 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2025 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 20, 2025This paper presents the NTIRE 2025 image super-resolution ($\times$4) challenge, one of the associated competitions of the 10th NTIRE Workshop at CVPR 2025. The challenge aims to recover high-resolution (HR) images from low-resolution (LR) counterparts generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective network designs or solutions that achieve state-of-the-art SR performance. To reflect the dual objectives of image SR research, the challenge includes two sub-tracks: (1) a restoration track, emphasizes pixel-wise accuracy and ranks submissions based on PSNR; (2) a perceptual track, focuses on visual realism and ranks results by a perceptual score. A total of 286 participants registered for the competition, with 25 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, the main results, and methods of each team. The challenge serves as a benchmark to advance the state of the art and foster progress in image SR.
The Tenth NTIRE 2025 Image Denoising Challenge Report
Apr 16, 2025



This paper presents an overview of the NTIRE 2025 Image Denoising Challenge ({\sigma} = 50), highlighting the proposed methodologies and corresponding results. The primary objective is to develop a network architecture capable of achieving high-quality denoising performance, quantitatively evaluated using PSNR, without constraints on computational complexity or model size. The task assumes independent additive white Gaussian noise (AWGN) with a fixed noise level of 50. A total of 290 participants registered for the challenge, with 20 teams successfully submitting valid results, providing insights into the current state-of-the-art in image denoising.
DOCTR: Disentangled Object-Centric Transformer for Point Scene Understanding
Mar 25, 2024



Point scene understanding is a challenging task to process real-world scene point cloud, which aims at segmenting each object, estimating its pose, and reconstructing its mesh simultaneously. Recent state-of-the-art method first segments each object and then processes them independently with multiple stages for the different sub-tasks. This leads to a complex pipeline to optimize and makes it hard to leverage the relationship constraints between multiple objects. In this work, we propose a novel Disentangled Object-Centric TRansformer (DOCTR) that explores object-centric representation to facilitate learning with multiple objects for the multiple sub-tasks in a unified manner. Each object is represented as a query, and a Transformer decoder is adapted to iteratively optimize all the queries involving their relationship. In particular, we introduce a semantic-geometry disentangled query (SGDQ) design that enables the query features to attend separately to semantic information and geometric information relevant to the corresponding sub-tasks. A hybrid bipartite matching module is employed to well use the supervisions from all the sub-tasks during training. Qualitative and quantitative experimental results demonstrate that our method achieves state-of-the-art performance on the challenging ScanNet dataset. Code is available at https://github.com/SAITPublic/DOCTR.
Semi-supervised Cell Recognition under Point Supervision
Jun 14, 2023Cell recognition is a fundamental task in digital histopathology image analysis. Point-based cell recognition (PCR) methods normally require a vast number of annotations, which is extremely costly, time-consuming and labor-intensive. Semi-supervised learning (SSL) can provide a shortcut to make full use of cell information in gigapixel whole slide images without exhaustive labeling. However, research into semi-supervised point-based cell recognition (SSPCR) remains largely overlooked. Previous SSPCR works are all built on density map-based PCR models, which suffer from unsatisfactory accuracy, slow inference speed and high sensitivity to hyper-parameters. To address these issues, end-to-end PCR models are proposed recently. In this paper, we develop a SSPCR framework suitable for the end-to-end PCR models for the first time. Overall, we use the current models to generate pseudo labels for unlabeled images, which are in turn utilized to supervise the models training. Besides, we introduce a co-teaching strategy to overcome the confirmation bias problem that generally exists in self-training. A distribution alignment technique is also incorporated to produce high-quality, unbiased pseudo labels for unlabeled data. Experimental results on four histopathology datasets concerning different types of staining styles show the effectiveness and versatility of the proposed framework. Code is available at \textcolor{magenta}{\url{https://github.com/windygooo/SSPCR}
PathAsst: Redefining Pathology through Generative Foundation AI Assistant for Pathology
May 24, 2023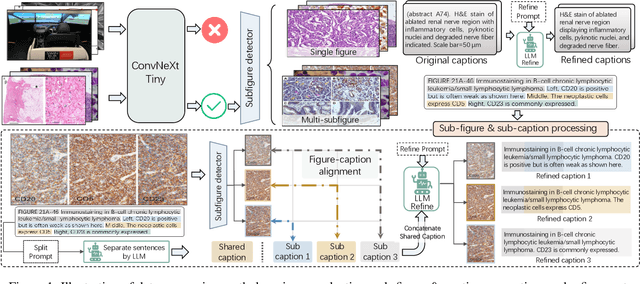


