 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-SCALE: Grounded Multimodal Moral Reasoning via Scalar Judgment and Listwise Alignment
Feb 03, 2026Vision-Language Models (VLMs) continue to struggle to make morally salient judgments in multimodal and socially ambiguous contexts. Prior works typically rely on binary or pairwise supervision, which often fail to capture the continuous and pluralistic nature of human moral reasoning. We present MM-SCALE (Multimodal Moral Scale), a large-scale dataset for aligning VLMs with human moral preferences through 5-point scalar ratings and explicit modality grounding. Each image-scenario pair is annotated with moral acceptability scores and grounded reasoning labels by humans using an interface we tailored for data collection, enabling listwise preference optimization over ranked scenario sets. By moving from discrete to scalar supervision, our framework provides richer alignment signals and finer calibration of multimodal moral reasoning. Experiments show that VLMs fine-tuned on MM-SCALE achieve higher ranking fidelity and more stable safety calibration than those trained with binary signals.
Critical or Compliant? The Double-Edged Sword of Reasoning in Chain-of-Thought Explanations
Nov 19, 2025Explanations are often promoted as tools for transparency, but they can also foster confirmation bias; users may assume reasoning is correct whenever outputs appear acceptable. We study this double-edged role of Chain-of-Thought (CoT) explanations in multimodal moral scenarios by systematically perturbing reasoning chains and manipulating delivery tones. Specifically, we analyze reasoning errors in vision language models (VLMs) and how they impact user trust and the ability to detect errors. Our findings reveal two key effects: (1) users often equate trust with outcome agreement, sustaining reliance even when reasoning is flawed, and (2) the confident tone suppresses error detection while maintaining reliance, showing that delivery styles can override correctness. These results highlight how CoT explanations can simultaneously clarify and mislead, underscoring the need for NLP systems to provide explanations that encourage scrutiny and critical thinking rather than blind trust. All code will be released publicly.
Gaussian Blending: Rethinking Alpha Blending in 3D Gaussian Splatting
Nov 19, 2025


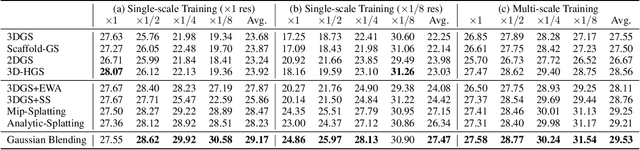
The recent introduction of 3D Gaussian Splatting (3DGS) has significantly advanced novel view synthesis. Several studies have further improved the rendering quality of 3DGS, yet they still exhibit noticeable visual discrepancies when synthesizing views at sampling rates unseen during training. Specifically, they suffer from (i) erosion-induced blurring artifacts when zooming in and (ii) dilation-induced staircase artifacts when zooming out. We speculate that these artifacts arise from the fundamental limitation of the alpha blending adopted in 3DGS methods. Instead of the conventional alpha blending that computes alpha and transmittance as scalar quantities over a pixel, we propose to replace it with our novel Gaussian Blending that treats alpha and transmittance as spatially varying distributions. Thus, transmittances can be updated considering the spatial distribution of alpha values across the pixel area, allowing nearby background splats to contribute to the final rendering. Our Gaussian Blending maintains real-time rendering speed and requires no additional memory cost, while being easily integrated as a drop-in replacement into existing 3DGS-based or other NVS frameworks. Extensive experiments demonstrate that Gaussian Blending effectively captures fine details at various sampling rates unseen during training, consistently outperforming existing novel view synthesis models across both unseen and seen sampling rates.
