 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo-VLA: Coordination-Aware Structured Action Modeling for Dual-Arm Vision-Language-Action Systems
Jun 18, 2026Vision-language-action (VLA) models show strong capabilities in single and dual-arm robotic manipulation. Prior works show coordinated bimanual behaviors can emerge from end-to-end learning, leveraging large vision-language backbones with continuous action prediction. However, as bimanual tasks become tightly coupled and execution constraints become critical, implicit coordination alone is insufficient to ensure reliable, interpretable, and stable behavior. In this work, we propose Co-VLA, a coordination-aware bimanual manipulation framework introducing explicit structural priors into VLA models. We instantiate our method on a state-of-the-art vision-language backbone by replacing its monolithic action head with a Structured Action Expert (SAE) designed for bimanual coordination. Specifically, we introduce explicit structure at the action generation level with a modular coordination-aware loss that shapes shared and residual latents according to task-specific structures. The shared latent encodes task-level coordination intent, while residual latents capture execution adjustments for each arm. At deployment, a Latent-Aware Controller (LAC) interprets the learned representations to modulate synchronization strength, execution asymmetry, smoothness, and safety constraints in real time. LAC operates at the joint-command level and remains compatible with standard control pipelines without requiring force or impedance control. Experiments across simulation and real-world benchmarks show Co-VLA significantly outperforms monolithic baselines, achieving a 27% success rate gain in tight-coordination tasks, more than doubling performance in OOD real-world scenarios (from 13% to 27%), and reducing task completion time by up to 25%.
Mem-World: Memory-Augmented Action-Conditioned World Models for Persistent Robot Manipulation
Jun 18, 2026Action-conditioned world models have emerged as a promising paradigm for robot learning, offering a scalable alternative to costly real-world experimentation by generating action-consistent video rollouts. However, persistent world modeling remains challenging in manipulation: frequent end-effector occlusions and rapid wrist-camera motion make the current observation insufficient for predicting future views, causing models to forget or hallucinate scene details seen in earlier frames. Existing memory retrieval strategies often fail to identify informative history in dynamic manipulation scenarios. To address this limitation, we propose Mem-World, a memory-augmented multi-view action-conditioned world model. At its core, we present W-VMem, a 4D wrist-view-centered surfel-indexed memory that anchors historical observations to temporally evolving surface elements. By explicitly modeling when and where scene elements are observed, W-VMem enables geometry-aware retrieval of relevant history frames conditioned on future actions. During generation, relevant history frames are selected via surfel-based rendering and scoring, providing informative and non-redundant context for prediction. Extensive experiments show that Mem-World generates persistent rollouts in complex manipulation scenarios, enables more reliable policy evaluation than Ctrl-World, improving the Pearson correlation with real-world performance by 14.5\%, and supports effective policy improvement through synthetic data generation, increasing success rates from 58\% to 72\% on long-horizon tasks.
DAM-VLA: A Dynamic Action Model-Based Vision-Language-Action Framework for Robot Manipulation
Mar 01, 2026In dynamic environments such as warehouses, hospitals, and homes, robots must seamlessly transition between gross motion and precise manipulations to complete complex tasks. However, current Vision-Language-Action (VLA) frameworks, largely adapted from pre-trained Vision-Language Models (VLMs), often struggle to reconcile general task adaptability with the specialized precision required for intricate manipulation. To address this challenge, we propose DAM-VLA, a dynamic action model-based VLA framework. DAM-VLA integrates VLM reasoning with diffusion-based action models specialized for arm and gripper control. Specifically, it introduces (i) an action routing mechanism, using task-specific visual and linguistic cues to select appropriate action models (e.g., arm movement or gripper manipulation), (ii) a dynamic action model that fuses high-level VLM cognition with low-level visual features to predict actions, and (iii) a dual-scale action weighting mechanism that enables dynamic coordination between the arm-movement and gripper-manipulation models. Across extensive evaluations, DAM-VLA achieves superior success rates compared to state-of-the-art VLA methods in simulated (SIMPLER, FurnitureBench) and real-world settings, showing robust generalization from standard pick-and-place to demanding long-horizon and contact-rich tasks.
