 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaRadar: Rate Adaptive Spectral Compression for Radar-based Perception
Mar 18, 2026Radar is a critical perception modality in autonomous driving systems due to its all-weather characteristics and ability to measure range and Doppler velocity. However, the sheer volume of high-dimensional raw radar data saturates the communication link to the computing engine (e.g., an NPU), which is often a low-bandwidth interface with data rate provisioned only for a few low-resolution range-Doppler frames. A generalized codec for utilizing high-dimensional radar data is notably absent, while existing image-domain approaches are unsuitable, as they typically operate at fixed compression ratios and fail to adapt to varying or adversarial conditions. In light of this, we propose radar data compression with adaptive feedback. It dynamically adjusts the compression ratio by performing gradient descent from the proxy gradient of detection confidence with respect to the compression rate. We employ a zeroth-order gradient approximation as it enables gradient computation even with non-differentiable core operations--pruning and quantization. This also avoids transmitting the gradient tensors over the band-limited link, which, if estimated, would be as large as the original radar data. In addition, we have found that radar feature maps are heavily concentrated on a few frequency components. Thus, we apply the discrete cosine transform to the radar data cubes and selectively prune out the coefficients effectively. We preserve the dynamic range of each radar patch through scaled quantization. Combining those techniques, our proposed online adaptive compression scheme achieves over 100x feature size reduction at minimal performance drop (~1%p). We validate our results on the RADIal, CARRADA, and Radatron datasets.
A Case for 3D Integrated System Design for Neuromorphic Computing & AI Applications
Mar 02, 2021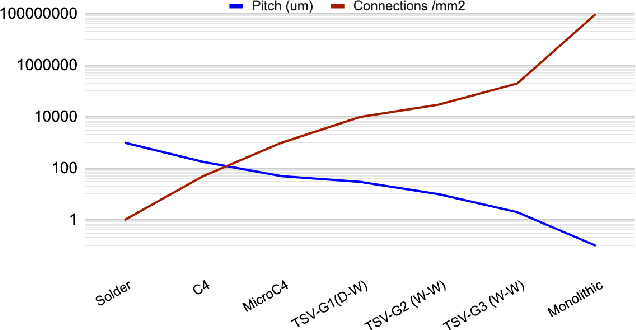
Over the last decade, artificial intelligence has found many applications areas in the society. As AI solutions have become more sophistication and the use cases grew, they highlighted the need to address performance and energy efficiency challenges faced during the implementation process. To address these challenges, there has been growing interest in neuromorphic chips. Neuromorphic computing relies on non von Neumann architectures as well as novel devices, circuits and manufacturing technologies to mimic the human brain. Among such technologies, 3D integration is an important enabler for AI hardware and the continuation of the scaling laws. In this paper, we overview the unique opportunities 3D integration provides in neuromorphic chip design, discuss the emerging opportunities in next generation neuromorphic architectures and review the obstacles. Neuromorphic architectures, which relied on the brain for inspiration and emulation purposes, face grand challenges due to the limited understanding of the functionality and the architecture of the human brain. Yet, high-levels of investments are dedicated to develop neuromorphic chips. We argue that 3D integration not only provides strategic advantages to the cost-effective and flexible design of neuromorphic chips, it may provide design flexibility in incorporating advanced capabilities to further benefits the designs in the future.