MAVIS: A Benchmark for Multimodal Source Attribution in Long-form Visual Question Answering
Nov 15, 2025Source attribution aims to enhance the reliability of AI-generated answers by including references for each statement, helping users validate the provided answers. However, existing work has primarily focused on text-only scenario and largely overlooked the role of multimodality. We introduce MAVIS, the first benchmark designed to evaluate multimodal source attribution systems that understand user intent behind visual questions, retrieve multimodal evidence, and generate long-form answers with citations. Our dataset comprises 157K visual QA instances, where each answer is annotated with fact-level citations referring to multimodal documents. We develop fine-grained automatic metrics along three dimensions of informativeness, groundedness, and fluency, and demonstrate their strong correlation with human judgments. Our key findings are threefold: (1) LVLMs with multimodal RAG generate more informative and fluent answers than unimodal RAG, but they exhibit weaker groundedness for image documents than for text documents, a gap amplified in multimodal settings. (2) Given the same multimodal documents, there is a trade-off between informativeness and groundedness across different prompting methods. (3) Our proposed method highlights mitigating contextual bias in interpreting image documents as a crucial direction for future research. The dataset and experimental code are available at https://github.com/seokwon99/MAVIS
Think, Verbalize, then Speak: Bridging Complex Thoughts and Comprehensible Speech
Sep 19, 2025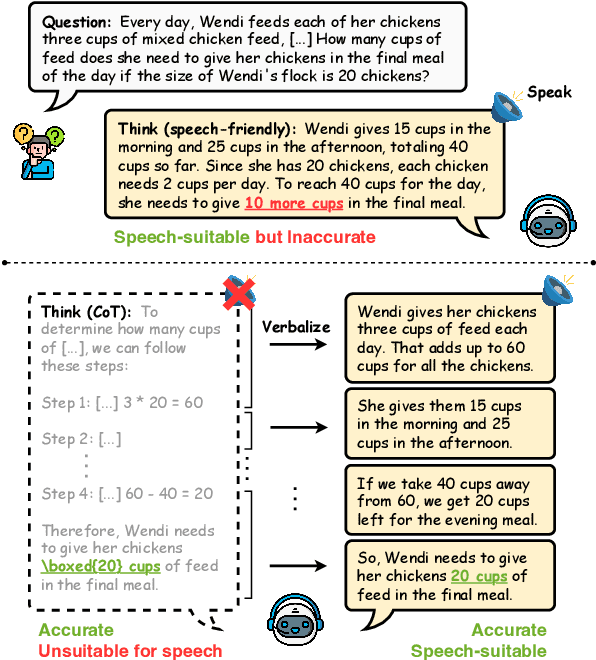

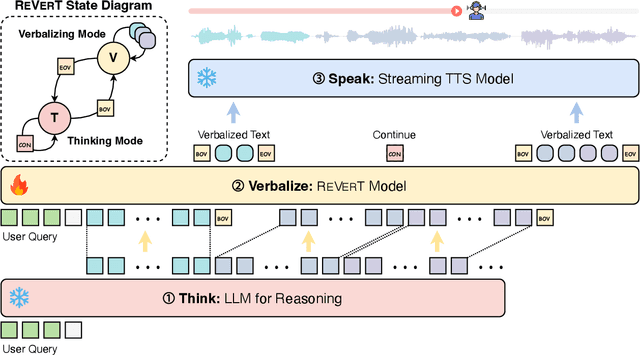
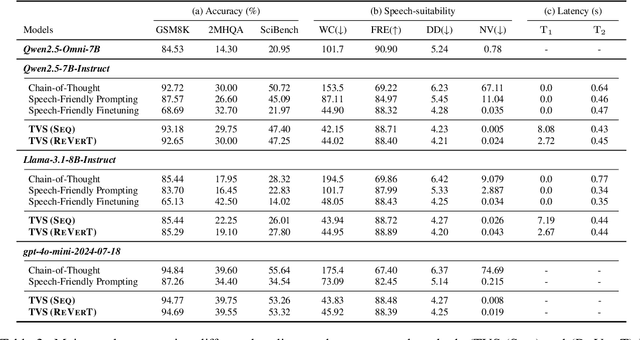
Spoken dialogue systems increasingly employ large language models (LLMs) to leverage their advanced reasoning capabilities. However, direct application of LLMs in spoken communication often yield suboptimal results due to mismatches between optimal textual and verbal delivery. While existing approaches adapt LLMs to produce speech-friendly outputs, their impact on reasoning performance remains underexplored. In this work, we propose Think-Verbalize-Speak, a framework that decouples reasoning from spoken delivery to preserve the full reasoning capacity of LLMs. Central to our method is verbalizing, an intermediate step that translates thoughts into natural, speech-ready text. We also introduce ReVerT, a latency-efficient verbalizer based on incremental and asynchronous summarization. Experiments across multiple benchmarks show that our method enhances speech naturalness and conciseness with minimal impact on reasoning. The project page with the dataset and the source code is available at https://yhytoto12.github.io/TVS-ReVerT
WoW-Bench: Evaluating Fine-Grained Acoustic Perception in Audio-Language Models via Marine Mammal Vocalizations
Aug 28, 2025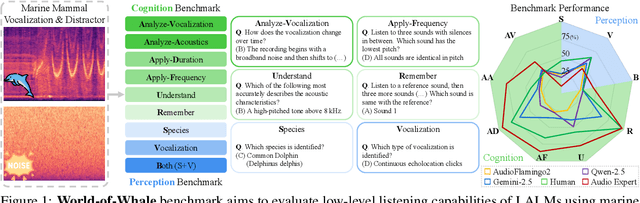

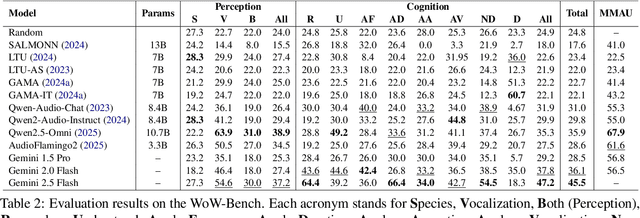
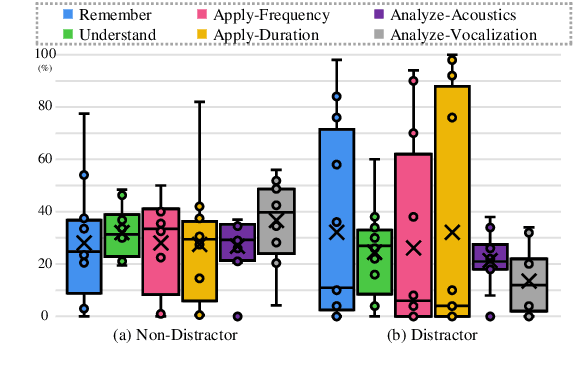
