 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAM-VLA: A Dynamic Action Model-Based Vision-Language-Action Framework for Robot Manipulation
Mar 01, 2026In dynamic environments such as warehouses, hospitals, and homes, robots must seamlessly transition between gross motion and precise manipulations to complete complex tasks. However, current Vision-Language-Action (VLA) frameworks, largely adapted from pre-trained Vision-Language Models (VLMs), often struggle to reconcile general task adaptability with the specialized precision required for intricate manipulation. To address this challenge, we propose DAM-VLA, a dynamic action model-based VLA framework. DAM-VLA integrates VLM reasoning with diffusion-based action models specialized for arm and gripper control. Specifically, it introduces (i) an action routing mechanism, using task-specific visual and linguistic cues to select appropriate action models (e.g., arm movement or gripper manipulation), (ii) a dynamic action model that fuses high-level VLM cognition with low-level visual features to predict actions, and (iii) a dual-scale action weighting mechanism that enables dynamic coordination between the arm-movement and gripper-manipulation models. Across extensive evaluations, DAM-VLA achieves superior success rates compared to state-of-the-art VLA methods in simulated (SIMPLER, FurnitureBench) and real-world settings, showing robust generalization from standard pick-and-place to demanding long-horizon and contact-rich tasks.
MoSE: Skill-by-Skill Mixture-of-Expert Learning for Autonomous Driving
Jul 10, 2025
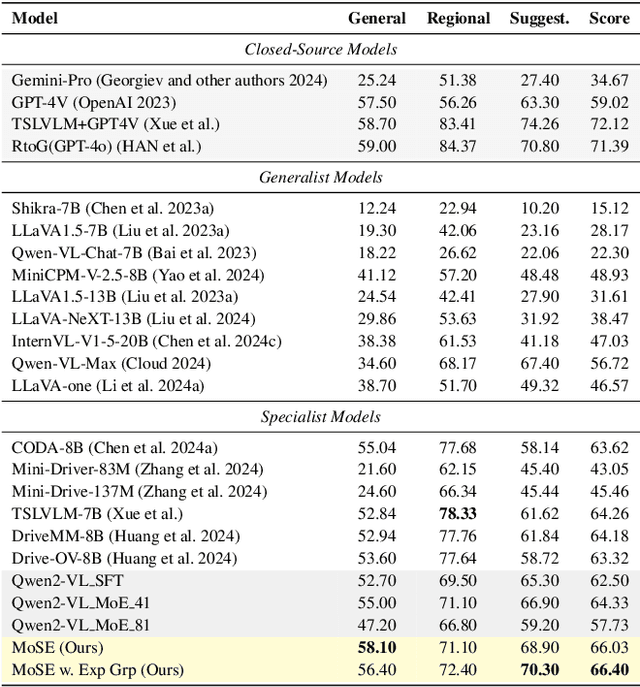
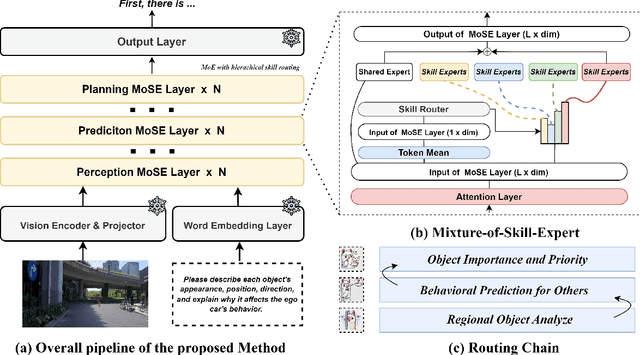
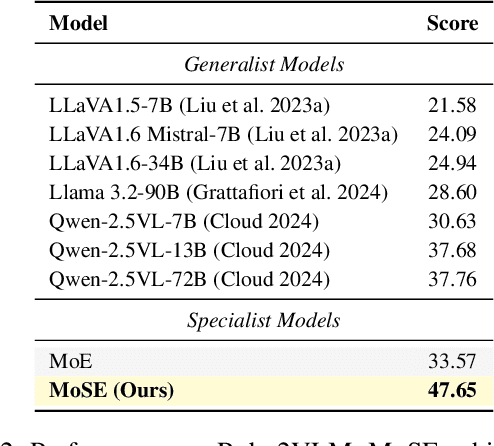
Recent studies show large language models (LLMs) and vision language models (VLMs) trained using web-scale data can empower end-to-end autonomous driving systems for a better generalization and interpretation. Specifically, by dynamically routing inputs to specialized subsets of parameters, the Mixture-of-Experts (MoE) technique enables general LLMs or VLMs to achieve substantial performance improvements while maintaining computational efficiency. However, general MoE models usually demands extensive training data and complex optimization. In this work, inspired by the learning process of human drivers, we propose a skill-oriented MoE, called MoSE, which mimics human drivers' learning process and reasoning process, skill-by-skill and step-by-step. We propose a skill-oriented routing mechanism that begins with defining and annotating specific skills, enabling experts to identify the necessary driving competencies for various scenarios and reasoning tasks, thereby facilitating skill-by-skill learning. Further align the driving process to multi-step planning in human reasoning and end-to-end driving models, we build a hierarchical skill dataset and pretrain the router to encourage the model to think step-by-step. Unlike multi-round dialogs, MoSE integrates valuable auxiliary tasks (e.g.