Always-On, Sub-300-nW, Event-Driven Spiking Neural Network based on Spike-Driven Clock-Generation and Clock- and Power-Gating for an Ultra-Low-Power Intelligent Device
Jun 23, 2020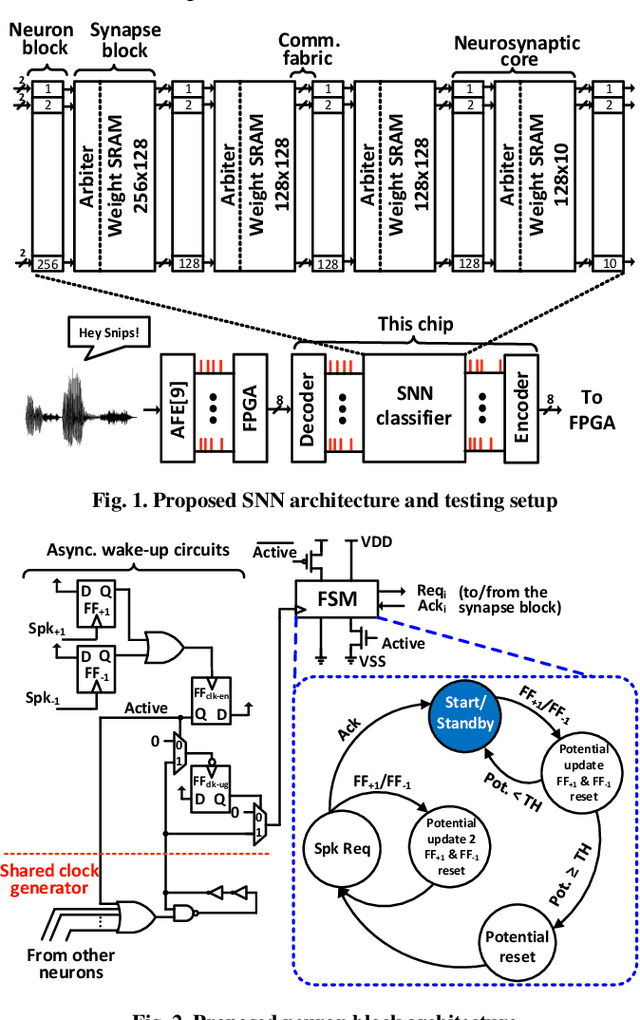
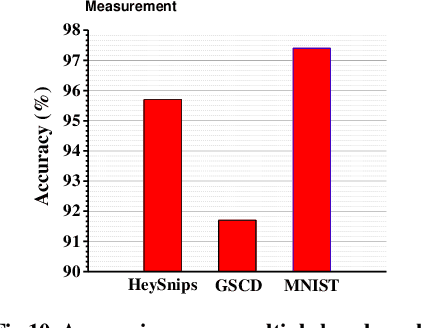
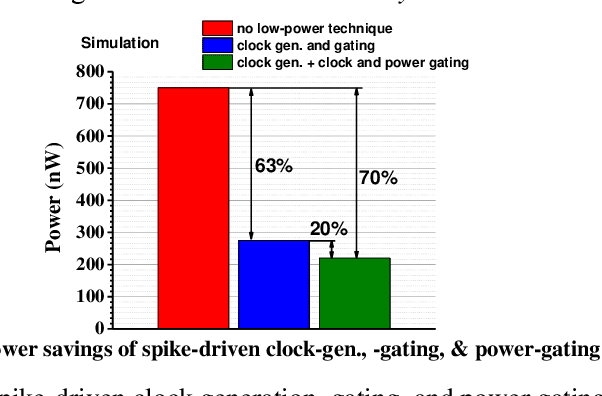
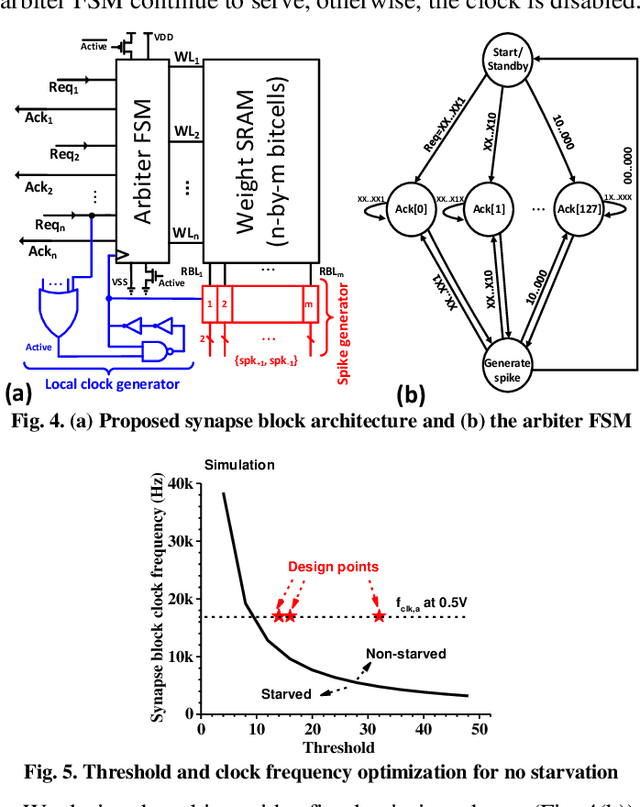
Always-on artificial intelligent (AI) functions such as keyword spotting (KWS) and visual wake-up tend to dominate total power consumption in ultra-low power devices. A key observation is that the signals to an always-on function are sparse in time, which a spiking neural network (SNN) classifier can leverage for power savings, because the switching activity and power consumption of SNNs tend to scale with spike rate. Toward this goal, we present a novel SNN classifier architecture for always-on functions, demonstrating sub-300nW power consumption at the competitive inference accuracy for a KWS and other always-on classification workloads.
