 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMem-World: Memory-Augmented Action-Conditioned World Models for Persistent Robot Manipulation
Jun 18, 2026Action-conditioned world models have emerged as a promising paradigm for robot learning, offering a scalable alternative to costly real-world experimentation by generating action-consistent video rollouts. However, persistent world modeling remains challenging in manipulation: frequent end-effector occlusions and rapid wrist-camera motion make the current observation insufficient for predicting future views, causing models to forget or hallucinate scene details seen in earlier frames. Existing memory retrieval strategies often fail to identify informative history in dynamic manipulation scenarios. To address this limitation, we propose Mem-World, a memory-augmented multi-view action-conditioned world model. At its core, we present W-VMem, a 4D wrist-view-centered surfel-indexed memory that anchors historical observations to temporally evolving surface elements. By explicitly modeling when and where scene elements are observed, W-VMem enables geometry-aware retrieval of relevant history frames conditioned on future actions. During generation, relevant history frames are selected via surfel-based rendering and scoring, providing informative and non-redundant context for prediction. Extensive experiments show that Mem-World generates persistent rollouts in complex manipulation scenarios, enables more reliable policy evaluation than Ctrl-World, improving the Pearson correlation with real-world performance by 14.5\%, and supports effective policy improvement through synthetic data generation, increasing success rates from 58\% to 72\% on long-horizon tasks.
Co-VLA: Coordination-Aware Structured Action Modeling for Dual-Arm Vision-Language-Action Systems
Jun 18, 2026Vision-language-action (VLA) models show strong capabilities in single and dual-arm robotic manipulation. Prior works show coordinated bimanual behaviors can emerge from end-to-end learning, leveraging large vision-language backbones with continuous action prediction. However, as bimanual tasks become tightly coupled and execution constraints become critical, implicit coordination alone is insufficient to ensure reliable, interpretable, and stable behavior. In this work, we propose Co-VLA, a coordination-aware bimanual manipulation framework introducing explicit structural priors into VLA models. We instantiate our method on a state-of-the-art vision-language backbone by replacing its monolithic action head with a Structured Action Expert (SAE) designed for bimanual coordination. Specifically, we introduce explicit structure at the action generation level with a modular coordination-aware loss that shapes shared and residual latents according to task-specific structures. The shared latent encodes task-level coordination intent, while residual latents capture execution adjustments for each arm. At deployment, a Latent-Aware Controller (LAC) interprets the learned representations to modulate synchronization strength, execution asymmetry, smoothness, and safety constraints in real time. LAC operates at the joint-command level and remains compatible with standard control pipelines without requiring force or impedance control. Experiments across simulation and real-world benchmarks show Co-VLA significantly outperforms monolithic baselines, achieving a 27% success rate gain in tight-coordination tasks, more than doubling performance in OOD real-world scenarios (from 13% to 27%), and reducing task completion time by up to 25%.
DAM-VLA: A Dynamic Action Model-Based Vision-Language-Action Framework for Robot Manipulation
Mar 01, 2026In dynamic environments such as warehouses, hospitals, and homes, robots must seamlessly transition between gross motion and precise manipulations to complete complex tasks. However, current Vision-Language-Action (VLA) frameworks, largely adapted from pre-trained Vision-Language Models (VLMs), often struggle to reconcile general task adaptability with the specialized precision required for intricate manipulation. To address this challenge, we propose DAM-VLA, a dynamic action model-based VLA framework. DAM-VLA integrates VLM reasoning with diffusion-based action models specialized for arm and gripper control. Specifically, it introduces (i) an action routing mechanism, using task-specific visual and linguistic cues to select appropriate action models (e.g., arm movement or gripper manipulation), (ii) a dynamic action model that fuses high-level VLM cognition with low-level visual features to predict actions, and (iii) a dual-scale action weighting mechanism that enables dynamic coordination between the arm-movement and gripper-manipulation models. Across extensive evaluations, DAM-VLA achieves superior success rates compared to state-of-the-art VLA methods in simulated (SIMPLER, FurnitureBench) and real-world settings, showing robust generalization from standard pick-and-place to demanding long-horizon and contact-rich tasks.
