 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobo-SGG: Exploiting Layout-Oriented Normalization and Restitution for Robust Scene Graph Generation
Apr 17, 2025In this paper, we introduce a novel method named Robo-SGG, i.e., Layout-Oriented Normalization and Restitution for Robust Scene Graph Generation. Compared to the existing SGG setting, the robust scene graph generation aims to perform inference on a diverse range of corrupted images, with the core challenge being the domain shift between the clean and corrupted images. Existing SGG methods suffer from degraded performance due to compromised visual features e.g., corruption interference or occlusions. To obtain robust visual features, we exploit the layout information, which is domain-invariant, to enhance the efficacy of existing SGG methods on corrupted images. Specifically, we employ Instance Normalization(IN) to filter out the domain-specific feature and recover the unchangeable structural features, i.e., the positional and semantic relationships among objects by the proposed Layout-Oriented Restitution. Additionally, we propose a Layout-Embedded Encoder (LEE) that augments the existing object and predicate encoders within the SGG framework, enriching the robust positional and semantic features of objects and predicates. Note that our proposed Robo-SGG module is designed as a plug-and-play component, which can be easily integrated into any baseline SGG model. Extensive experiments demonstrate that by integrating the state-of-the-art method into our proposed Robo-SGG, we achieve relative improvements of 5.6%, 8.0%, and 6.5% in mR@50 for PredCls, SGCls, and SGDet tasks on the VG-C dataset, respectively, and achieve new state-of-the-art performance in corruption scene graph generation benchmark (VG-C and GQA-C). We will release our source code and model.
Robust Disentangled Counterfactual Learning for Physical Audiovisual Commonsense Reasoning
Feb 18, 2025In this paper, we propose a new Robust Disentangled Counterfactual Learning (RDCL) approach for physical audiovisual commonsense reasoning. The task aims to infer objects' physics commonsense based on both video and audio input, with the main challenge being how to imitate the reasoning ability of humans, even under the scenario of missing modalities. Most of the current methods fail to take full advantage of different characteristics in multi-modal data, and lacking causal reasoning ability in models impedes the progress of implicit physical knowledge inferring. To address these issues, our proposed RDCL method decouples videos into static (time-invariant) and dynamic (time-varying) factors in the latent space by the disentangled sequential encoder, which adopts a variational autoencoder (VAE) to maximize the mutual information with a contrastive loss function. Furthermore, we introduce a counterfactual learning module to augment the model's reasoning ability by modeling physical knowledge relationships among different objects under counterfactual intervention. To alleviate the incomplete modality data issue, we introduce a robust multimodal learning method to recover the missing data by decomposing the shared features and model-specific features. Our proposed method is a plug-and-play module that can be incorporated into any baseline including VLMs. In experiments, we show that our proposed method improves the reasoning accuracy and robustness of baseline methods and achieves the state-of-the-art performance.
T2SG: Traffic Topology Scene Graph for Topology Reasoning in Autonomous Driving
Nov 28, 2024Understanding the traffic scenes and then generating high-definition (HD) maps present significant challenges in autonomous driving. In this paper, we defined a novel Traffic Topology Scene Graph, a unified scene graph explicitly modeling the lane, controlled and guided by different road signals (e.g., right turn), and topology relationships among them, which is always ignored by previous high-definition (HD) mapping methods. For the generation of T2SG, we propose TopoFormer, a novel one-stage Topology Scene Graph TransFormer with two newly designed layers. Specifically, TopoFormer incorporates a Lane Aggregation Layer (LAL) that leverages the geometric distance among the centerline of lanes to guide the aggregation of global information. Furthermore, we proposed a Counterfactual Intervention Layer (CIL) to model the reasonable road structure ( e.g., intersection, straight) among lanes under counterfactual intervention. Then the generated T2SG can provide a more accurate and explainable description of the topological structure in traffic scenes. Experimental results demonstrate that TopoFormer outperforms existing methods on the T2SG generation task, and the generated T2SG significantly enhances traffic topology reasoning in downstream tasks, achieving a state-of-the-art performance of 46.3 OLS on the OpenLane-V2 benchmark. We will release our source code and model.
