 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Move Your Dragon: Text-to-Motion Synthesis for Large-Vocabulary Objects
Mar 06, 2025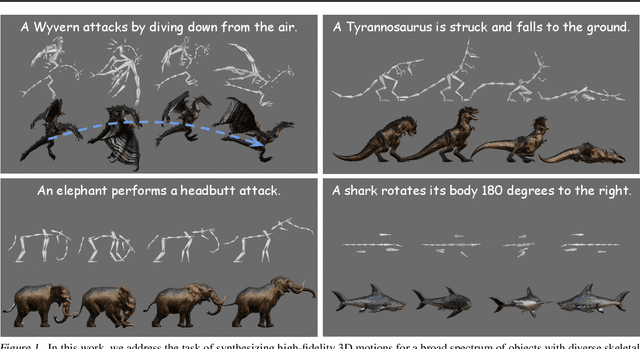

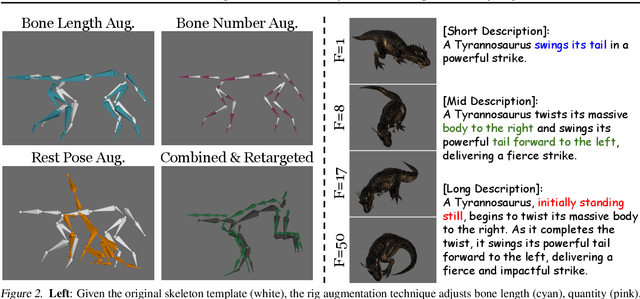
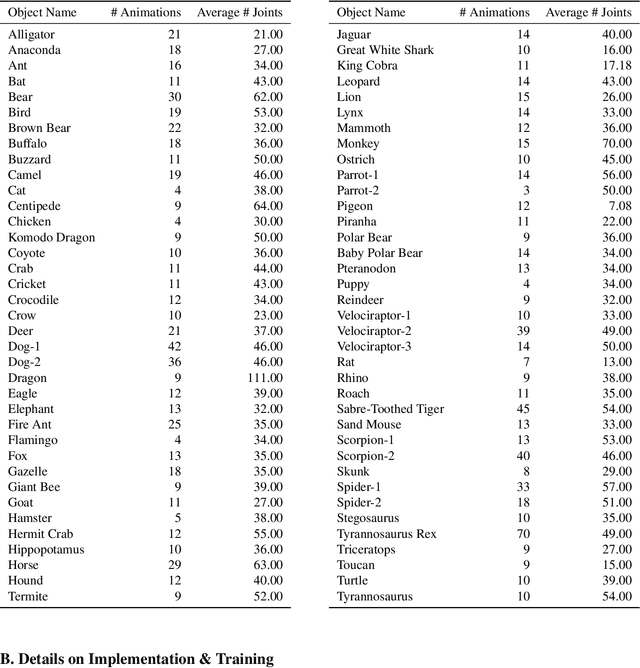
Motion synthesis for diverse object categories holds great potential for 3D content creation but remains underexplored due to two key challenges: (1) the lack of comprehensive motion datasets that include a wide range of high-quality motions and annotations, and (2) the absence of methods capable of handling heterogeneous skeletal templates from diverse objects. To address these challenges, we contribute the following: First, we augment the Truebones Zoo dataset, a high-quality animal motion dataset covering over 70 species, by annotating it with detailed text descriptions, making it suitable for text-based motion synthesis. Second, we introduce rig augmentation techniques that generate diverse motion data while preserving consistent dynamics, enabling models to adapt to various skeletal configurations. Finally, we redesign existing motion diffusion models to dynamically adapt to arbitrary skeletal templates, enabling motion synthesis for a diverse range of objects with varying structures. Experiments show that our method learns to generate high-fidelity motions from textual descriptions for diverse and even unseen objects, setting a strong foundation for motion synthesis across diverse object categories and skeletal templates. Qualitative results are available on this link: t2m4lvo.github.io
Learning to Control Camera Exposure via Reinforcement Learning
Apr 02, 2024



