 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Move Your Dragon: Text-to-Motion Synthesis for Large-Vocabulary Objects
Mar 06, 2025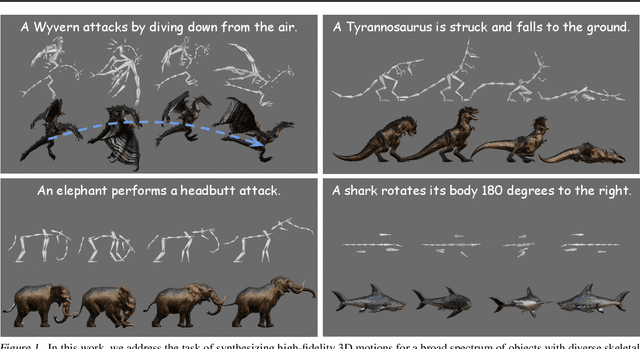

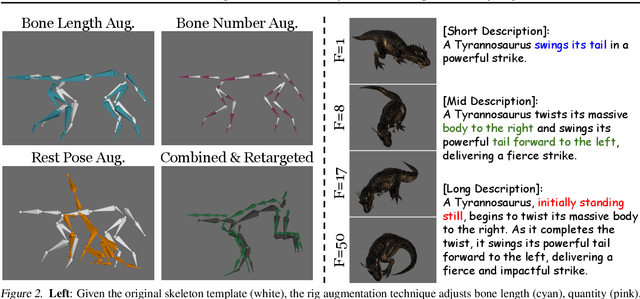
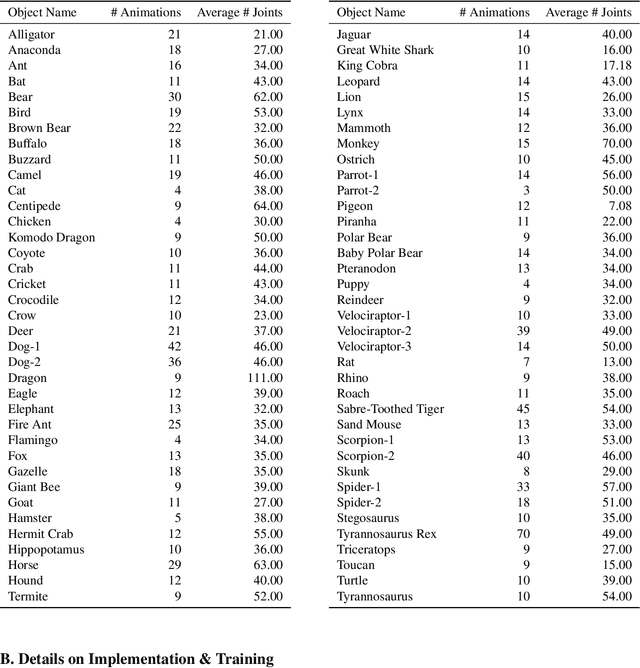
Motion synthesis for diverse object categories holds great potential for 3D content creation but remains underexplored due to two key challenges: (1) the lack of comprehensive motion datasets that include a wide range of high-quality motions and annotations, and (2) the absence of methods capable of handling heterogeneous skeletal templates from diverse objects. To address these challenges, we contribute the following: First, we augment the Truebones Zoo dataset, a high-quality animal motion dataset covering over 70 species, by annotating it with detailed text descriptions, making it suitable for text-based motion synthesis. Second, we introduce rig augmentation techniques that generate diverse motion data while preserving consistent dynamics, enabling models to adapt to various skeletal configurations. Finally, we redesign existing motion diffusion models to dynamically adapt to arbitrary skeletal templates, enabling motion synthesis for a diverse range of objects with varying structures. Experiments show that our method learns to generate high-fidelity motions from textual descriptions for diverse and even unseen objects, setting a strong foundation for motion synthesis across diverse object categories and skeletal templates. Qualitative results are available on this link: t2m4lvo.github.io
