 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Action Form Assessment by Exploiting Multimodal Chain-of-Thoughts Reasoning
Dec 17, 2025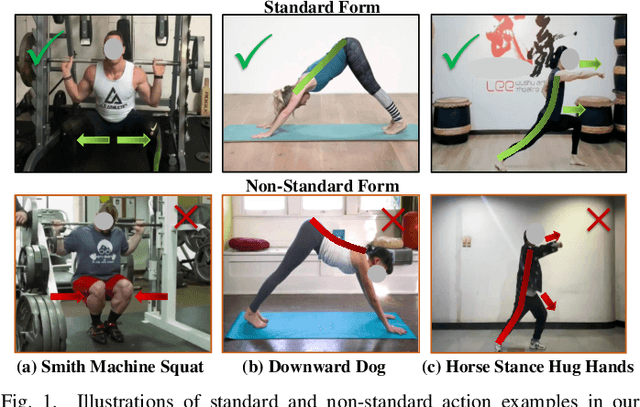
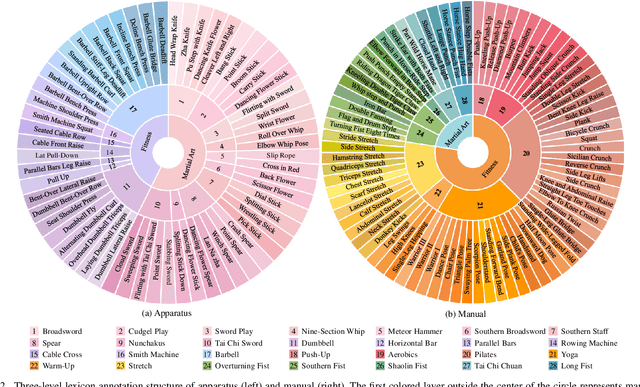

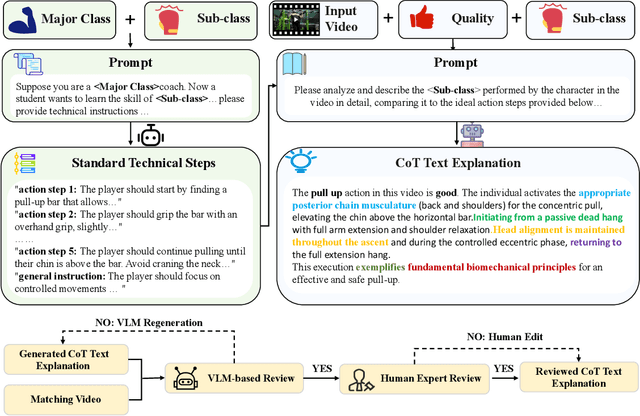
Evaluating whether human action is standard or not and providing reasonable feedback to improve action standardization is very crucial but challenging in real-world scenarios. However, current video understanding methods are mainly concerned with what and where the action is, which is unable to meet the requirements. Meanwhile, most of the existing datasets lack the labels indicating the degree of action standardization, and the action quality assessment datasets lack explainability and detailed feedback. Therefore, we define a new Human Action Form Assessment (AFA) task, and introduce a new diverse dataset CoT-AFA, which contains a large scale of fitness and martial arts videos with multi-level annotations for comprehensive video analysis. We enrich the CoT-AFA dataset with a novel Chain-of-Thought explanation paradigm. Instead of offering isolated feedback, our explanations provide a complete reasoning process--from identifying an action step to analyzing its outcome and proposing a concrete solution. Furthermore, we propose a framework named Explainable Fitness Assessor, which can not only judge an action but also explain why and provide a solution. This framework employs two parallel processing streams and a dynamic gating mechanism to fuse visual and semantic information, thereby boosting its analytical capabilities. The experimental results demonstrate that our method has achieved improvements in explanation generation (e.g., +16.0% in CIDEr), action classification (+2.7% in accuracy) and quality assessment (+2.1% in accuracy), revealing great potential of CoT-AFA for future studies. Our dataset and source code is available at https://github.com/MICLAB-BUPT/EFA.