Adjusting camera exposure in arbitrary lighting conditions is the first step to ensure the functionality of computer vision applications. Poorly adjusted camera exposure often leads to critical failure and performance degradation. Traditional camera exposure control methods require multiple convergence steps and time-consuming processes, making them unsuitable for dynamic lighting conditions. In this paper, we propose a new camera exposure control framework that rapidly controls camera exposure while performing real-time processing by exploiting deep reinforcement learning. The proposed framework consists of four contributions: 1) a simplified training ground to simulate real-world's diverse and dynamic lighting changes, 2) flickering and image attribute-aware reward design, along with lightweight state design for real-time processing, 3) a static-to-dynamic lighting curriculum to gradually improve the agent's exposure-adjusting capability, and 4) domain randomization techniques to alleviate the limitation of the training ground and achieve seamless generalization in the wild.As a result, our proposed method rapidly reaches a desired exposure level within five steps with real-time processing (1 ms). Also, the acquired images are well-exposed and show superiority in various computer vision tasks, such as feature extraction and object detection.
Stable Surface Regularization for Fast Few-Shot NeRF
Mar 29, 2024This paper proposes an algorithm for synthesizing novel views under few-shot setup. The main concept is to develop a stable surface regularization technique called Annealing Signed Distance Function (ASDF), which anneals the surface in a coarse-to-fine manner to accelerate convergence speed. We observe that the Eikonal loss - which is a widely known geometric regularization - requires dense training signal to shape different level-sets of SDF, leading to low-fidelity results under few-shot training. In contrast, the proposed surface regularization successfully reconstructs scenes and produce high-fidelity geometry with stable training. Our method is further accelerated by utilizing grid representation and monocular geometric priors. Finally, the proposed approach is up to 45 times faster than existing few-shot novel view synthesis methods, and it produces comparable results in the ScanNet dataset and NeRF-Real dataset.
TTA-COPE: Test-Time Adaptation for Category-Level Object Pose Estimation
Mar 29, 2023
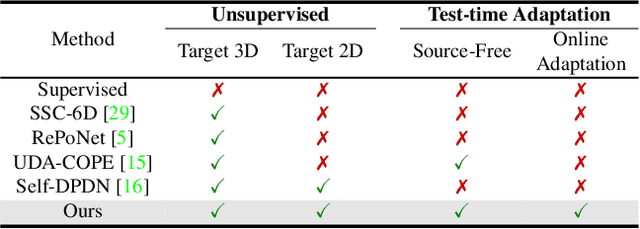
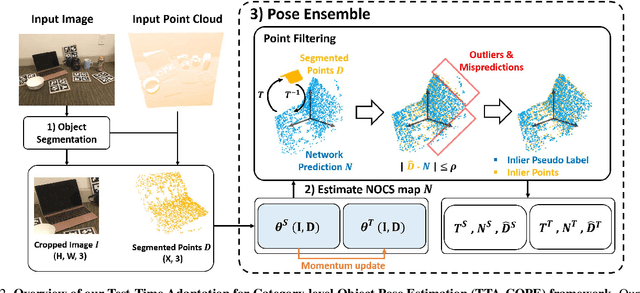
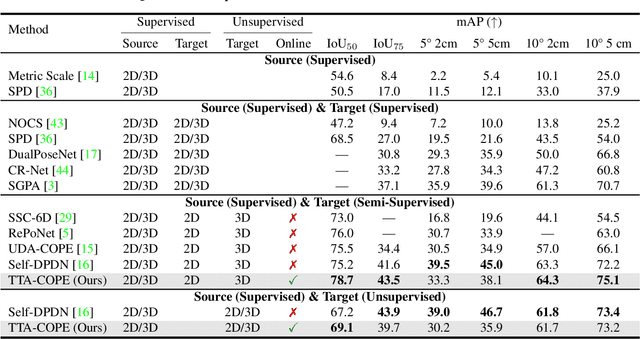
Test-time adaptation methods have been gaining attention recently as a practical solution for addressing source-to-target domain gaps by gradually updating the model without requiring labels on the target data. In this paper, we propose a method of test-time adaptation for category-level object pose estimation called TTA-COPE. We design a pose ensemble approach with a self-training loss using pose-aware confidence. Unlike previous unsupervised domain adaptation methods for category-level object pose estimation, our approach processes the test data in a sequential, online manner, and it does not require access to the source domain at runtime. Extensive experimental results demonstrate that the proposed pose ensemble and the self-training loss improve category-level object pose performance during test time under both semi-supervised and unsupervised settings. Project page: https://taeyeop.com/ttacope
Maximizing Self-supervision from Thermal Image for Effective Self-supervised Learning of Depth and Ego-motion
Jan 12, 2022