Large audio language models (LALMs) extend language understanding into the auditory domain, yet their ability to perform low-level listening, such as pitch and duration detection, remains underexplored. However, low-level listening is critical for real-world, out-of-distribution tasks where models must reason about unfamiliar sounds based on fine-grained acoustic cues. To address this gap, we introduce the World-of-Whale benchmark (WoW-Bench) to evaluate low-level auditory perception and cognition using marine mammal vocalizations. WoW-bench is composed of a Perception benchmark for categorizing novel sounds and a Cognition benchmark, inspired by Bloom's taxonomy, to assess the abilities to remember, understand, apply, and analyze sound events. For the Cognition benchmark, we additionally introduce distractor questions to evaluate whether models are truly solving problems through listening rather than relying on other heuristics. Experiments with state-of-the-art LALMs show performance far below human levels, indicating a need for stronger auditory grounding in LALMs.
Hybrid Deep Searcher: Integrating Parallel and Sequential Search Reasoning
Aug 26, 2025Large reasoning models (LRMs) have demonstrated strong performance in complex, multi-step reasoning tasks. Existing methods enhance LRMs by sequentially integrating external knowledge retrieval; models iteratively generate queries, retrieve external information, and progressively reason over this information. However, purely sequential querying increases inference latency and context length, diminishing coherence and potentially reducing accuracy. To address these limitations, we introduce HDS-QA (Hybrid Deep Search QA), a synthetic dataset automatically generated from Natural Questions, explicitly designed to train LRMs to distinguish parallelizable from sequential queries. HDS-QA comprises hybrid-hop questions that combine parallelizable independent subqueries (executable simultaneously) and sequentially dependent subqueries (requiring step-by-step resolution), along with synthetic reasoning-querying-retrieval paths involving parallel queries. We fine-tune an LRM using HDS-QA, naming the model HybridDeepSearcher, which outperforms state-of-the-art baselines across multiple benchmarks, notably achieving +15.9 and +11.5 F1 on FanOutQA and a subset of BrowseComp, respectively, both requiring comprehensive and exhaustive search. Experimental results highlight two key advantages: HybridDeepSearcher reaches comparable accuracy with fewer search turns, significantly reducing inference latency, and it effectively scales as more turns are permitted. These results demonstrate the efficiency, scalability, and effectiveness of explicitly training LRMs to leverage hybrid parallel and sequential querying.
FedMeNF: Privacy-Preserving Federated Meta-Learning for Neural Fields
Aug 08, 2025



Neural fields provide a memory-efficient representation of data, which can effectively handle diverse modalities and large-scale data. However, learning to map neural fields often requires large amounts of training data and computations, which can be limited to resource-constrained edge devices. One approach to tackle this limitation is to leverage Federated Meta-Learning (FML), but traditional FML approaches suffer from privacy leakage. To address these issues, we introduce a novel FML approach called FedMeNF. FedMeNF utilizes a new privacy-preserving loss function that regulates privacy leakage in the local meta-optimization. This enables the local meta-learner to optimize quickly and efficiently without retaining the client's private data. Our experiments demonstrate that FedMeNF achieves fast optimization speed and robust reconstruction performance, even with few-shot or non-IID data across diverse data modalities, while preserving client data privacy.
