 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARGOS: Who, Where, and When in Agentic Multi-Camera Person Search
Apr 14, 2026We introduce ARGOS, the first benchmark and framework that reformulates multi-camera person search as an interactive reasoning problem requiring an agent to plan, question, and eliminate candidates under information asymmetry. An ARGOS agent receives a vague witness statement and must decide what to ask, when to invoke spatial or temporal tools, and how to interpret ambiguous responses, all within a limited turn budget. Reasoning is grounded in a Spatio-Temporal Topology Graph (STTG) encoding camera connectivity and empirically validated transition times. The benchmark comprises 2,691 tasks across 14 real-world scenarios in three progressive tracks: semantic perception (Who), spatial reasoning (Where), and temporal reasoning (When). Experiments with four LLM backbones show the benchmark is far from solved (best TWS: 0.383 on Track 2, 0.590 on Track 3), and ablations confirm that removing domain-specific tools drops accuracy by up to 49.6 percentage points.
GeoNVS: Geometry Grounded Video Diffusion for Novel View Synthesis
Mar 16, 2026Novel view synthesis requires strong 3D geometric consistency and the ability to generate visually coherent images across diverse viewpoints. While recent camera-controlled video diffusion models show promising results, they often suffer from geometric distortions and limited camera controllability. To overcome these challenges, we introduce GeoNVS, a geometry-grounded novel-view synthesizer that enhances both geometric fidelity and camera controllability through explicit 3D geometric guidance. Our key innovation is the Gaussian Splat Feature Adapter (GS-Adapter), which lifts input-view diffusion features into 3D Gaussian representations, renders geometry-constrained novel-view features, and adaptively fuses them with diffusion features to correct geometrically inconsistent representations. Unlike prior methods that inject geometry at the input level, GS-Adapter operates in feature space, avoiding view-dependent color noise that degrades structural consistency. Its plug-and-play design enables zero-shot compatibility with diverse feed-forward geometry models without additional training, and can be adapted to other video diffusion backbones. Experiments across 9 scenes and 18 settings demonstrate state-of-the-art performance, achieving 11.3% and 14.9% improvements over SEVA and CameraCtrl, with up to 2x reduction in translation error and 7x in Chamfer Distance.
MTMMC: A Large-Scale Real-World Multi-Modal Camera Tracking Benchmark
Mar 29, 2024Multi-target multi-camera tracking is a crucial task that involves identifying and tracking individuals over time using video streams from multiple cameras. This task has practical applications in various fields, such as visual surveillance, crowd behavior analysis, and anomaly detection. However, due to the difficulty and cost of collecting and labeling data, existing datasets for this task are either synthetically generated or artificially constructed within a controlled camera network setting, which limits their ability to model real-world dynamics and generalize to diverse camera configurations. To address this issue, we present MTMMC, a real-world, large-scale dataset that includes long video sequences captured by 16 multi-modal cameras in two different environments - campus and factory - across various time, weather, and season conditions. This dataset provides a challenging test-bed for studying multi-camera tracking under diverse real-world complexities and includes an additional input modality of spatially aligned and temporally synchronized RGB and thermal cameras, which enhances the accuracy of multi-camera tracking. MTMMC is a super-set of existing datasets, benefiting independent fields such as person detection, re-identification, and multiple object tracking. We provide baselines and new learning setups on this dataset and set the reference scores for future studies. The datasets, models, and test server will be made publicly available.