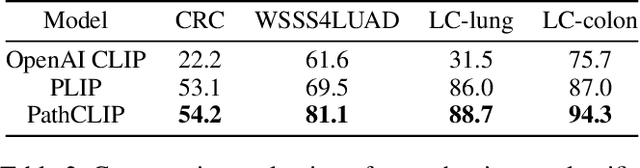
As advances in large language models (LLMs) and multimodal techniques continue to mature, the development of general-purpose multimodal large language models (MLLMs) has surged, with significant applications in natural image interpretation. However, the field of pathology has largely remained untapped in this regard, despite the growing need for accurate, timely, and personalized diagnostics. To bridge the gap in pathology MLLMs, we present the PathAsst in this study, which is a generative foundation AI assistant to revolutionize diagnostic and predictive analytics in pathology. To develop PathAsst, we collect over 142K high-quality pathology image-text pairs from a variety of reliable sources, including PubMed, comprehensive pathology textbooks, reputable pathology websites, and private data annotated by pathologists. Leveraging the advanced capabilities of ChatGPT/GPT-4, we generate over 180K instruction-following samples. Furthermore, we devise additional instruction-following data, specifically tailored for the invocation of the pathology-specific models, allowing the PathAsst to effectively interact with these models based on the input image and user intent, consequently enhancing the model's diagnostic capabilities. Subsequently, our PathAsst is trained based on Vicuna-13B language model in coordination with the CLIP vision encoder. The results of PathAsst show the potential of harnessing the AI-powered generative foundation model to improve pathology diagnosis and treatment processes. We are committed to open-sourcing our meticulously curated dataset, as well as a comprehensive toolkit designed to aid researchers in the extensive collection and preprocessing of their own datasets. Resources can be obtained at https://github.com/superjamessyx/Generative-Foundation-AI-Assistant-for-Pathology.
Deformable Proposal-Aware P2PNet: A Universal Network for Cell Recognition under Point Supervision
Mar 05, 2023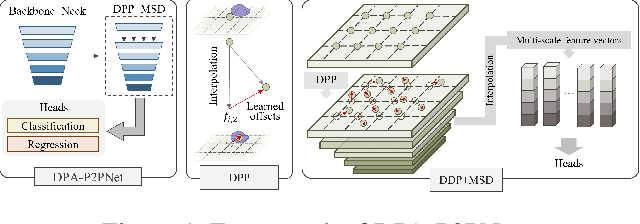


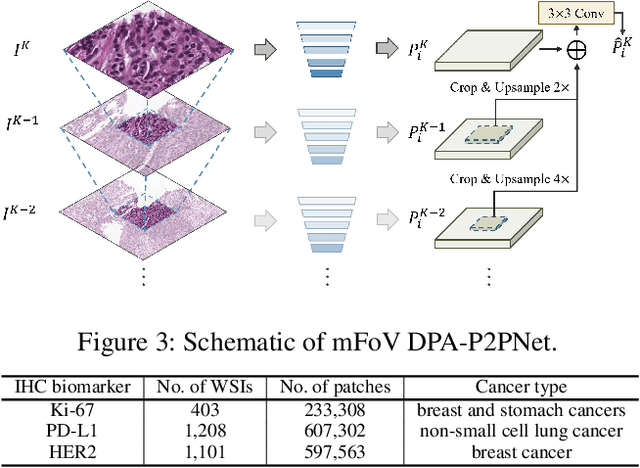
Point-based cell recognition, which aims to localize and classify cells present in a pathology image, is a fundamental task in digital pathology image analysis. The recently developed point-to-point network (P2PNet) has achieved unprecedented cell recognition accuracy and efficiency compared to methods that rely on intermediate density map representations. However, P2PNet could not leverage multi-scale information since it can only decode a single feature map. Moreover, the distribution of predefined point proposals, which is determined by data properties, restricts the resolution of the feature map to decode, i.e., the encoder design. To lift these limitations, we propose a variant of P2PNet named deformable proposal-aware P2PNet (DPA-P2PNet) in this study. The proposed method uses coordinates of point proposals to directly extract multi-scale region-of-interest (ROI) features for feature enhancement. Such a design also opens up possibilities to exploit dynamic distributions of proposals. We further devise a deformation module to improve the proposal quality. Extensive experiments on four datasets with various staining styles demonstrate that DPA-P2PNet outperforms the state-of-the-art methods on point-based cell recognition, which reveals the high potentiality in assisting pathologist assessments.