Cognitive Chain-of-Thought: Structured Multimodal Reasoning about Social Situations
Jul 27, 2025Chain-of-Thought (CoT) prompting helps models think step by step. But what happens when they must see, understand, and judge-all at once? In visual tasks grounded in social context, where bridging perception with norm-grounded judgments is essential, flat CoT often breaks down. We introduce Cognitive Chain-of-Thought (CoCoT), a prompting strategy that scaffolds VLM reasoning through three cognitively inspired stages: perception, situation, and norm. Our experiments show that, across multiple multimodal benchmarks (including intent disambiguation, commonsense reasoning, and safety), CoCoT consistently outperforms CoT and direct prompting (+8\% on average). Our findings demonstrate that cognitively grounded reasoning stages enhance interpretability and social awareness in VLMs, paving the way for safer and more reliable multimodal systems.
ViSAGe: Video-to-Spatial Audio Generation
Jun 13, 2025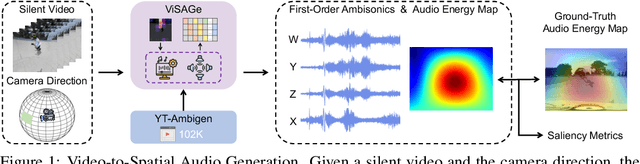
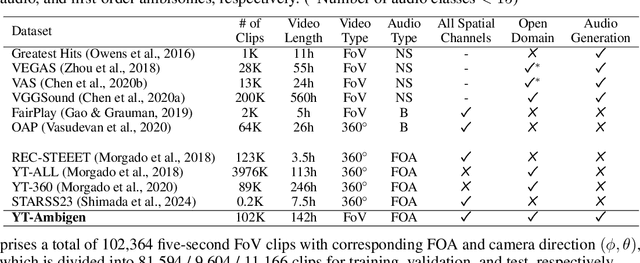
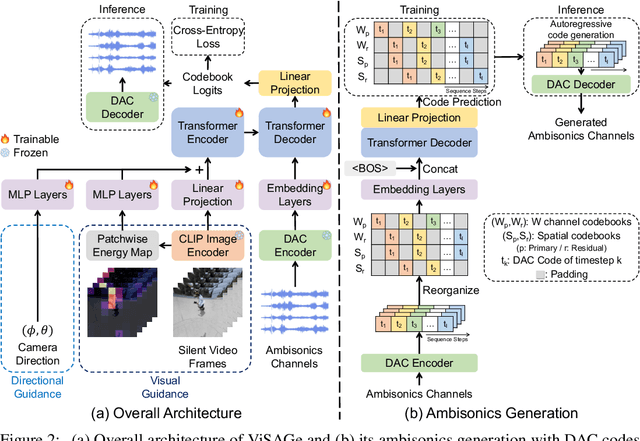
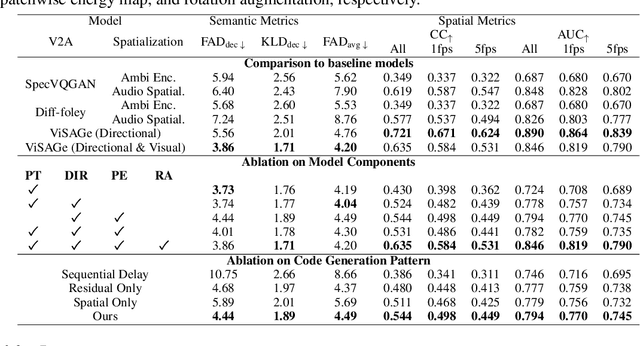
Spatial audio is essential for enhancing the immersiveness of audio-visual experiences, yet its production typically demands complex recording systems and specialized expertise. In this work, we address a novel problem of generating first-order ambisonics, a widely used spatial audio format, directly from silent videos. To support this task, we introduce YT-Ambigen, a dataset comprising 102K 5-second YouTube video clips paired with corresponding first-order ambisonics. We also propose new evaluation metrics to assess the spatial aspect of generated audio based on audio energy maps and saliency metrics. Furthermore, we present Video-to-Spatial Audio Generation (ViSAGe), an end-to-end framework that generates first-order ambisonics from silent video frames by leveraging CLIP visual features, autoregressive neural audio codec modeling with both directional and visual guidance. Experimental results demonstrate that ViSAGe produces plausible and coherent first-order ambisonics, outperforming two-stage approaches consisting of video-to-audio generation and audio spatialization. Qualitative examples further illustrate that ViSAGe generates temporally aligned high-quality spatial audio that adapts to viewpoint changes.