\ description, reasoning, planning) in one single forward process without introducing any extra computational cost. With less than 3B sparsely activated parameters, our model outperforms several 8B+ parameters on CODA AD corner case reasoning task. Compared to existing methods based on open-source models and data, our approach achieves state-of-the-art performance with significantly reduced activated model size (at least by $62.5\%$) with a single-turn conversation.
3D Occupancy Prediction with Low-Resolution Queries via Prototype-aware View Transformation
Mar 19, 2025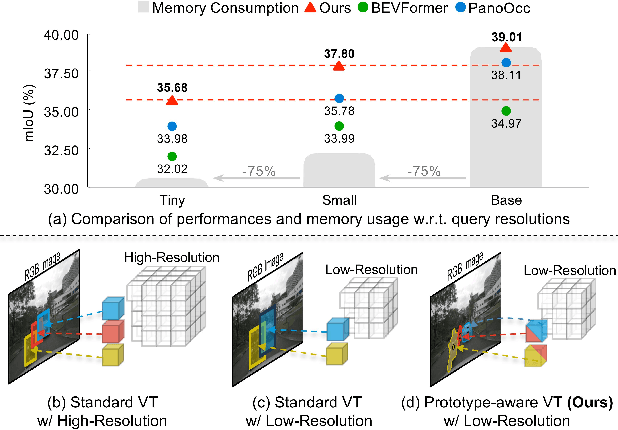
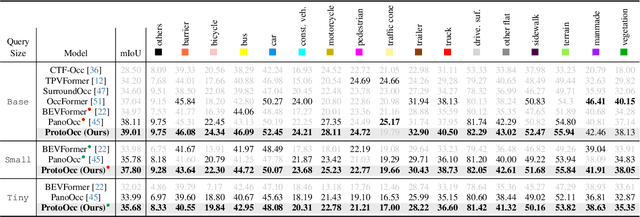
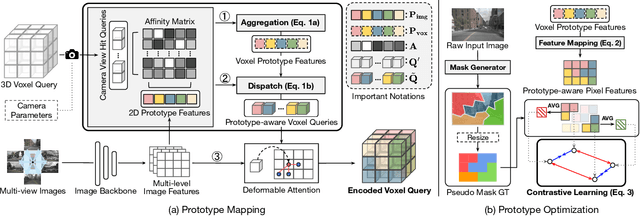
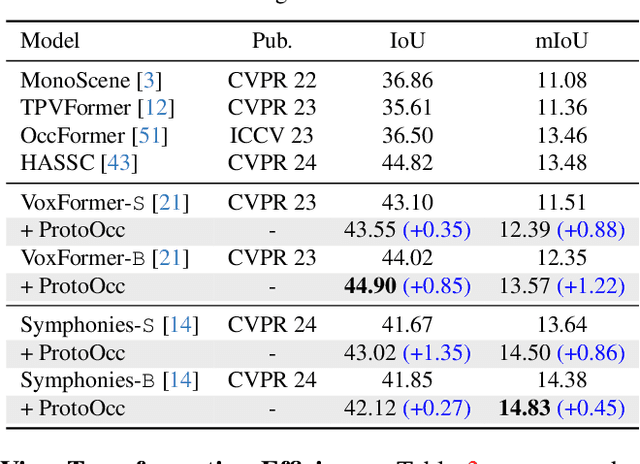
The resolution of voxel queries significantly influences the quality of view transformation in camera-based 3D occupancy prediction. However, computational constraints and the practical necessity for real-time deployment require smaller query resolutions, which inevitably leads to an information loss. Therefore, it is essential to encode and preserve rich visual details within limited query sizes while ensuring a comprehensive representation of 3D occupancy. To this end, we introduce ProtoOcc, a novel occupancy network that leverages prototypes of clustered image segments in view transformation to enhance low-resolution context. In particular, the mapping of 2D prototypes onto 3D voxel queries encodes high-level visual geometries and complements the loss of spatial information from reduced query resolutions. Additionally, we design a multi-perspective decoding strategy to efficiently disentangle the densely compressed visual cues into a high-dimensional 3D occupancy scene. Experimental results on both Occ3D and SemanticKITTI benchmarks demonstrate the effectiveness of the proposed method, showing clear improvements over the baselines. More importantly, ProtoOcc achieves competitive performance against the baselines even with 75\% reduced voxel resolution.
Unified Domain Generalization and Adaptation for Multi-View 3D Object Detection
Oct 29, 2024