Multi-Task Processes
Oct 29, 2021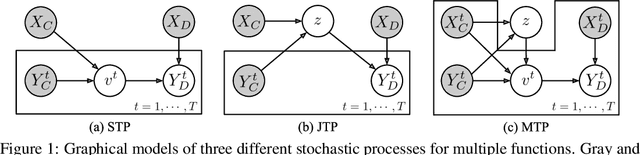
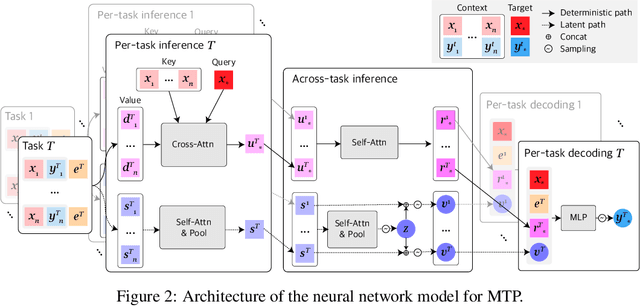
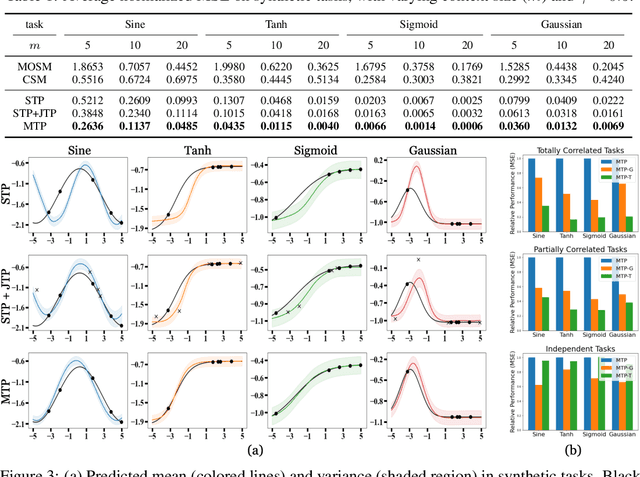
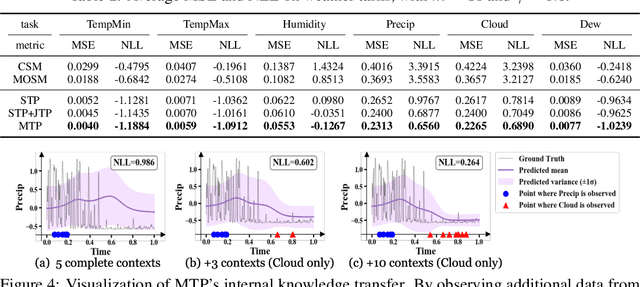
Neural Processes (NPs) consider a task as a function realized from a stochastic process and flexibly adapt to unseen tasks through inference on functions. However, naive NPs can model data from only a single stochastic process and are designed to infer each task independently. Since many real-world data represent a set of correlated tasks from multiple sources (e.g., multiple attributes and multi-sensor data), it is beneficial to infer them jointly and exploit the underlying correlation to improve the predictive performance. To this end, we propose Multi-Task Processes (MTPs), an extension of NPs designed to jointly infer tasks realized from multiple stochastic processes. We build our MTPs in a hierarchical manner such that inter-task correlation is considered by conditioning all per-task latent variables on a single global latent variable. In addition, we further design our MTPs so that they can address multi-task settings with incomplete data (i.e., not all tasks share the same set of input points), which has high practical demands in various applications. Experiments demonstrate that MTPs can successfully model multiple tasks jointly by discovering and exploiting their correlations in various real-world data such as time series of weather attributes and pixel-aligned visual modalities.