SoccerNet 2025 Challenges Results
Aug 26, 2025The SoccerNet 2025 Challenges mark the fifth annual edition of the SoccerNet open benchmarking effort, dedicated to advancing computer vision research in football video understanding. This year's challenges span four vision-based tasks: (1) Team Ball Action Spotting, focused on detecting ball-related actions in football broadcasts and assigning actions to teams; (2) Monocular Depth Estimation, targeting the recovery of scene geometry from single-camera broadcast clips through relative depth estimation for each pixel; (3) Multi-View Foul Recognition, requiring the analysis of multiple synchronized camera views to classify fouls and their severity; and (4) Game State Reconstruction, aimed at localizing and identifying all players from a broadcast video to reconstruct the game state on a 2D top-view of the field. Across all tasks, participants were provided with large-scale annotated datasets, unified evaluation protocols, and strong baselines as starting points. This report presents the results of each challenge, highlights the top-performing solutions, and provides insights into the progress made by the community. The SoccerNet Challenges continue to serve as a driving force for reproducible, open research at the intersection of computer vision, artificial intelligence, and sports. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
NTIRE 2025 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 20, 2025This paper presents the NTIRE 2025 image super-resolution ($\times$4) challenge, one of the associated competitions of the 10th NTIRE Workshop at CVPR 2025. The challenge aims to recover high-resolution (HR) images from low-resolution (LR) counterparts generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective network designs or solutions that achieve state-of-the-art SR performance. To reflect the dual objectives of image SR research, the challenge includes two sub-tracks: (1) a restoration track, emphasizes pixel-wise accuracy and ranks submissions based on PSNR; (2) a perceptual track, focuses on visual realism and ranks results by a perceptual score. A total of 286 participants registered for the competition, with 25 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, the main results, and methods of each team. The challenge serves as a benchmark to advance the state of the art and foster progress in image SR.
Chain-of-Thought Textual Reasoning for Few-shot Temporal Action Localization
Apr 18, 2025



Traditional temporal action localization (TAL) methods rely on large amounts of detailed annotated data, whereas few-shot TAL reduces this dependence by using only a few training samples to identify unseen action categories. However, existing few-shot TAL methods typically focus solely on video-level information, neglecting textual information, which can provide valuable semantic support for the localization task. Therefore, we propose a new few-shot temporal action localization method by Chain-of-Thought textual reasoning to improve localization performance. Specifically, we design a novel few-shot learning framework that leverages textual semantic information to enhance the model's ability to capture action commonalities and variations, which includes a semantic-aware text-visual alignment module designed to align the query and support videos at different levels. Meanwhile, to better express the temporal dependencies and causal relationships between actions at the textual level to assist action localization, we design a Chain of Thought (CoT)-like reasoning method that progressively guides the Vision Language Model (VLM) and Large Language Model (LLM) to generate CoT-like text descriptions for videos. The generated texts can capture more variance of action than visual features. We conduct extensive experiments on the publicly available ActivityNet1.3 and THUMOS14 datasets. We introduce the first dataset named Human-related Anomaly Localization and explore the application of the TAL task in human anomaly detection. The experimental results demonstrate that our proposed method significantly outperforms existing methods in single-instance and multi-instance scenarios. We will release our code, data and benchmark.
Robo-SGG: Exploiting Layout-Oriented Normalization and Restitution for Robust Scene Graph Generation
Apr 17, 2025In this paper, we introduce a novel method named Robo-SGG, i.e., Layout-Oriented Normalization and Restitution for Robust Scene Graph Generation. Compared to the existing SGG setting, the robust scene graph generation aims to perform inference on a diverse range of corrupted images, with the core challenge being the domain shift between the clean and corrupted images. Existing SGG methods suffer from degraded performance due to compromised visual features e.g., corruption interference or occlusions. To obtain robust visual features, we exploit the layout information, which is domain-invariant, to enhance the efficacy of existing SGG methods on corrupted images. Specifically, we employ Instance Normalization(IN) to filter out the domain-specific feature and recover the unchangeable structural features, i.e., the positional and semantic relationships among objects by the proposed Layout-Oriented Restitution. Additionally, we propose a Layout-Embedded Encoder (LEE) that augments the existing object and predicate encoders within the SGG framework, enriching the robust positional and semantic features of objects and predicates. Note that our proposed Robo-SGG module is designed as a plug-and-play component, which can be easily integrated into any baseline SGG model. Extensive experiments demonstrate that by integrating the state-of-the-art method into our proposed Robo-SGG, we achieve relative improvements of 5.6%, 8.0%, and 6.5% in mR@50 for PredCls, SGCls, and SGDet tasks on the VG-C dataset, respectively, and achieve new state-of-the-art performance in corruption scene graph generation benchmark (VG-C and GQA-C). We will release our source code and model.