Recent advances in 3D object detection leveraging multi-view cameras have demonstrated their practical and economical value in various challenging vision tasks. However, typical supervised learning approaches face challenges in achieving satisfactory adaptation toward unseen and unlabeled target datasets (\ie, direct transfer) due to the inevitable geometric misalignment between the source and target domains. In practice, we also encounter constraints on resources for training models and collecting annotations for the successful deployment of 3D object detectors. In this paper, we propose Unified Domain Generalization and Adaptation (UDGA), a practical solution to mitigate those drawbacks. We first propose Multi-view Overlap Depth Constraint that leverages the strong association between multi-view, significantly alleviating geometric gaps due to perspective view changes. Then, we present a Label-Efficient Domain Adaptation approach to handle unfamiliar targets with significantly fewer amounts of labels (\ie, 1$\%$ and 5$\%)$, while preserving well-defined source knowledge for training efficiency. Overall, UDGA framework enables stable detection performance in both source and target domains, effectively bridging inevitable domain gaps, while demanding fewer annotations. We demonstrate the robustness of UDGA with large-scale benchmarks: nuScenes, Lyft, and Waymo, where our framework outperforms the current state-of-the-art methods.
Compositional Conservatism: A Transductive Approach in Offline Reinforcement Learning
Apr 06, 2024Offline reinforcement learning (RL) is a compelling framework for learning optimal policies from past experiences without additional interaction with the environment. Nevertheless, offline RL inevitably faces the problem of distributional shifts, where the states and actions encountered during policy execution may not be in the training dataset distribution. A common solution involves incorporating conservatism into the policy or the value function to safeguard against uncertainties and unknowns. In this work, we focus on achieving the same objectives of conservatism but from a different perspective. We propose COmpositional COnservatism with Anchor-seeking (COCOA) for offline RL, an approach that pursues conservatism in a compositional manner on top of the transductive reparameterization (Netanyahu et al., 2023), which decomposes the input variable (the state in our case) into an anchor and its difference from the original input. Our COCOA seeks both in-distribution anchors and differences by utilizing the learned reverse dynamics model, encouraging conservatism in the compositional input space for the policy or value function. Such compositional conservatism is independent of and agnostic to the prevalent behavioral conservatism in offline RL. We apply COCOA to four state-of-the-art offline RL algorithms and evaluate them on the D4RL benchmark, where COCOA generally improves the performance of each algorithm. The code is available at https://github.com/runamu/compositional-conservatism.