Revisiting Hierarchical Approach for Persistent Long-Term Video Prediction
Apr 14, 2021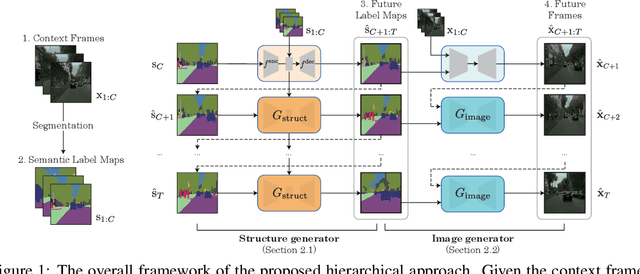
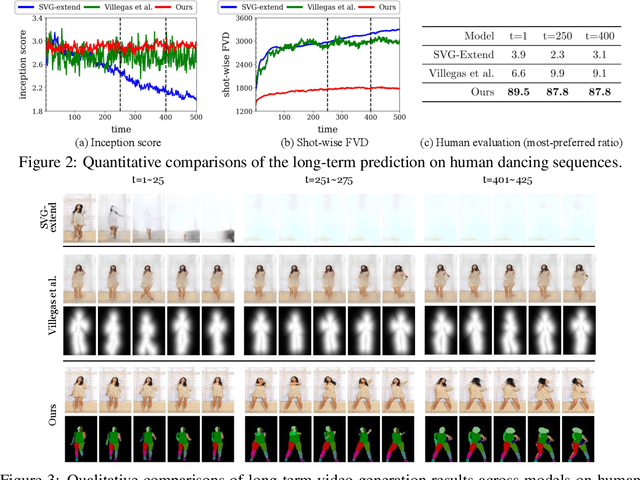
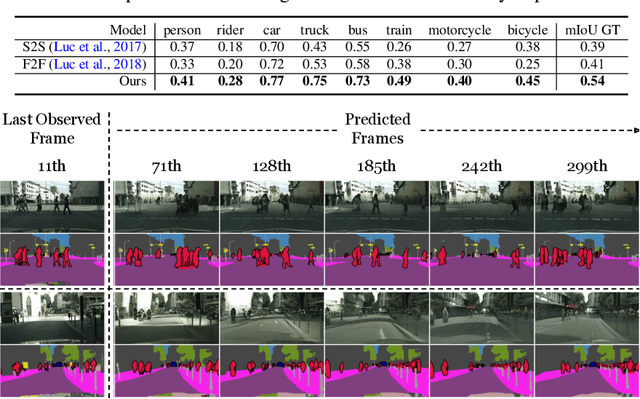
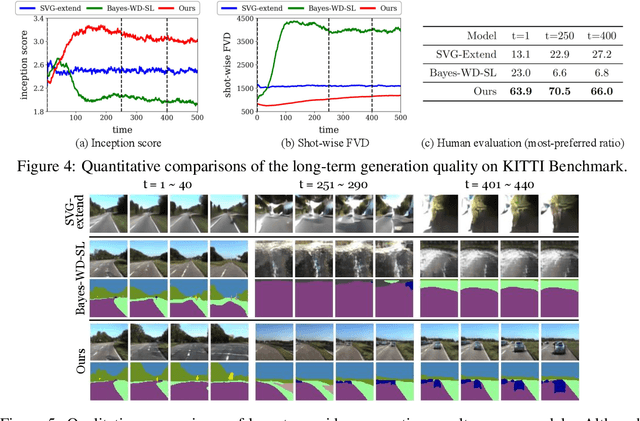
Learning to predict the long-term future of video frames is notoriously challenging due to inherent ambiguities in the distant future and dramatic amplifications of prediction error through time. Despite the recent advances in the literature, existing approaches are limited to moderately short-term prediction (less than a few seconds), while extrapolating it to a longer future quickly leads to destruction in structure and content. In this work, we revisit hierarchical models in video prediction. Our method predicts future frames by first estimating a sequence of semantic structures and subsequently translating the structures to pixels by video-to-video translation. Despite the simplicity, we show that modeling structures and their dynamics in the discrete semantic structure space with a stochastic recurrent estimator leads to surprisingly successful long-term prediction. We evaluate our method on three challenging datasets involving car driving and human dancing, and demonstrate that it can generate complicated scene structures and motions over a very long time horizon (i.e., thousands frames), setting a new standard of video prediction with orders of magnitude longer prediction time than existing approaches. Full videos and codes are available at https://1konny.github.io/HVP/.