MoSE: Skill-by-Skill Mixture-of-Expert Learning for Autonomous Driving
Jul 10, 2025
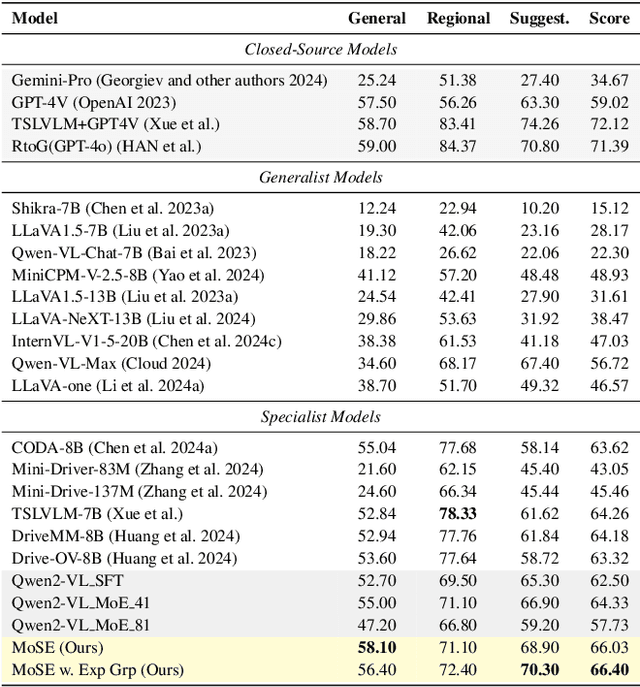
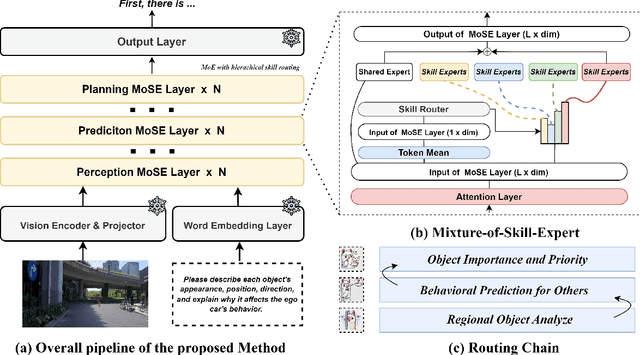
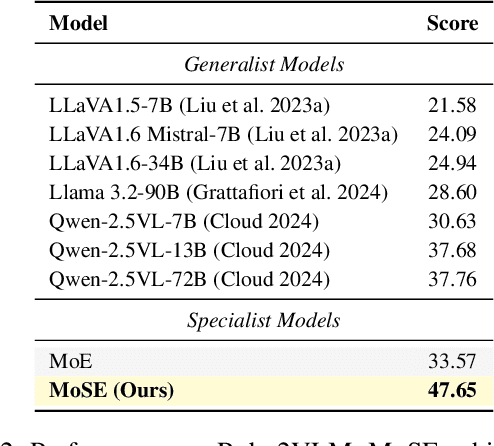
Recent studies show large language models (LLMs) and vision language models (VLMs) trained using web-scale data can empower end-to-end autonomous driving systems for a better generalization and interpretation. Specifically, by dynamically routing inputs to specialized subsets of parameters, the Mixture-of-Experts (MoE) technique enables general LLMs or VLMs to achieve substantial performance improvements while maintaining computational efficiency. However, general MoE models usually demands extensive training data and complex optimization. In this work, inspired by the learning process of human drivers, we propose a skill-oriented MoE, called MoSE, which mimics human drivers' learning process and reasoning process, skill-by-skill and step-by-step. We propose a skill-oriented routing mechanism that begins with defining and annotating specific skills, enabling experts to identify the necessary driving competencies for various scenarios and reasoning tasks, thereby facilitating skill-by-skill learning. Further align the driving process to multi-step planning in human reasoning and end-to-end driving models, we build a hierarchical skill dataset and pretrain the router to encourage the model to think step-by-step. Unlike multi-round dialogs, MoSE integrates valuable auxiliary tasks (e.g.\ description, reasoning, planning) in one single forward process without introducing any extra computational cost. With less than 3B sparsely activated parameters, our model outperforms several 8B+ parameters on CODA AD corner case reasoning task. Compared to existing methods based on open-source models and data, our approach achieves state-of-the-art performance with significantly reduced activated model size (at least by $62.5\%$) with a single-turn conversation.
DVI-SLAM: A Dual Visual Inertial SLAM Network
Sep 25, 2023



Recent deep learning based visual simultaneous localization and mapping (SLAM) methods have made significant progress. However, how to make full use of visual information as well as better integrate with inertial measurement unit (IMU) in visual SLAM has potential research value. This paper proposes a novel deep SLAM network with dual visual factors. The basic idea is to integrate both photometric factor and re-projection factor into the end-to-end differentiable structure through multi-factor data association module. We show that the proposed network dynamically learns and adjusts the confidence maps of both visual factors and it can be further extended to include the IMU factors as well. Extensive experiments validate that our proposed method significantly outperforms the state-of-the-art methods on several public datasets, including TartanAir, EuRoC and ETH3D-SLAM. Specifically, when dynamically fusing the three factors together, the absolute trajectory error for both monocular and stereo configurations on EuRoC dataset has reduced by 45.3% and 36.2% respectively.