MoSE: Skill-by-Skill Mixture-of-Expert Learning for Autonomous Driving
Jul 10, 2025
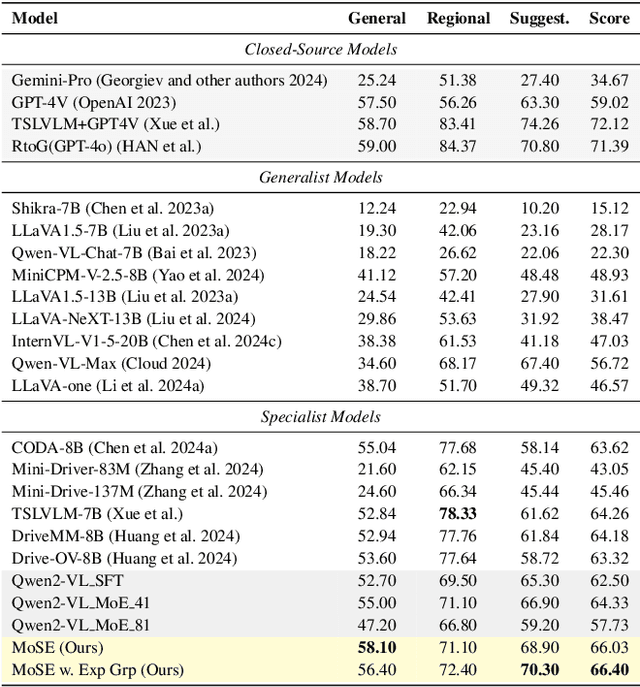
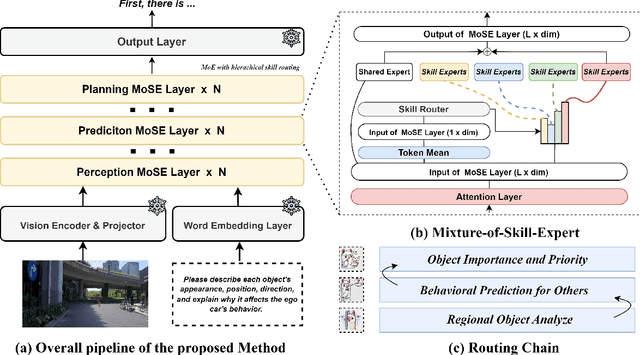
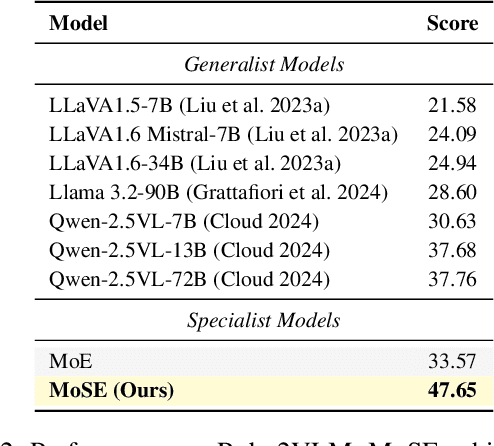
Recent studies show large language models (LLMs) and vision language models (VLMs) trained using web-scale data can empower end-to-end autonomous driving systems for a better generalization and interpretation. Specifically, by dynamically routing inputs to specialized subsets of parameters, the Mixture-of-Experts (MoE) technique enables general LLMs or VLMs to achieve substantial performance improvements while maintaining computational efficiency. However, general MoE models usually demands extensive training data and complex optimization. In this work, inspired by the learning process of human drivers, we propose a skill-oriented MoE, called MoSE, which mimics human drivers' learning process and reasoning process, skill-by-skill and step-by-step. We propose a skill-oriented routing mechanism that begins with defining and annotating specific skills, enabling experts to identify the necessary driving competencies for various scenarios and reasoning tasks, thereby facilitating skill-by-skill learning. Further align the driving process to multi-step planning in human reasoning and end-to-end driving models, we build a hierarchical skill dataset and pretrain the router to encourage the model to think step-by-step. Unlike multi-round dialogs, MoSE integrates valuable auxiliary tasks (e.g.\ description, reasoning, planning) in one single forward process without introducing any extra computational cost. With less than 3B sparsely activated parameters, our model outperforms several 8B+ parameters on CODA AD corner case reasoning task. Compared to existing methods based on open-source models and data, our approach achieves state-of-the-art performance with significantly reduced activated model size (at least by $62.5\%$) with a single-turn conversation.