MemNet: Memory-Efficiency Guided Neural Architecture Search with Augment-Trim learning
Jul 22, 2019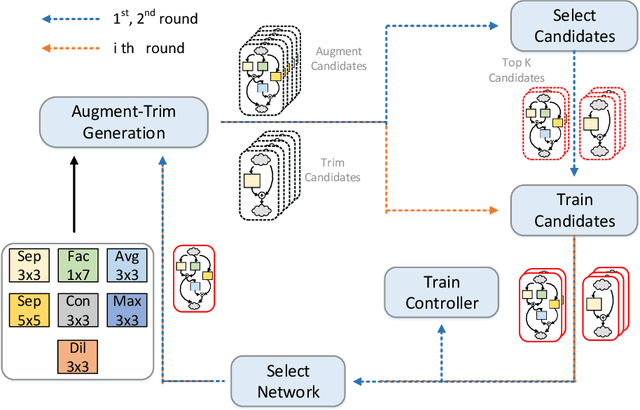
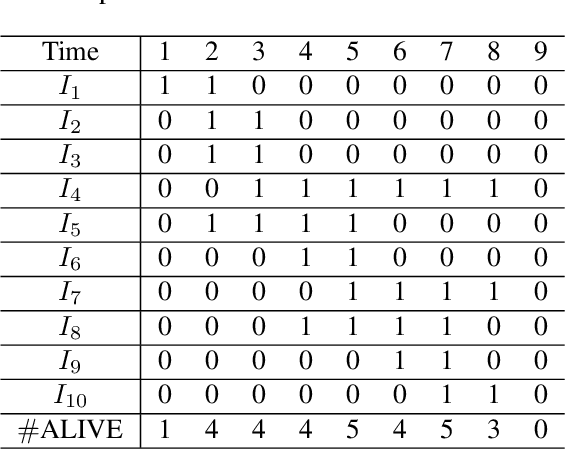

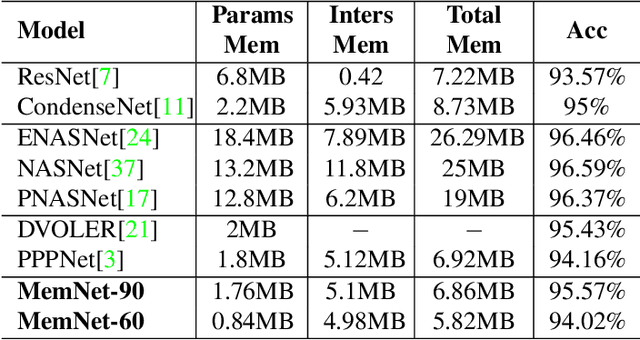
Recent studies on automatic neural architectures search have demonstrated significant performance, competitive to or even better than hand-crafted neural architectures. However, most of the existing network architecture tend to use residual, parallel structures and concatenation block between shallow and deep features to construct a large network. This requires large amounts of memory for storing both weights and feature maps. This is challenging for mobile and embedded devices since they may not have enough memory to perform inference with the designed large network model. To close this gap, we propose MemNet, an augment-trim learning-based neural network search framework that optimizes not only performance but also memory requirement. Specifically, it employs memory consumption based ranking score which forces an upper bound on memory consumption for navigating the search process. Experiment results show that, as compared to the state-of-the-art efficient designing methods, MemNet can find an architecture which can achieve competitive accuracy and save an average of 24.17% on the total memory needed.
KTAN: Knowledge Transfer Adversarial Network
Oct 18, 2018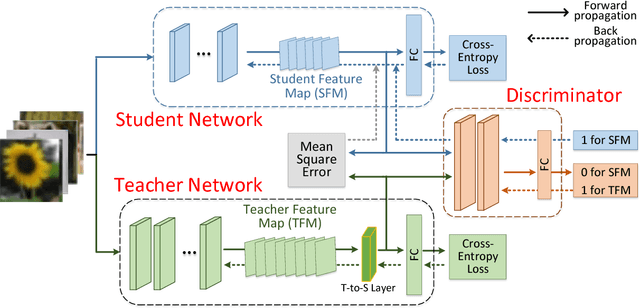



To reduce the large computation and storage cost of a deep convolutional neural network, the knowledge distillation based methods have pioneered to transfer the generalization ability of a large (teacher) deep network to a light-weight (student) network. However, these methods mostly focus on transferring the probability distribution of the softmax layer in a teacher network and thus neglect the intermediate representations. In this paper, we propose a knowledge transfer adversarial network to better train a student network. Our technique holistically considers both intermediate representations and probability distributions of a teacher network. To transfer the knowledge of intermediate representations, we set high-level teacher feature maps as a target, toward which the student feature maps are trained. Specifically, we arrange a Teacher-to-Student layer for enabling our framework suitable for various student structures. The intermediate representation helps the student network better understand the transferred generalization as compared to the probability distribution only. Furthermore, we infuse an adversarial learning process by employing a discriminator network, which can fully exploit the spatial correlation of feature maps in training a student network. The experimental results demonstrate that the proposed method can significantly improve the performance of a student network on both image classification and object detection tasks.
