 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreserving Multi-Modal Capabilities of Pre-trained VLMs for Improving Vision-Linguistic Compositionality
Oct 07, 2024



In this paper, we propose a new method to enhance compositional understanding in pre-trained vision and language models (VLMs) without sacrificing performance in zero-shot multi-modal tasks. Traditional fine-tuning approaches often improve compositional reasoning at the cost of degrading multi-modal capabilities, primarily due to the use of global hard negative (HN) loss, which contrasts global representations of images and texts. This global HN loss pushes HN texts that are highly similar to the original ones, damaging the model's multi-modal representations. To overcome this limitation, we propose Fine-grained Selective Calibrated CLIP (FSC-CLIP), which integrates local hard negative loss and selective calibrated regularization. These innovations provide fine-grained negative supervision while preserving the model's representational integrity. Our extensive evaluations across diverse benchmarks for both compositionality and multi-modal tasks show that FSC-CLIP not only achieves compositionality on par with state-of-the-art models but also retains strong multi-modal capabilities. Code is available at: https://github.com/ytaek-oh/fsc-clip.
Exploring the Spectrum of Visio-Linguistic Compositionality and Recognition
Jun 13, 2024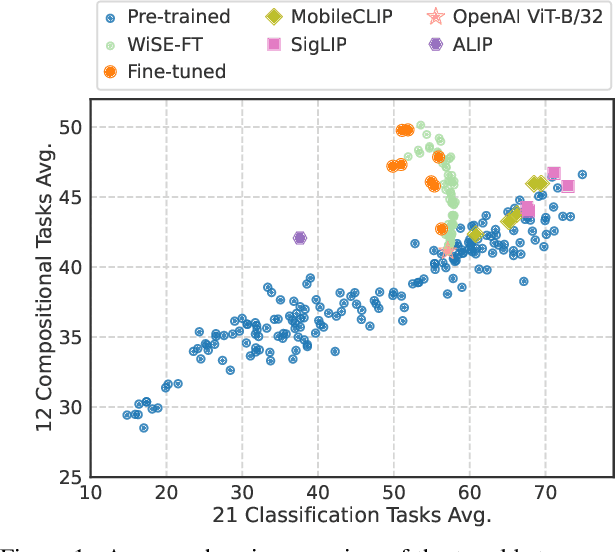
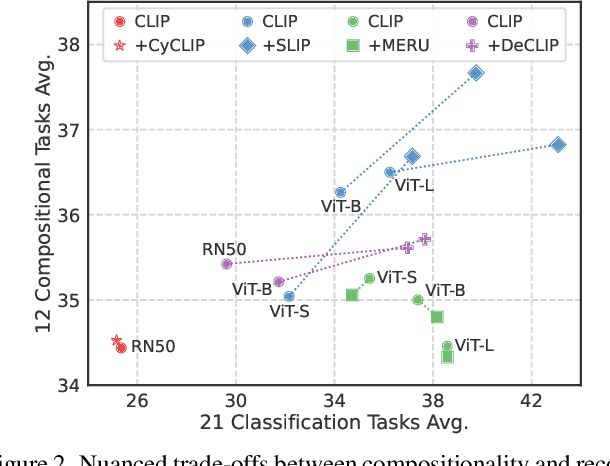
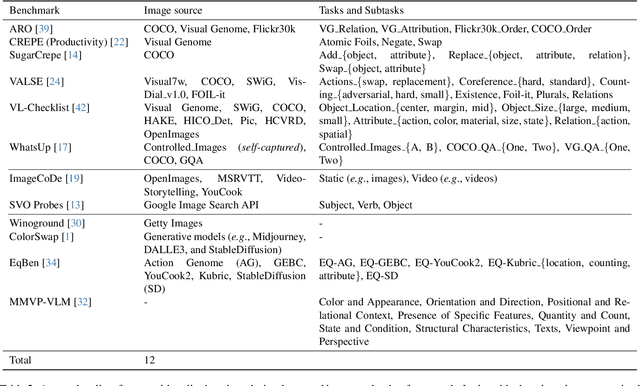
Vision and language models (VLMs) such as CLIP have showcased remarkable zero-shot recognition abilities yet face challenges in visio-linguistic compositionality, particularly in linguistic comprehension and fine-grained image-text alignment. This paper explores the intricate relationship between compositionality and recognition -- two pivotal aspects of VLM capability. We conduct a comprehensive evaluation of existing VLMs, covering both pre-training approaches aimed at recognition and the fine-tuning methods designed to improve compositionality. Our evaluation employs 12 benchmarks for compositionality, along with 21 zero-shot classification and two retrieval benchmarks for recognition. In our analysis from 274 CLIP model checkpoints, we reveal patterns and trade-offs that emerge between compositional understanding and recognition accuracy. Ultimately, this necessitates strategic efforts towards developing models that improve both capabilities, as well as the meticulous formulation of benchmarks for compositionality. We open our evaluation framework at https://github.com/ytaek-oh/vl_compo.
NICE: CVPR 2023 Challenge on Zero-shot Image Captioning
Sep 11, 2023



