 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUDA-COPE: Unsupervised Domain Adaptation for Category-level Object Pose Estimation
Paper and Code
Nov 24, 2021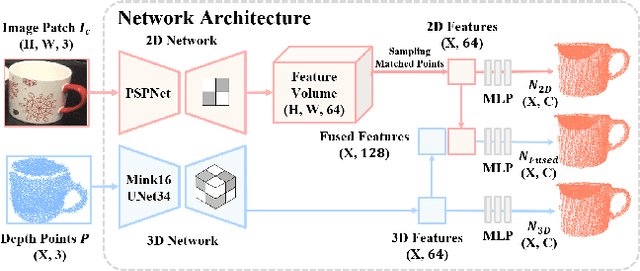
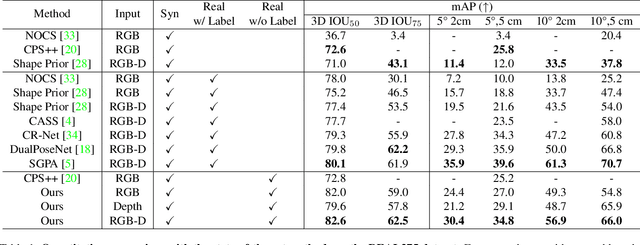
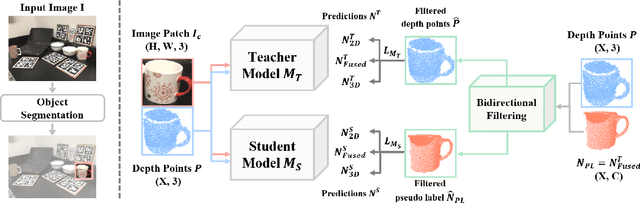

Learning to estimate object pose often requires ground-truth (GT) labels, such as CAD model and absolute-scale object pose, which is expensive and laborious to obtain in the real world. To tackle this problem, we propose an unsupervised domain adaptation (UDA) for category-level object pose estimation, called \textbf{UDA-COPE}. Inspired by the recent multi-modal UDA techniques, the proposed method exploits a teacher-student self-supervised learning scheme to train a pose estimation network without using target domain labels. We also introduce a bidirectional filtering method between predicted normalized object coordinate space (NOCS) map and observed point cloud, to not only make our teacher network more robust to the target domain but also to provide more reliable pseudo labels for the student network training. Extensive experimental results demonstrate the effectiveness of our proposed method both quantitatively and qualitatively. Notably, without leveraging target-domain GT labels, our proposed method achieves comparable or sometimes superior performance to existing methods that depend on the GT labels.