DC-SAM: In-Context Segment Anything in Images and Videos via Dual Consistency
Apr 16, 2025Given a single labeled example, in-context segmentation aims to segment corresponding objects. This setting, known as one-shot segmentation in few-shot learning, explores the segmentation model's generalization ability and has been applied to various vision tasks, including scene understanding and image/video editing. While recent Segment Anything Models have achieved state-of-the-art results in interactive segmentation, these approaches are not directly applicable to in-context segmentation. In this work, we propose the Dual Consistency SAM (DC-SAM) method based on prompt-tuning to adapt SAM and SAM2 for in-context segmentation of both images and videos. Our key insights are to enhance the features of the SAM's prompt encoder in segmentation by providing high-quality visual prompts. When generating a mask prior, we fuse the SAM features to better align the prompt encoder. Then, we design a cycle-consistent cross-attention on fused features and initial visual prompts. Next, a dual-branch design is provided by using the discriminative positive and negative prompts in the prompt encoder. Furthermore, we design a simple mask-tube training strategy to adopt our proposed dual consistency method into the mask tube. Although the proposed DC-SAM is primarily designed for images, it can be seamlessly extended to the video domain with the support of SAM2. Given the absence of in-context segmentation in the video domain, we manually curate and construct the first benchmark from existing video segmentation datasets, named In-Context Video Object Segmentation (IC-VOS), to better assess the in-context capability of the model. Extensive experiments demonstrate that our method achieves 55.5 (+1.4) mIoU on COCO-20i, 73.0 (+1.1) mIoU on PASCAL-5i, and a J&F score of 71.52 on the proposed IC-VOS benchmark. Our source code and benchmark are available at https://github.com/zaplm/DC-SAM.
The Tenth NTIRE 2025 Image Denoising Challenge Report
Apr 16, 2025



This paper presents an overview of the NTIRE 2025 Image Denoising Challenge ({\sigma} = 50), highlighting the proposed methodologies and corresponding results. The primary objective is to develop a network architecture capable of achieving high-quality denoising performance, quantitatively evaluated using PSNR, without constraints on computational complexity or model size. The task assumes independent additive white Gaussian noise (AWGN) with a fixed noise level of 50. A total of 290 participants registered for the challenge, with 20 teams successfully submitting valid results, providing insights into the current state-of-the-art in image denoising.
XR-VLM: Cross-Relationship Modeling with Multi-part Prompts and Visual Features for Fine-Grained Recognition
Mar 10, 2025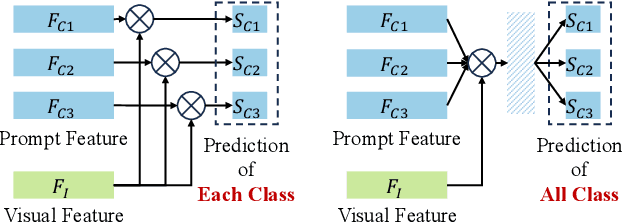
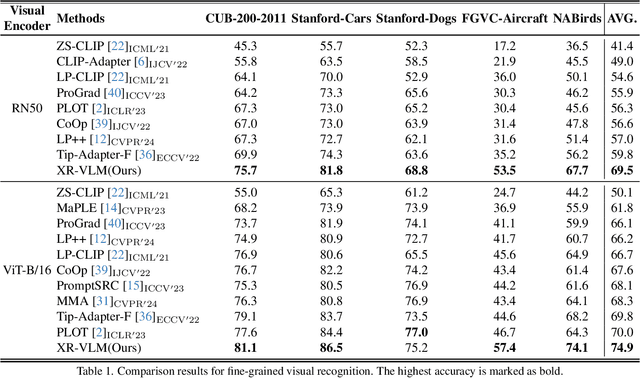
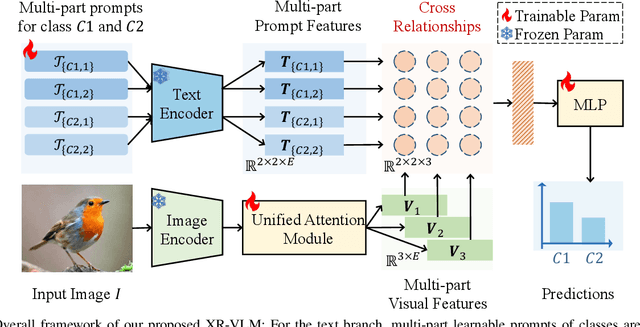
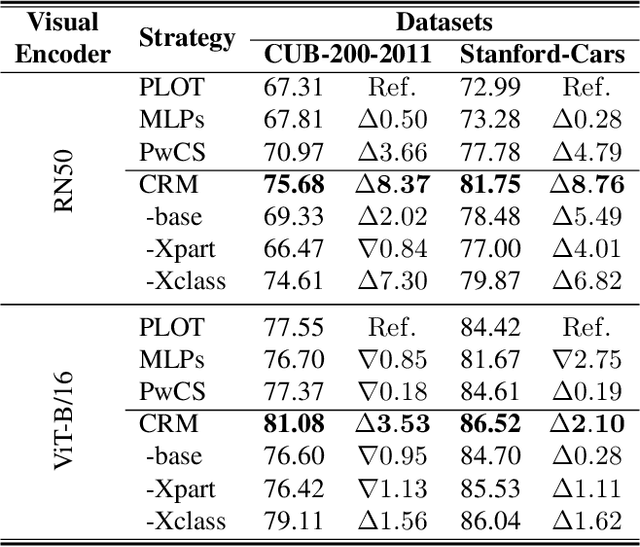
Vision-Language Models (VLMs) have demonstrated impressive performance on various visual tasks, yet they still require adaptation on downstream tasks to achieve optimal performance. Recently, various adaptation technologies have been proposed, but we observe they often underperform in fine-grained visual recognition, which requires models to capture subtle yet discriminative features to distinguish similar sub-categories. Current adaptation methods typically rely on an alignment-based prediction framework, \ie the visual feature is compared with each class prompt for similarity calculation as the final prediction, which lacks class interaction during the forward pass. Besides, learning single uni-modal feature further restricts the model's expressive capacity. Therefore, we propose a novel mechanism, XR-VLM, to discover subtle differences by modeling cross-relationships, which specifically excels in scenarios