High-Fidelity Synthesis with Disentangled Representation
Jan 13, 2020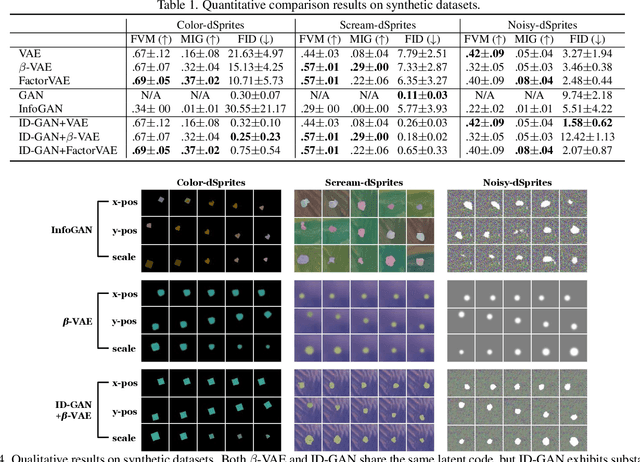
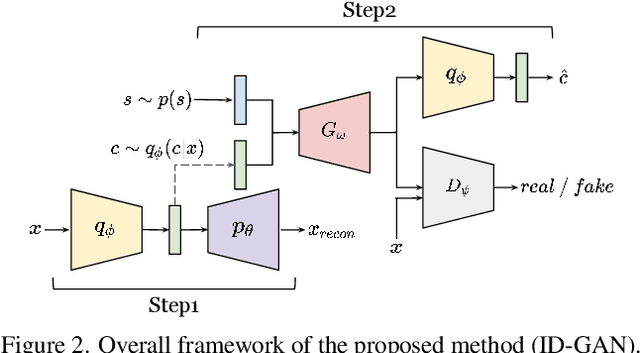
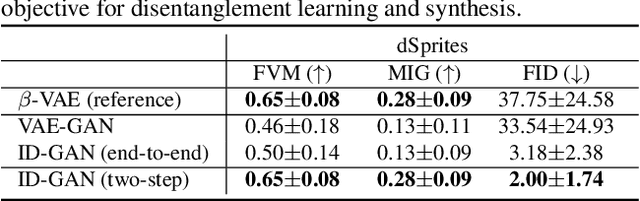
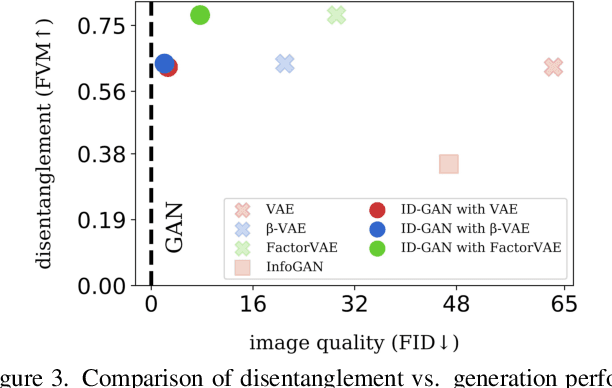
Learning disentangled representation of data without supervision is an important step towards improving the interpretability of generative models. Despite recent advances in disentangled representation learning, existing approaches often suffer from the trade-off between representation learning and generation performance i.e. improving generation quality sacrifices disentanglement performance). We propose an Information-Distillation Generative Adversarial Network (ID-GAN), a simple yet generic framework that easily incorporates the existing state-of-the-art models for both disentanglement learning and high-fidelity synthesis. Our method learns disentangled representation using VAE-based models, and distills the learned representation with an additional nuisance variable to the separate GAN-based generator for high-fidelity synthesis. To ensure that both generative models are aligned to render the same generative factors, we further constrain the GAN generator to maximize the mutual information between the learned latent code and the output. Despite the simplicity, we show that the proposed method is highly effective, achieving comparable image generation quality to the state-of-the-art methods using the disentangled representation. We also show that the proposed decomposition leads to an efficient and stable model design, and we demonstrate photo-realistic high-resolution image synthesis results (1024x1024 pixels) for the first time using the disentangled representations.