Recursive Binary Neural Network Learning Model with 2.28b/Weight Storage Requirement
Sep 15, 2017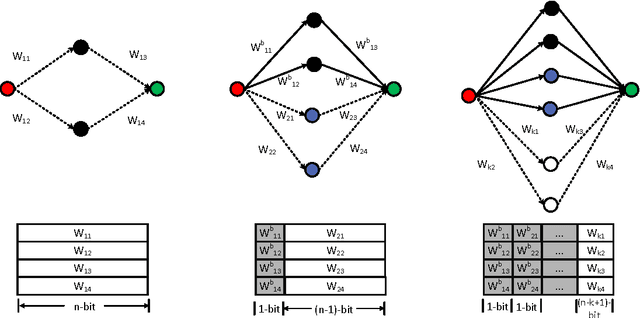
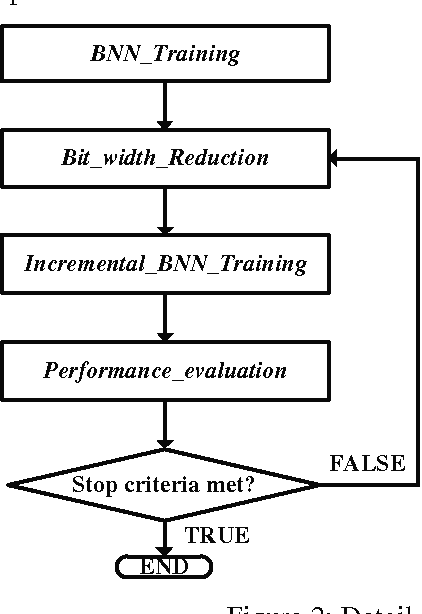
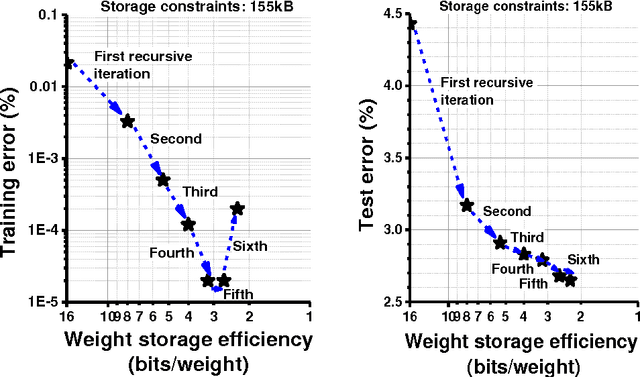
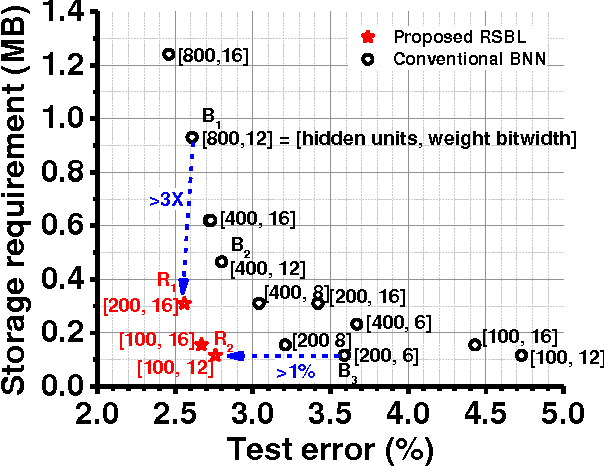
This paper presents a storage-efficient learning model titled Recursive Binary Neural Networks for sensing devices having a limited amount of on-chip data storage such as < 100's kilo-Bytes. The main idea of the proposed model is to recursively recycle data storage of synaptic weights (parameters) during training. This enables a device with a given storage constraint to train and instantiate a neural network classifier with a larger number of weights on a chip and with a less number of off-chip storage accesses. This enables higher classification accuracy, shorter training time, less energy dissipation, and less on-chip storage requirement. We verified the training model with deep neural network classifiers and the permutation-invariant MNIST benchmark. Our model uses only 2.28 bits/weight while for the same data storage constraint achieving ~1% lower classification error as compared to the conventional binary-weight learning model which yet has to use 8 to 16 bit storage per weight. To achieve the similar classification error, the conventional binary model requires ~4x more data storage for weights than the proposed model.