DomainCQA: Crafting Expert-Level QA from Domain-Specific Charts
Mar 25, 2025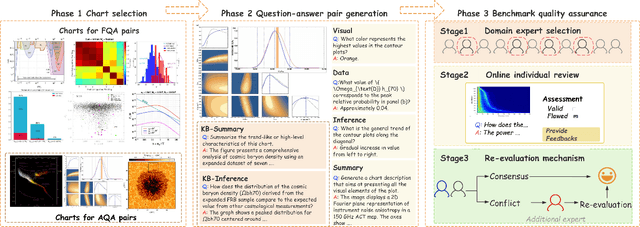
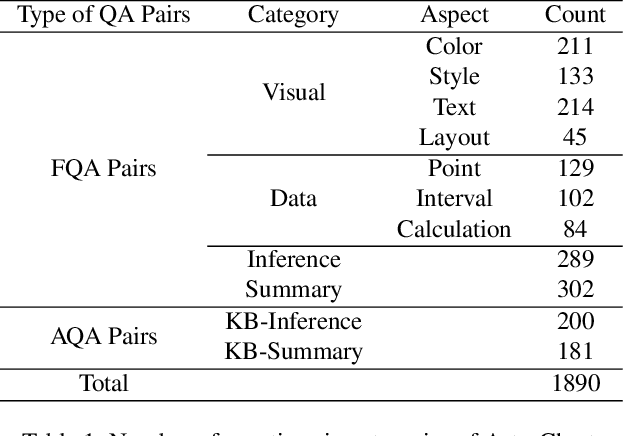
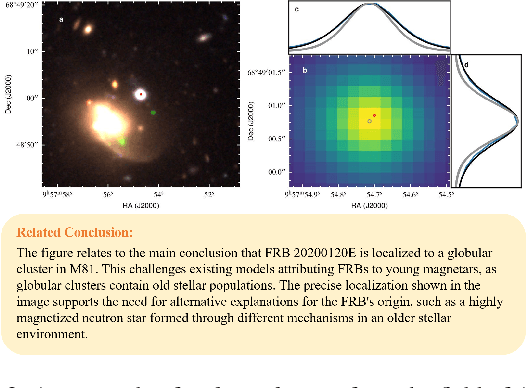
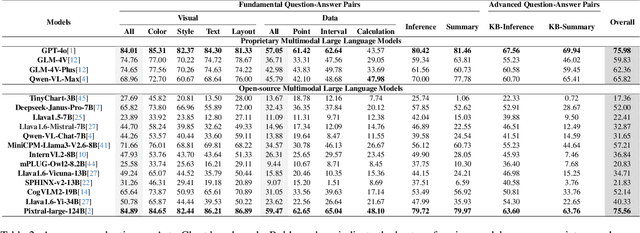
Chart Question Answering (CQA) benchmarks are essential for evaluating the capability of Multimodal Large Language Models (MLLMs) to interpret visual data. However, current benchmarks focus primarily on the evaluation of general-purpose CQA but fail to adequately capture domain-specific challenges. We introduce DomainCQA, a systematic methodology for constructing domain-specific CQA benchmarks, and demonstrate its effectiveness by developing AstroChart, a CQA benchmark in the field of astronomy. Our evaluation shows that chart reasoning and combining chart information with domain knowledge for deeper analysis and summarization, rather than domain-specific knowledge, pose the primary challenge for existing MLLMs, highlighting a critical gap in current benchmarks. By providing a scalable and rigorous framework, DomainCQA enables more precise assessment and improvement of MLLMs for domain-specific applications.
MapFusion: A Novel BEV Feature Fusion Network for Multi-modal Map Construction
Feb 05, 2025Map construction task plays a vital role in providing precise and comprehensive static environmental information essential for autonomous driving systems. Primary sensors include cameras and LiDAR, with configurations varying between camera-only, LiDAR-only, or camera-LiDAR fusion, based on cost-performance considerations. While fusion-based methods typically perform best, existing approaches often neglect modality interaction and rely on simple fusion strategies, which suffer from the problems of misalignment and information loss. To address these issues, we propose MapFusion, a novel multi-modal Bird's-Eye View (BEV) feature fusion method for map construction. Specifically, to solve the semantic misalignment problem between camera and LiDAR BEV features, we introduce the Cross-modal Interaction Transform (CIT) module, enabling interaction between two BEV feature spaces and enhancing feature representation through a self-attention mechanism. Additionally, we propose an effective Dual Dynamic Fusion (DDF) module to adaptively select valuable information from different modalities, which can take full advantage of the inherent information between different modalities. Moreover, MapFusion is designed to be simple and plug-and-play, easily integrated into existing pipelines. We evaluate MapFusion on two map construction tasks, including High-definition (HD) map and BEV map segmentation, to show its versatility and effectiveness. Compared with the state-of-the-art methods, MapFusion achieves 3.6% and 6.2% absolute improvements on the HD map construction and BEV map segmentation tasks on the nuScenes dataset, respectively, demonstrating the superiority of our approach.
