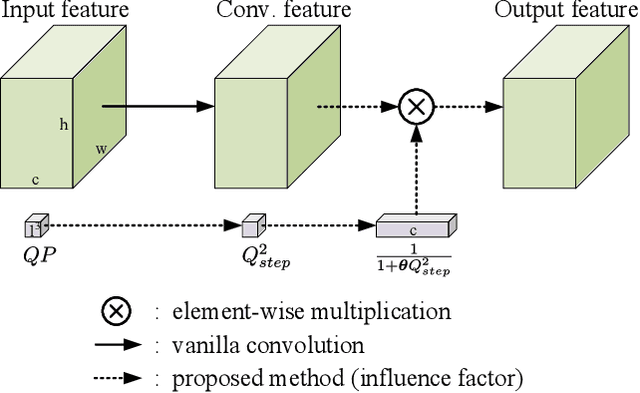
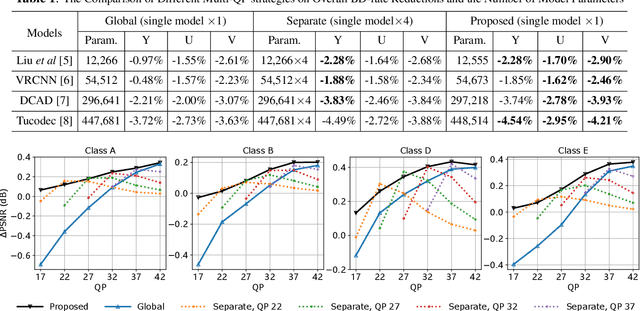
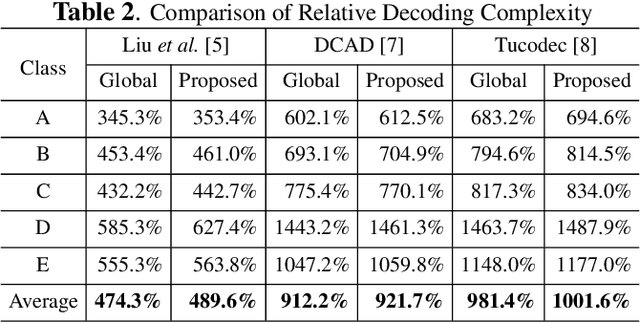
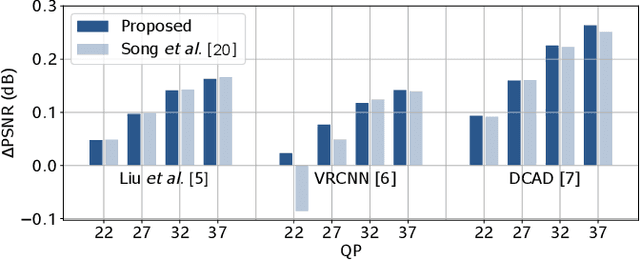
Convolutional neural network (CNN)-based filters have achieved great success in video coding. However, in most previous works, individual models are needed for each quantization parameter (QP) band. This paper presents a generic method to help an arbitrary CNN-filter handle different quantization noise. We model the quantization noise problem and implement a feasible solution on CNN, which introduces the quantization step (Qstep) into the convolution. When the quantization noise increases, the ability of the CNN-filter to suppress noise improves accordingly. This method can be used directly to replace the (vanilla) convolution layer in any existing CNN-filters. By using only 25% of the parameters, the proposed method achieves better performance than using multiple models with VTM-6.3 anchor. Besides, an additional BD-rate reduction of 0.2% is achieved by our proposed method for chroma components.
Dual Learning-based Video Coding with Inception Dense Blocks
Nov 22, 2019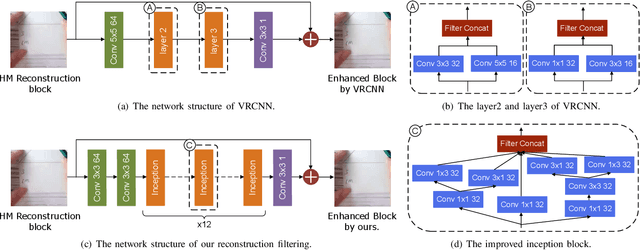

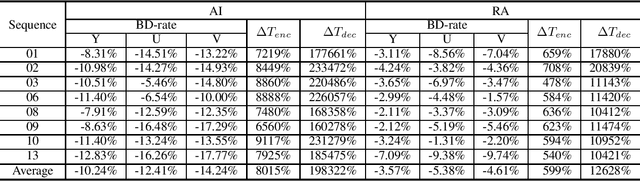
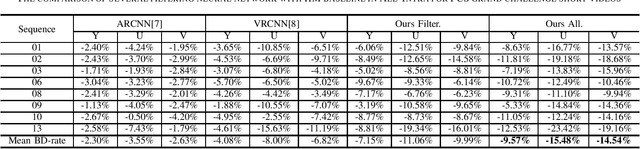
In this paper, a dual learning-based method in intra coding is introduced for PCS Grand Challenge. This method is mainly composed of two parts: intra prediction and reconstruction filtering. They use different network structures, the neural network-based intra prediction uses the full-connected network to predict the block while the neural network-based reconstruction filtering utilizes the convolutional networks. Different with the previous filtering works, we use a network with more powerful feature extraction capabilities in our reconstruction filtering network. And the filtering unit is the block-level so as to achieve a more accurate filtering compensation. To our best knowledge, among all the learning-based methods, this is the first attempt to combine two different networks in one application, and we achieve the state-of-the-art performance for AI configuration on the HEVC Test sequences. The experimental result shows that our method leads to significant BD-rate saving for provided 8 sequences compared to HM-16.20 baseline (average 10.24% and 3.57% bitrate reductions for all-intra and random-access coding, respectively). For HEVC test sequences, our model also achieved a 9.70% BD-rate saving compared to HM-16.20 baseline for all-intra configuration.