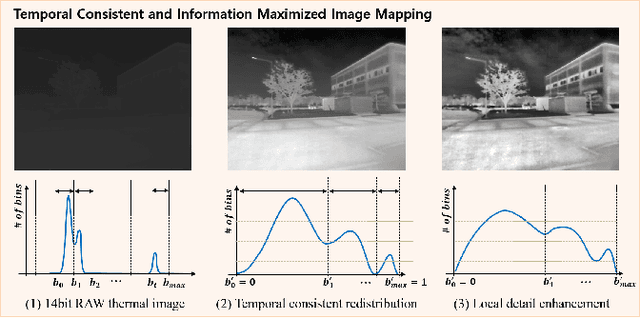
Recently, self-supervised learning of depth and ego-motion from thermal images shows strong robustness and reliability under challenging scenarios. However, the inherent thermal image properties such as weak contrast, blurry edges, and noise hinder to generate effective self-supervision from thermal images. Therefore, most research relies on additional self-supervision sources such as well-lit RGB images, generative models, and Lidar information. In this paper, we conduct an in-depth analysis of thermal image characteristics that degenerates self-supervision from thermal images. Based on the analysis, we propose an effective thermal image mapping method that significantly increases image information, such as overall structure, contrast, and details, while preserving temporal consistency. The proposed method shows outperformed depth and pose results than previous state-of-the-art networks without leveraging additional RGB guidance.
UDA-COPE: Unsupervised Domain Adaptation for Category-level Object Pose Estimation
Nov 24, 2021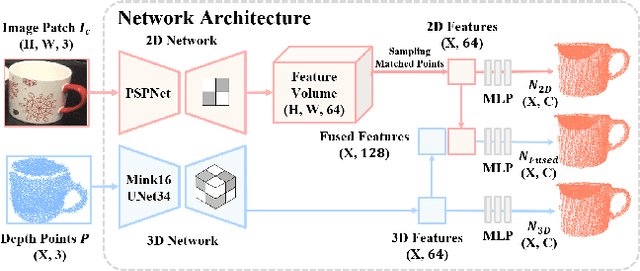
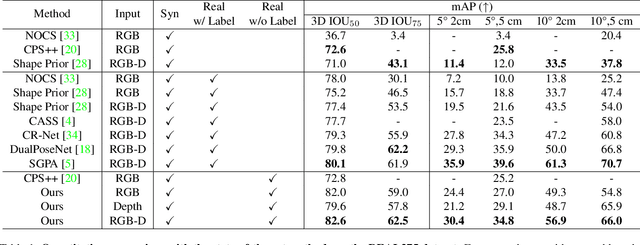
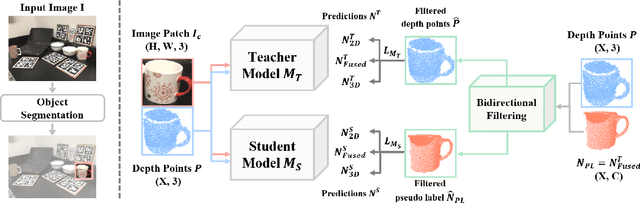

Learning to estimate object pose often requires ground-truth (GT) labels, such as CAD model and absolute-scale object pose, which is expensive and laborious to obtain in the real world. To tackle this problem, we propose an unsupervised domain adaptation (UDA) for category-level object pose estimation, called \textbf{UDA-COPE}. Inspired by the recent multi-modal UDA techniques, the proposed method exploits a teacher-student self-supervised learning scheme to train a pose estimation network without using target domain labels. We also introduce a bidirectional filtering method between predicted normalized object coordinate space (NOCS) map and observed point cloud, to not only make our teacher network more robust to the target domain but also to provide more reliable pseudo labels for the student network training. Extensive experimental results demonstrate the effectiveness of our proposed method both quantitatively and qualitatively. Notably, without leveraging target-domain GT labels, our proposed method achieves comparable or sometimes superior performance to existing methods that depend on the GT labels.
Category-Level Metric Scale Object Shape and Pose Estimation
Sep 01, 2021
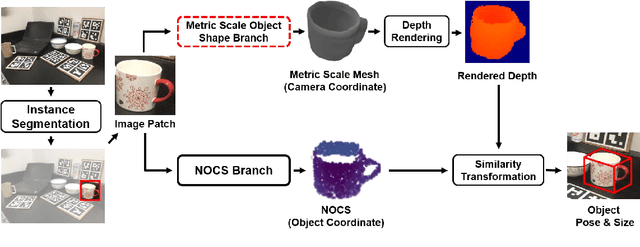
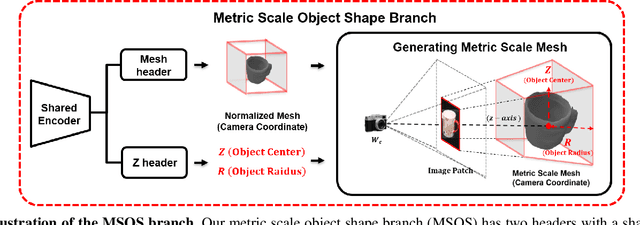
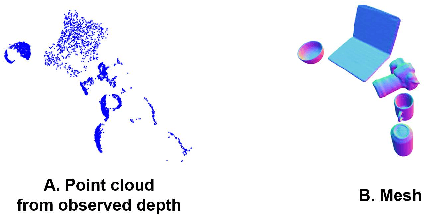
Advances in deep learning recognition have led to accurate object detection with 2D images. However, these 2D perception methods are insufficient for complete 3D world information. Concurrently, advanced 3D shape estimation approaches focus on the shape itself, without considering metric scale. These methods cannot determine the accurate location and orientation of objects. To tackle this problem, we propose a framework that jointly estimates a metric scale shape and pose from a single RGB image. Our framework has two branches: the Metric Scale Object Shape branch (MSOS) and the Normalized Object Coordinate Space branch (NOCS). The MSOS branch estimates the metric scale shape observed in the camera coordinates. The NOCS branch predicts the normalized object coordinate space (NOCS) map and performs similarity transformation with the rendered depth map from a predicted metric scale mesh to obtain 6d pose and size. Additionally, we introduce the Normalized Object Center Estimation (NOCE) to estimate the geometrically aligned distance from the camera to the object center. We validated our method on both synthetic and real-world datasets to evaluate category-level object pose and shape.
Depth Completion using Plane-Residual Representation
Apr 15, 2021