Terahertz Channels in Atmospheric Conditions: Propagation Characteristics and Security Performance
Aug 28, 2024



With the growing demand for higher wireless data rates, the interest in extending the carrier frequency of wireless links to the terahertz (THz) range has significantly increased. For long-distance outdoor wireless communications, THz channels may suffer substantial power loss and security issues due to atmospheric weather effects. It is crucial to assess the impact of weather on high-capacity data transmission to evaluate wireless system link budgets and performance accurately. In this article, we provide an insight into the propagation characteristics of THz channels under atmospheric conditions and the security aspects of THz communication systems in future applications. We conduct a comprehensive survey of our recent research and experimental findings on THz channel transmission and physical layer security, synthesizing and categorizing the state-of-the-art research in this domain. Our analysis encompasses various atmospheric phenomena, including molecular absorption, scattering effects, and turbulence, elucidating their intricate interactions with THz waves and the resultant implications for channel modeling and system design. Furthermore, we investigate the unique security challenges posed by THz communications, examining potential vulnerabilities and proposing novel countermeasures to enhance the resilience of these high-frequency systems against eavesdropping and other security threats. Finally, we discuss the challenges and limitations of such high-frequency wireless communications and provide insights into future research prospects for realizing the 6G vision, emphasizing the need for innovative solutions to overcome the atmospheric hurdles and security concerns in THz communications.
Large Language Models Understand Layouts
Jul 08, 2024Large language models (LLMs) demonstrate extraordinary abilities in a wide range of natural language processing (NLP) tasks. In this paper, we show that, beyond text understanding capability, LLMs are capable of processing text layouts that are denoted by spatial markers. They are able to answer questions that require explicit spatial perceiving and reasoning, while a drastic performance drop is observed when the spatial markers from the original data are excluded. We perform a series of experiments with the GPT-3.5, Baichuan2, Llama2 and ChatGLM3 models on various types of layout-sensitive datasets for further analysis. The experimental results reveal that the layout understanding ability of LLMs is mainly introduced by the coding data for pretraining, which is further enhanced at the instruction-tuning stage. In addition, layout understanding can be enhanced by integrating low-cost, auto-generated data approached by a novel text game. Finally, we show that layout understanding ability is beneficial for building efficient visual question-answering (VQA) systems.
Is Your HD Map Constructor Reliable under Sensor Corruptions?
Jun 18, 2024



Driving systems often rely on high-definition (HD) maps for precise environmental information, which is crucial for planning and navigation. While current HD map constructors perform well under ideal conditions, their resilience to real-world challenges, \eg, adverse weather and sensor failures, is not well understood, raising safety concerns. This work introduces MapBench, the first comprehensive benchmark designed to evaluate the robustness of HD map construction methods against various sensor corruptions. Our benchmark encompasses a total of 29 types of corruptions that occur from cameras and LiDAR sensors. Extensive evaluations across 31 HD map constructors reveal significant performance degradation of existing methods under adverse weather conditions and sensor failures, underscoring critical safety concerns. We identify effective strategies for enhancing robustness, including innovative approaches that leverage multi-modal fusion, advanced data augmentation, and architectural techniques. These insights provide a pathway for developing more reliable HD map construction methods, which are essential for the advancement of autonomous driving technology. The benchmark toolkit and affiliated code and model checkpoints have been made publicly accessible.
Lightweight Change Detection in Heterogeneous Remote Sensing Images with Online All-Integer Pruning Training
May 03, 2024Detection of changes in heterogeneous remote sensing images is vital, especially in response to emergencies like earthquakes and floods. Current homogenous transformation-based change detection (CD) methods often suffer from high computation and memory costs, which are not friendly to edge-computation devices like onboard CD devices at satellites. To address this issue, this paper proposes a new lightweight CD method for heterogeneous remote sensing images that employs the online all-integer pruning (OAIP) training strategy to efficiently fine-tune the CD network using the current test data. The proposed CD network consists of two visual geometry group (VGG) subnetworks as the backbone architecture. In the OAIP-based training process, all the weights, gradients, and intermediate data are quantized to integers to speed up training and reduce memory usage, where the per-layer block exponentiation scaling scheme is utilized to reduce the computation errors of network parameters caused by quantization. Second, an adaptive filter-level pruning method based on the L1-norm criterion is employed to further lighten the fine-tuning process of the CD network. Experimental results show that the proposed OAIP-based method attains similar detection performance (but with significantly reduced computation complexity and memory usage) in comparison with state-of-the-art CD methods.