Recursive Binary Neural Network Learning Model with 2.28b/Weight Storage Requirement
Sep 15, 2017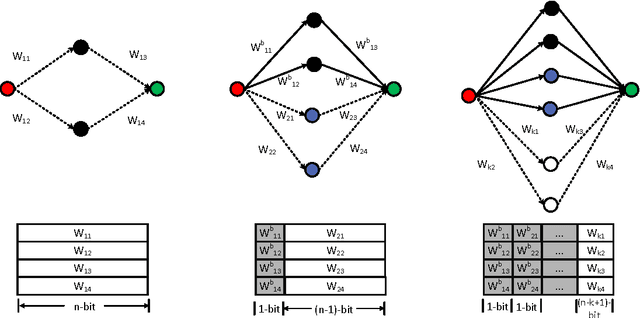
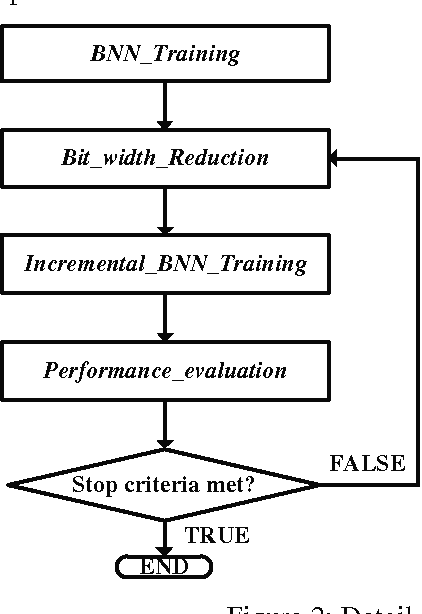
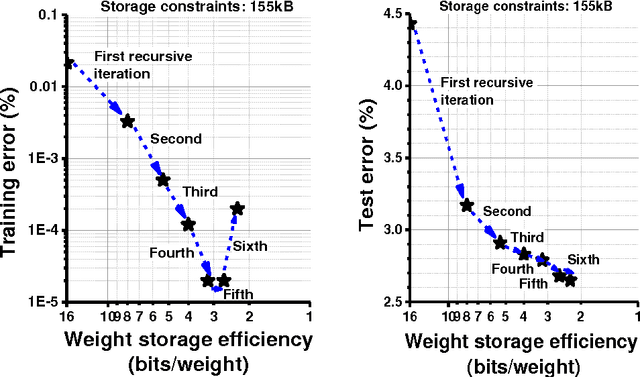
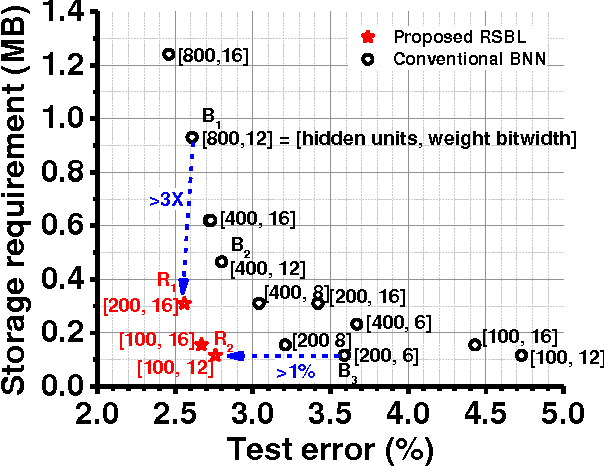
This paper presents a storage-efficient learning model titled Recursive Binary Neural Networks for sensing devices having a limited amount of on-chip data storage such as < 100's kilo-Bytes. The main idea of the proposed model is to recursively recycle data storage of synaptic weights (parameters) during training. This enables a device with a given storage constraint to train and instantiate a neural network classifier with a larger number of weights on a chip and with a less number of off-chip storage accesses. This enables higher classification accuracy, shorter training time, less energy dissipation, and less on-chip storage requirement. We verified the training model with deep neural network classifiers and the permutation-invariant MNIST benchmark. Our model uses only 2.28 bits/weight while for the same data storage constraint achieving ~1% lower classification error as compared to the conventional binary-weight learning model which yet has to use 8 to 16 bit storage per weight. To achieve the similar classification error, the conventional binary model requires ~4x more data storage for weights than the proposed model.