involving multiple features. Our method introduces a unified multi-part visual feature extraction module designed to seamlessly integrate with the diverse backbones inherent in VLMs. Additionally, we develop a multi-part prompt learning module to capture multi-perspective descriptions of sub-categories. To further enhance discriminative capability, we propose a cross relationship modeling pattern that combines visual feature with all class prompt features, enabling a deeper exploration of the relationships between these two modalities. Extensive experiments have been conducted on various fine-grained datasets, and the results demonstrate that our method achieves significant improvements compared to current state-of-the-art approaches. Code will be released.
Robust Disentangled Counterfactual Learning for Physical Audiovisual Commonsense Reasoning
Feb 18, 2025In this paper, we propose a new Robust Disentangled Counterfactual Learning (RDCL) approach for physical audiovisual commonsense reasoning. The task aims to infer objects' physics commonsense based on both video and audio input, with the main challenge being how to imitate the reasoning ability of humans, even under the scenario of missing modalities. Most of the current methods fail to take full advantage of different characteristics in multi-modal data, and lacking causal reasoning ability in models impedes the progress of implicit physical knowledge inferring. To address these issues, our proposed RDCL method decouples videos into static (time-invariant) and dynamic (time-varying) factors in the latent space by the disentangled sequential encoder, which adopts a variational autoencoder (VAE) to maximize the mutual information with a contrastive loss function. Furthermore, we introduce a counterfactual learning module to augment the model's reasoning ability by modeling physical knowledge relationships among different objects under counterfactual intervention. To alleviate the incomplete modality data issue, we introduce a robust multimodal learning method to recover the missing data by decomposing the shared features and model-specific features. Our proposed method is a plug-and-play module that can be incorporated into any baseline including VLMs. In experiments, we show that our proposed method improves the reasoning accuracy and robustness of baseline methods and achieves the state-of-the-art performance.
VLM-Assisted Continual learning for Visual Question Answering in Self-Driving
Feb 02, 2025



In this paper, we propose a novel approach for solving the Visual Question Answering (VQA) task in autonomous driving by integrating Vision-Language Models (VLMs) with continual learning. In autonomous driving, VQA plays a vital role in enabling the system to understand and reason about its surroundings. However, traditional models often struggle with catastrophic forgetting when sequentially exposed to new driving tasks, such as perception, prediction, and planning, each requiring different forms of knowledge. To address this challenge, we present a novel continual learning framework that combines VLMs with selective memory replay and knowledge distillation, reinforced by task-specific projection layer regularization. The knowledge distillation allows a previously trained model to act as a "teacher" to guide the model through subsequent tasks, minimizing forgetting. Meanwhile, task-specific projection layers calculate the loss based on the divergence of feature representations, ensuring continuity in learning and reducing the shift between tasks. Evaluated on the DriveLM dataset, our framework shows substantial performance improvements, with gains ranging from 21.40% to 32.28% across various metrics. These results highlight the effectiveness of combining continual learning with VLMs in enhancing the resilience and reliability of VQA systems in autonomous driving. We will release our source code.