Disentangled Counterfactual Learning for Physical Audiovisual Commonsense Reasoning
Nov 02, 2023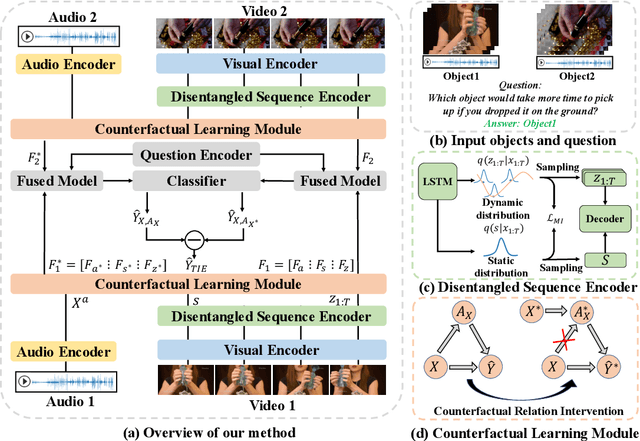
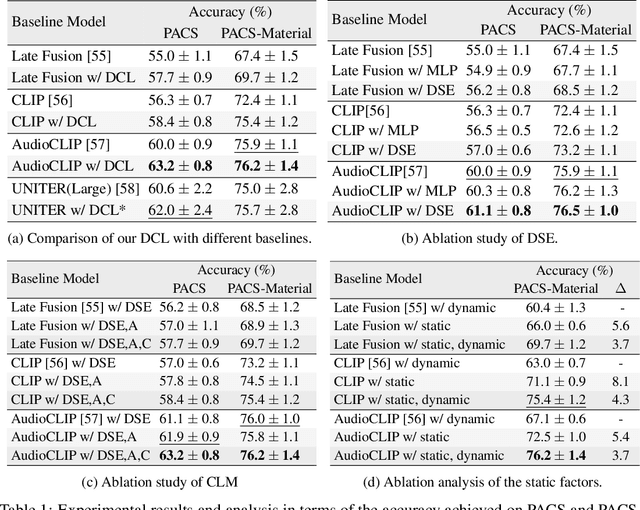
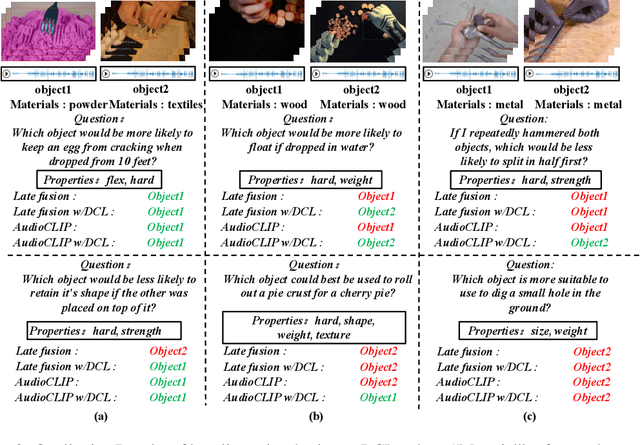
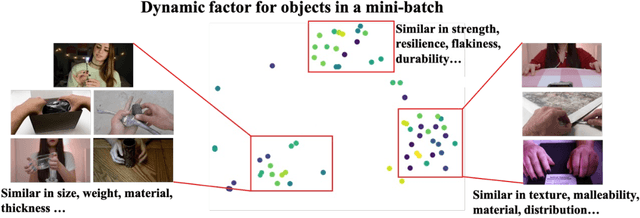
In this paper, we propose a Disentangled Counterfactual Learning~(DCL) approach for physical audiovisual commonsense reasoning. The task aims to infer objects' physics commonsense based on both video and audio input, with the main challenge is how to imitate the reasoning ability of humans. Most of the current methods fail to take full advantage of different characteristics in multi-modal data, and lacking causal reasoning ability in models impedes the progress of implicit physical knowledge inferring. To address these issues, our proposed DCL method decouples videos into static (time-invariant) and dynamic (time-varying) factors in the latent space by the disentangled sequential encoder, which adopts a variational autoencoder (VAE) to maximize the mutual information with a contrastive loss function. Furthermore, we introduce a counterfactual learning module to augment the model's reasoning ability by modeling physical knowledge relationships among different objects under counterfactual intervention. Our proposed method is a plug-and-play module that can be incorporated into any baseline. In experiments, we show that our proposed method improves baseline methods and achieves state-of-the-art performance. Our source code is available at https://github.com/Andy20178/DCL.
Revisiting Transformer for Point Cloud-based 3D Scene Graph Generation
Mar 23, 2023In this paper, we propose the semantic graph Transformer (SGT) for 3D scene graph generation. The task aims to parse a cloud point-based scene into a semantic structural graph, with the core challenge of modeling the complex global structure. Existing methods based on graph convolutional networks (GCNs) suffer from the over-smoothing dilemma and could only propagate information from limited neighboring nodes. In contrast, our SGT uses Transformer layers as the base building block to allow global information passing, with two types of proposed Transformer layers tailored for the 3D scene graph generation task. Specifically, we introduce the graph embedding layer to best utilize the global information in graph edges while maintaining comparable computation costs. Additionally, we propose the semantic injection layer to leverage categorical text labels and visual object knowledge. We benchmark our SGT on the established 3DSSG benchmark and achieve a 35.9% absolute improvement in relationship prediction's R@50 and an 80.4% boost on the subset with complex scenes over the state-of-the-art. Our analyses further show SGT's superiority in the long-tailed and zero-shot scenarios. We will release the code and model.