Self-Sufficient Framework for Continuous Sign Language Recognition
Mar 21, 2023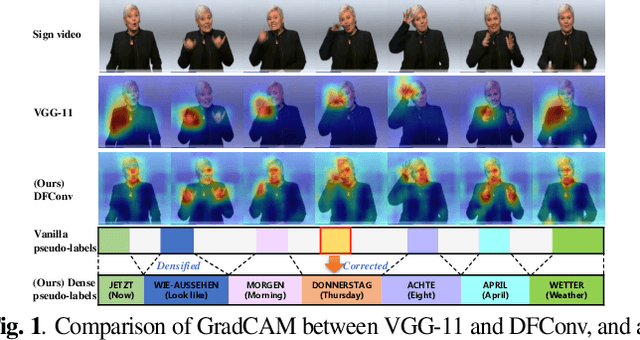
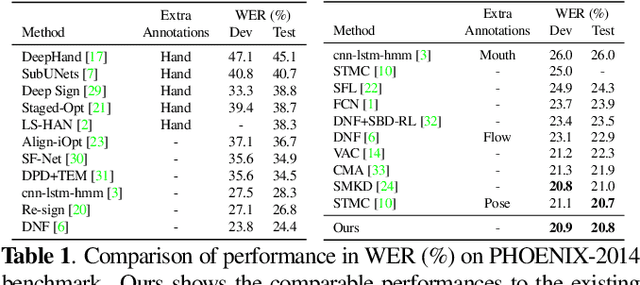
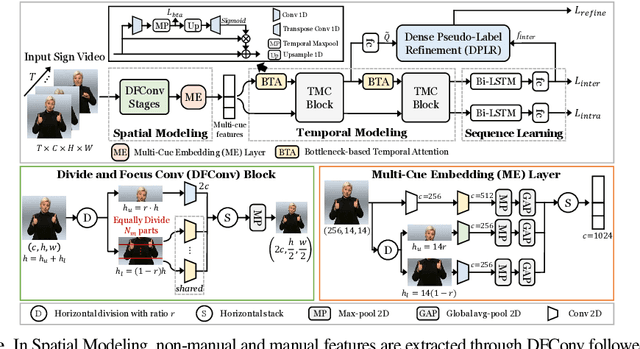

The goal of this work is to develop self-sufficient framework for Continuous Sign Language Recognition (CSLR) that addresses key issues of sign language recognition. These include the need for complex multi-scale features such as hands, face, and mouth for understanding, and absence of frame-level annotations. To this end, we propose (1) Divide and Focus Convolution (DFConv) which extracts both manual and non-manual features without the need for additional networks or annotations, and (2) Dense Pseudo-Label Refinement (DPLR) which propagates non-spiky frame-level pseudo-labels by combining the ground truth gloss sequence labels with the predicted sequence. We demonstrate that our model achieves state-of-the-art performance among RGB-based methods on large-scale CSLR benchmarks, PHOENIX-2014 and PHOENIX-2014-T, while showing comparable results with better efficiency when compared to other approaches that use multi-modality or extra annotations.
Category-Level Metric Scale Object Shape and Pose Estimation
Sep 01, 2021
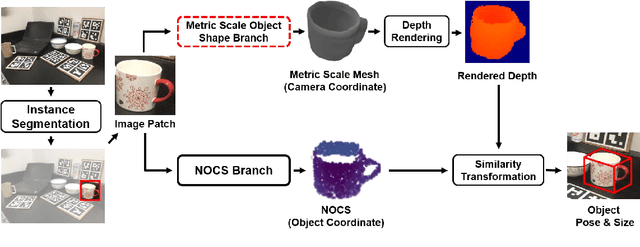
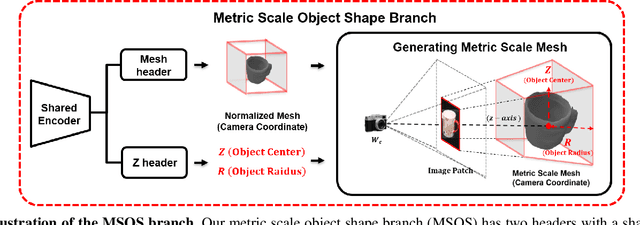
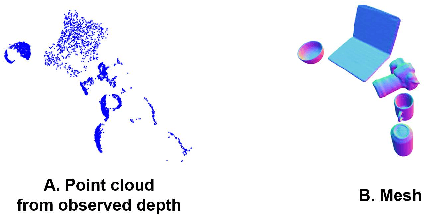
Advances in deep learning recognition have led to accurate object detection with 2D images. However, these 2D perception methods are insufficient for complete 3D world information. Concurrently, advanced 3D shape estimation approaches focus on the shape itself, without considering metric scale. These methods cannot determine the accurate location and orientation of objects. To tackle this problem, we propose a framework that jointly estimates a metric scale shape and pose from a single RGB image. Our framework has two branches: the Metric Scale Object Shape branch (MSOS) and the Normalized Object Coordinate Space branch (NOCS). The MSOS branch estimates the metric scale shape observed in the camera coordinates. The NOCS branch predicts the normalized object coordinate space (NOCS) map and performs similarity transformation with the rendered depth map from a predicted metric scale mesh to obtain 6d pose and size. Additionally, we introduce the Normalized Object Center Estimation (NOCE) to estimate the geometrically aligned distance from the camera to the object center. We validated our method on both synthetic and real-world datasets to evaluate category-level object pose and shape.