Dynamic Capacity Estimation in Hopfield Networks
Sep 15, 2017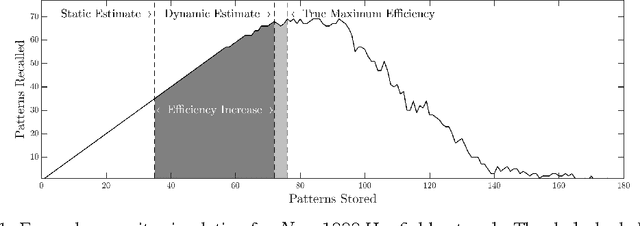
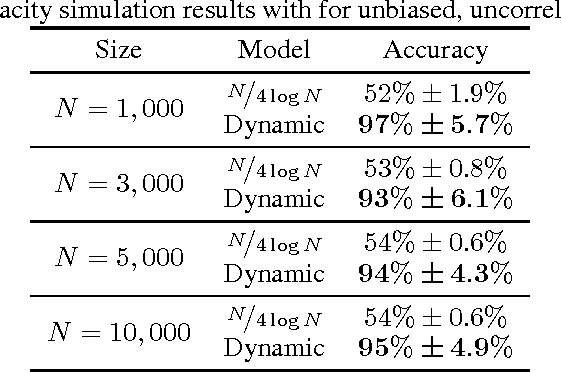

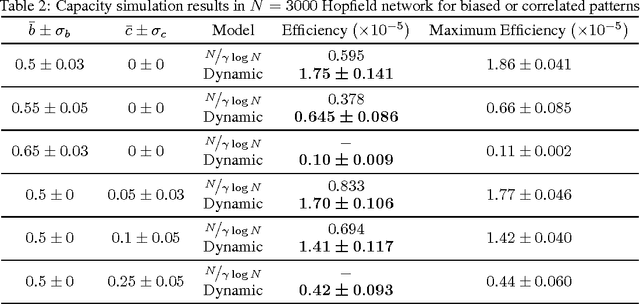
Understanding the memory capacity of neural networks remains a challenging problem in implementing artificial intelligence systems. In this paper, we address the notion of capacity with respect to Hopfield networks and propose a dynamic approach to monitoring a network's capacity. We define our understanding of capacity as the maximum number of stored patterns which can be retrieved when probed by the stored patterns. Prior work in this area has presented static expressions dependent on neuron count $N$, forcing network designers to assume worst-case input characteristics for bias and correlation when setting the capacity of the network. Instead, our model operates simultaneously with the learning Hopfield network and concludes on a capacity estimate based on the patterns which were stored. By continuously updating the crosstalk associated with the stored patterns, our model guards the network from overwriting its memory traces and exceeding its capacity. We simulate our model using artificially generated random patterns, which can be set to a desired bias and correlation, and observe capacity estimates between 93% and 97% accurate. As a result, our model doubles the memory efficiency of Hopfield networks in comparison to the static and worst-case capacity estimate while minimizing the risk of lost patterns.
Energy-efficient neuromorphic classifiers
Jul 01, 2015Neuromorphic engineering combines the architectural and computational principles of systems neuroscience with semiconductor electronics, with the aim of building efficient and compact devices that mimic the synaptic and neural machinery of the brain. Neuromorphic engineering promises extremely low energy consumptions, comparable to those of the nervous system. However, until now the neuromorphic approach has been restricted to relatively simple circuits and specialized functions, rendering elusive a direct comparison of their energy consumption to that used by conventional von Neumann digital machines solving real-world tasks. Here we show that a recent technology developed by IBM can be leveraged to realize neuromorphic circuits that operate as classifiers of complex real-world stimuli. These circuits emulate enough neurons to compete with state-of-the-art classifiers. We also show that the energy consumption of the IBM chip is typically 2 or more orders of magnitude lower than that of conventional digital machines when implementing classifiers with comparable performance. Moreover, the spike-based dynamics display a trade-off between integration time and accuracy, which naturally translates into algorithms that can be flexibly deployed for either fast and approximate classifications, or more accurate classifications at the mere expense of longer running times and higher energy costs. This work finally proves that the neuromorphic approach can be efficiently used in real-world applications and it has significant advantages over conventional digital devices when energy consumption is considered.