CMDA: Cross-Modal and Domain Adversarial Adaptation for LiDAR-Based 3D Object Detection
Mar 07, 2024Recent LiDAR-based 3D Object Detection (3DOD) methods show promising results, but they often do not generalize well to target domains outside the source (or training) data distribution. To reduce such domain gaps and thus to make 3DOD models more generalizable, we introduce a novel unsupervised domain adaptation (UDA) method, called CMDA, which (i) leverages visual semantic cues from an image modality (i.e., camera images) as an effective semantic bridge to close the domain gap in the cross-modal Bird's Eye View (BEV) representations. Further, (ii) we also introduce a self-training-based learning strategy, wherein a model is adversarially trained to generate domain-invariant features, which disrupt the discrimination of whether a feature instance comes from a source or an unseen target domain. Overall, our CMDA framework guides the 3DOD model to generate highly informative and domain-adaptive features for novel data distributions. In our extensive experiments with large-scale benchmarks, such as nuScenes, Waymo, and KITTI, those mentioned above provide significant performance gains for UDA tasks, achieving state-of-the-art performance.
BackTrack: Robust template update via Backward Tracking of candidate template
Aug 21, 2023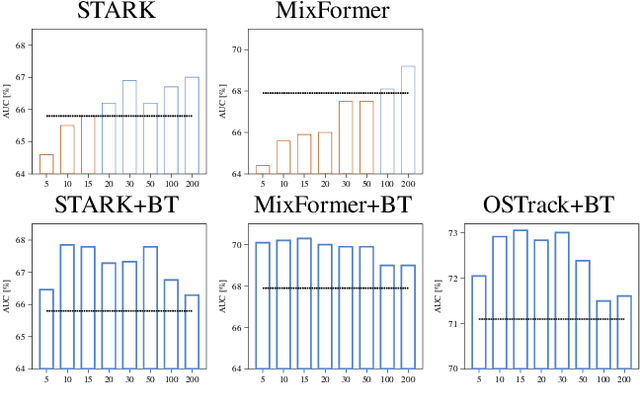

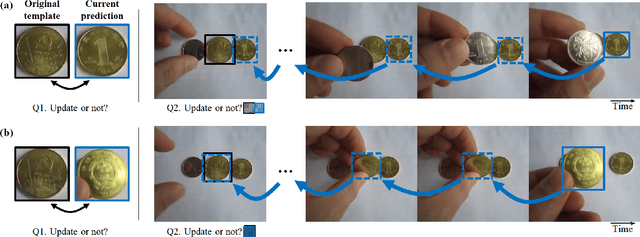

Variations of target appearance such as deformations, illumination variance, occlusion, etc., are the major challenges of visual object tracking that negatively impact the performance of a tracker. An effective method to tackle these challenges is template update, which updates the template to reflect the change of appearance in the target object during tracking. However, with template updates, inadequate quality of new templates or inappropriate timing of updates may induce a model drift problem, which severely degrades the tracking performance. Here, we propose BackTrack, a robust and reliable method to quantify the confidence of the candidate template by backward tracking it on the past frames. Based on the confidence score of candidates from BackTrack, we can update the template with a reliable candidate at the right time while rejecting unreliable candidates. BackTrack is a generic template update scheme and is applicable to any template-based trackers. Extensive experiments on various tracking benchmarks verify the effectiveness of BackTrack over existing template update algorithms, as it achieves SOTA performance on various tracking benchmarks.