NeuSaver: Neural Adaptive Power Consumption Optimization for Mobile Video Streaming
Jul 15, 2021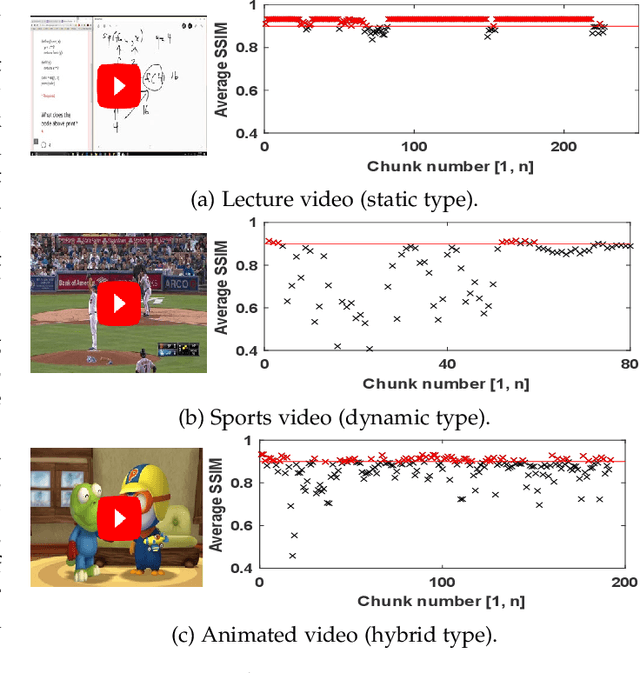

Video streaming services strive to support high-quality videos at higher resolutions and frame rates to improve the quality of experience (QoE). However, high-quality videos consume considerable amounts of energy on mobile devices. This paper proposes NeuSaver, which reduces the power consumption of mobile devices when streaming videos by applying an adaptive frame rate to each video chunk without compromising user experience. NeuSaver generates an optimal policy that determines the appropriate frame rate for each video chunk using reinforcement learning (RL). The RL model automatically learns the policy that maximizes the QoE goals based on previous observations. NeuSaver also uses an asynchronous advantage actor-critic algorithm to reinforce the RL model quickly and robustly. Streaming servers that support NeuSaver preprocesses videos into segments with various frame rates, which is similar to the process of creating videos with multiple bit rates in dynamic adaptive streaming over HTTP. NeuSaver utilizes the commonly used H.264 video codec. We evaluated NeuSaver in various experiments and a user study through four video categories along with the state-of-the-art model. Our experiments showed that NeuSaver effectively reduces the power consumption of mobile devices when streaming video by an average of 16.14% and up to 23.12% while achieving high QoE.
The Devil is in the Boundary: Exploiting Boundary Representation for Basis-based Instance Segmentation
Nov 26, 2020
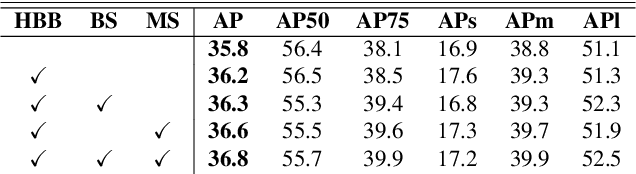
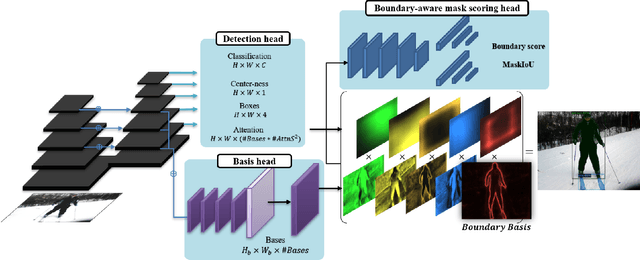
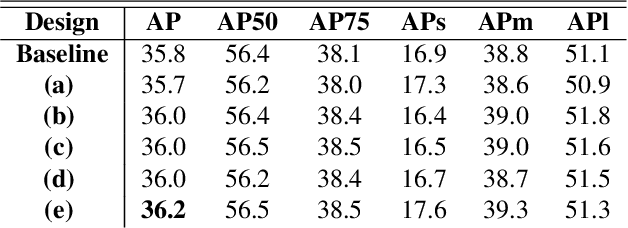
Pursuing a more coherent scene understanding towards real-time vision applications, single-stage instance segmentation has recently gained popularity, achieving a simpler and more efficient design than its two-stage counterparts. Besides, its global mask representation often leads to superior accuracy to the two-stage Mask R-CNN which has been dominant thus far. Despite the promising advances in single-stage methods, finer delineation of instance boundaries still remains unexcavated. Indeed, boundary information provides a strong shape representation that can operate in synergy with the fully-convolutional mask features of the single-stage segmenter. In this work, we propose Boundary Basis based Instance Segmentation(B2Inst) to learn a global boundary representation that can complement existing global-mask-based methods that are often lacking high-frequency details. Besides, we devise a unified quality measure of both mask and boundary and introduce a network block that learns to score the per-instance predictions of itself. When applied to the strongest baselines in single-stage instance segmentation, our B2Inst leads to consistent improvements and accurately parse out the instance boundaries in a scene. Regardless of being single-stage or two-stage frameworks, we outperform the existing state-of-the-art methods on the COCO dataset with the same ResNet-50 and ResNet-101 backbones.