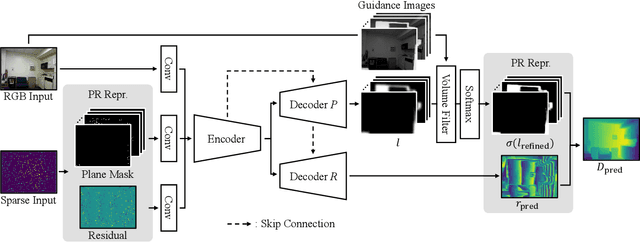

The basic framework of depth completion is to predict a pixel-wise dense depth map using very sparse input data. In this paper, we try to solve this problem in a more effective way, by reformulating the regression-based depth estimation problem into a combination of depth plane classification and residual regression. Our proposed approach is to initially densify sparse depth information by figuring out which plane a pixel should lie among a number of discretized depth planes, and then calculate the final depth value by predicting the distance from the specified plane. This will help the network to lessen the burden of directly regressing the absolute depth information from none, and to effectively obtain more accurate depth prediction result with less computation power and inference time. To do so, we firstly introduce a novel way of interpreting depth information with the closest depth plane label $p$ and a residual value $r$, as we call it, Plane-Residual (PR) representation. We also propose a depth completion network utilizing PR representation consisting of a shared encoder and two decoders, where one classifies the pixel's depth plane label, while the other one regresses the normalized distance from the classified depth plane. By interpreting depth information in PR representation and using our corresponding depth completion network, we were able to acquire improved depth completion performance with faster computation, compared to previous approaches.
An Efficient Asynchronous Method for Integrating Evolutionary and Gradient-based Policy Search
Jan 06, 2021

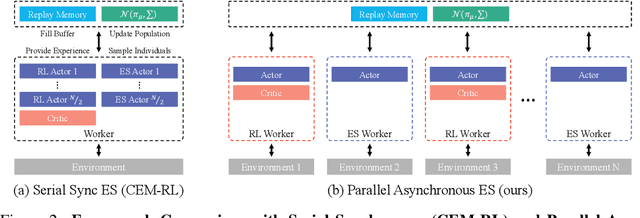

Deep reinforcement learning (DRL) algorithms and evolution strategies (ES) have been applied to various tasks, showing excellent performances. These have the opposite properties, with DRL having good sample efficiency and poor stability, while ES being vice versa. Recently, there have been attempts to combine these algorithms, but these methods fully rely on synchronous update scheme, making it not ideal to maximize the benefits of the parallelism in ES. To solve this challenge, asynchronous update scheme was introduced, which is capable of good time-efficiency and diverse policy exploration. In this paper, we introduce an Asynchronous Evolution Strategy-Reinforcement Learning (AES-RL) that maximizes the parallel efficiency of ES and integrates it with policy gradient methods. Specifically, we propose 1) a novel framework to merge ES and DRL asynchronously and 2) various asynchronous update methods that can take all advantages of asynchronism, ES, and DRL, which are exploration and time efficiency, stability, and sample efficiency, respectively. The proposed framework and update methods are evaluated in continuous control benchmark work, showing superior performance as well as time efficiency compared to the previous methods.