A Gaussian Process Upsampling Model for Improvements in Optical Character Recognition
May 07, 2020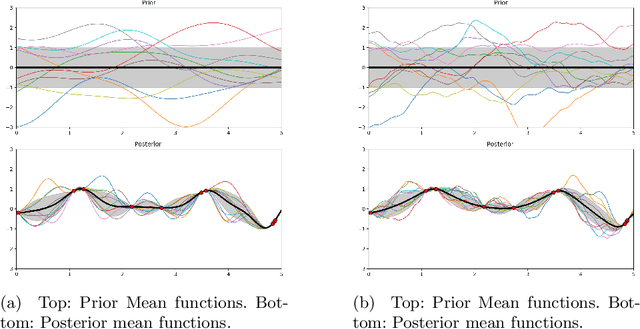

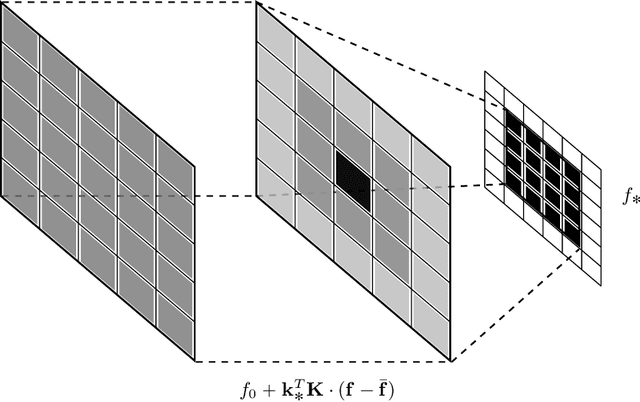

Optical Character Recognition and extraction is a key tool in the automatic evaluation of documents in a financial context. However, the image data provided to automated systems can have unreliable quality, and can be inherently low-resolution or downsampled and compressed by a transmitting program. In this paper, we illustrate the efficacy of a Gaussian Process upsampling model for the purposes of improving OCR and extraction through upsampling low resolution documents.
Which Contrast Does Matter? Towards a Deep Understanding of MR Contrast using Collaborative GAN
May 10, 2019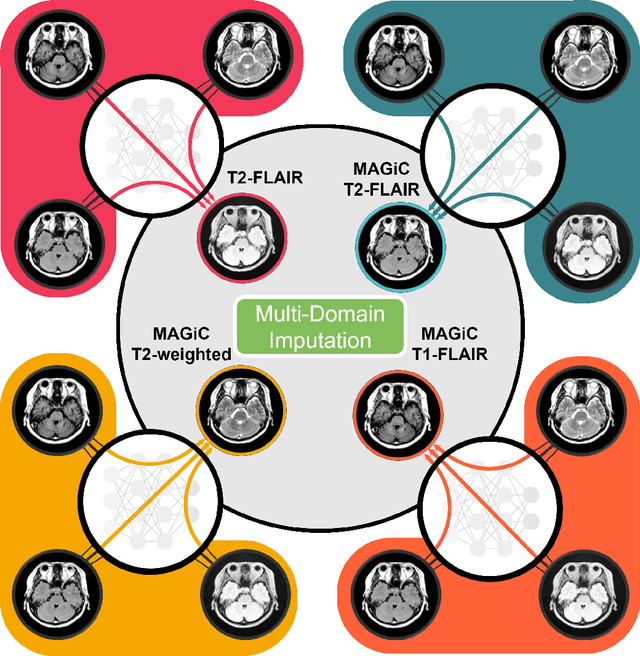
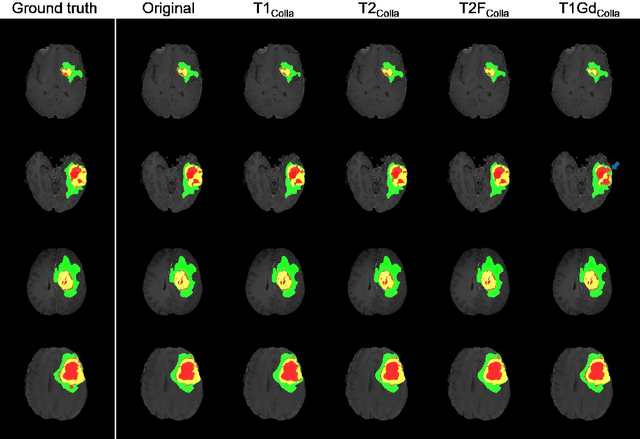
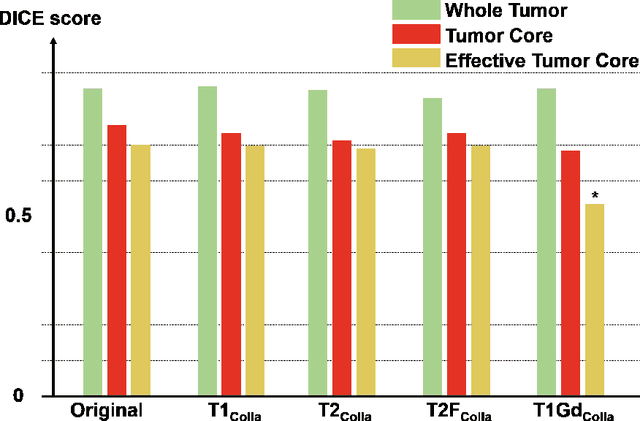
Thanks to the recent success of generative adversarial network (GAN) for image synthesis, there are many exciting GAN approaches that successfully synthesize MR image contrast from other images with different contrasts. These approaches are potentially important for image imputation problems, where complete set of data is often difficult to obtain and image synthesis is one of the key solutions for handling the missing data problem. Unfortunately, the lack of the scalability of the existing GAN-based image translation approaches poses a fundamental challenge to understand the nature of the MR contrast imputation problem: which contrast does matter? Here, we