Accurate Visual-Inertial SLAM by Feature Re-identification
Feb 26, 2021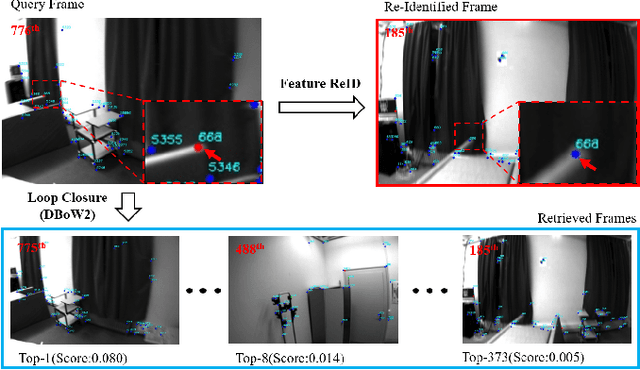
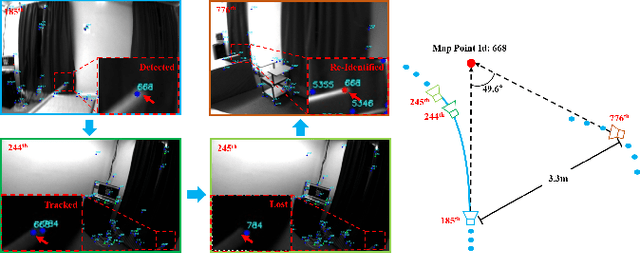
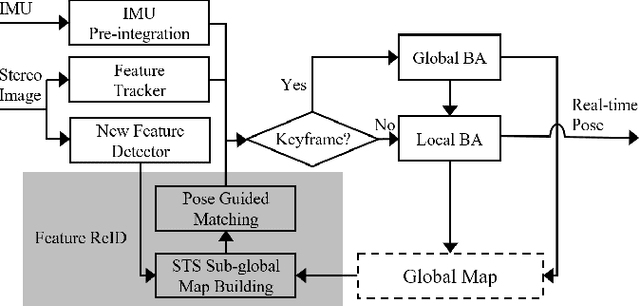
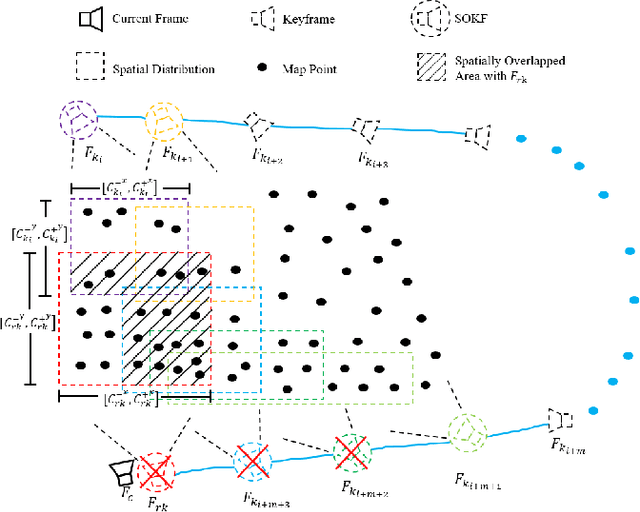
We propose a novel feature re-identification method for real-time visual-inertial SLAM. The front-end module of the state-of-the-art visual-inertial SLAM methods (e.g. visual feature extraction and matching schemes) relies on feature tracks across image frames, which are easily broken in challenging scenarios, resulting in insufficient visual measurement and accumulated error in pose estimation. In this paper, we propose an efficient drift-less SLAM method by re-identifying existing features from a spatial-temporal sensitive sub-global map. The re-identified features over a long time span serve as augmented visual measurements and are incorporated into the optimization module which can gradually decrease the accumulative error in the long run, and further build a drift-less global map in the system. Extensive experiments show that our feature re-identification method is both effective and efficient. Specifically, when combining the feature re-identification with the state-of-the-art SLAM method [11], our method achieves 67.3% and 87.5% absolute translation error reduction with only a small additional computational cost on two public SLAM benchmark DBs: EuRoC and TUM-VI respectively.