present a systematic approach using Collaborative Generative Adversarial Networks (CollaGAN), which enable the learning of the joint image manifold of multiple MR contrasts to investigate which contrasts are essential. Our experimental results showed that the exogenous contrast from contrast agents is not replaceable, but other endogenous contrast such as T1, T2, etc can be synthesized from other contrast. These findings may give important guidance to the acquisition protocol design for MR in real clinical environment.
CollaGAN : Collaborative GAN for Missing Image Data Imputation
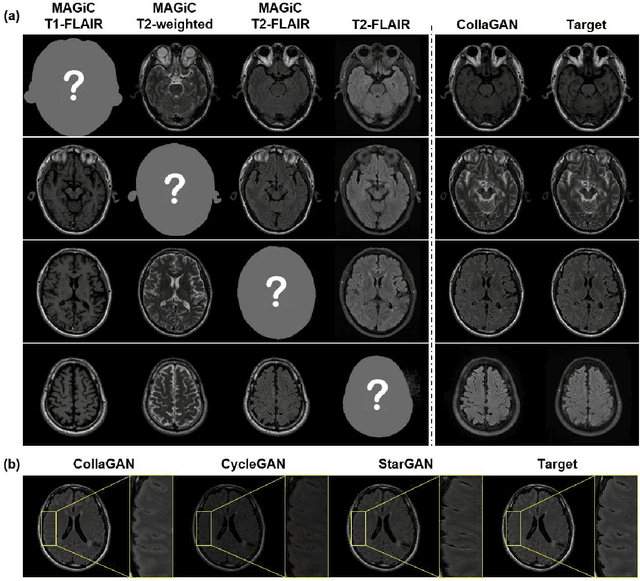
Jan 28, 2019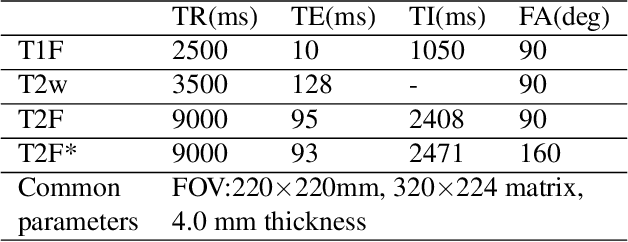


In many applications requiring multiple inputs to obtain a desired output, if any of the input data is missing, it often introduces large amounts of bias. Although many techniques have been developed for imputing missing data, the image imputation is still difficult due to complicated nature of natural images. To address this problem, here we proposed a novel framework for missing image data imputation, called Collaborative Generative Adversarial Network (CollaGAN). CollaGAN converts an image imputation problem to a multi-domain images-to-image translation task so that a single generator and discriminator network can successfully estimate the missing data using the remaining clean data set. We demonstrate that CollaGAN produces the images with a higher visual quality compared to the existing competing approaches in various image imputation tasks.