In this report, we introduce NICE (New frontiers for zero-shot Image Captioning Evaluation) project and share the results and outcomes of 2023 challenge. This project is designed to challenge the computer vision community to develop robust image captioning models that advance the state-of-the-art both in terms of accuracy and fairness. Through the challenge, the image captioning models were tested using a new evaluation dataset that includes a large variety of visual concepts from many domains. There was no specific training data provided for the challenge, and therefore the challenge entries were required to adapt to new types of image descriptions that had not been seen during training. This report includes information on the newly proposed NICE dataset, evaluation methods, challenge results, and technical details of top-ranking entries. We expect that the outcomes of the challenge will contribute to the improvement of AI models on various vision-language tasks.
Self-Sufficient Framework for Continuous Sign Language Recognition
Mar 21, 2023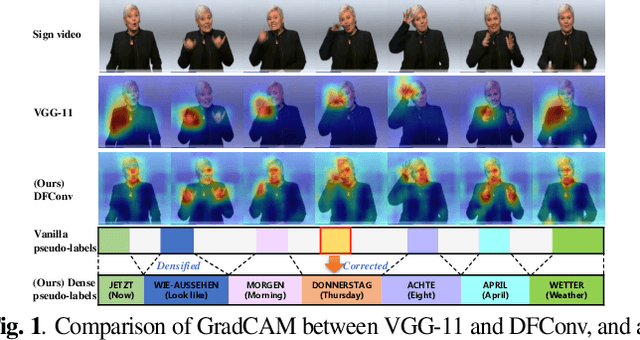
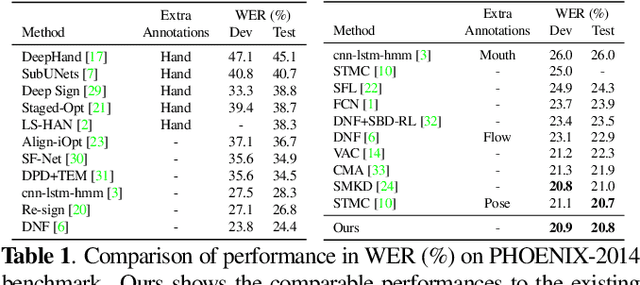
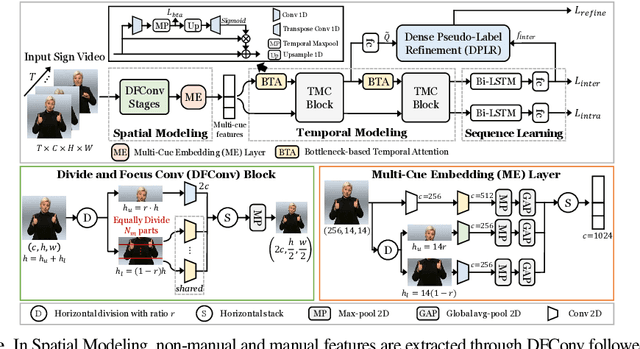

The goal of this work is to develop self-sufficient framework for Continuous Sign Language Recognition (CSLR) that addresses key issues of sign language recognition. These include the need for complex multi-scale features such as hands, face, and mouth for understanding, and absence of frame-level annotations. To this end, we propose (1) Divide and Focus Convolution (DFConv) which extracts both manual and non-manual features without the need for additional networks or annotations, and (2) Dense Pseudo-Label Refinement (DPLR) which propagates non-spiky frame-level pseudo-labels by combining the ground truth gloss sequence labels with the predicted sequence. We demonstrate that our model achieves state-of-the-art performance among RGB-based methods on large-scale CSLR benchmarks, PHOENIX-2014 and PHOENIX-2014-T, while showing comparable results with better efficiency when compared to other approaches that use multi-modality or extra annotations.
Signing Outside the Studio: Benchmarking Background Robustness for Continuous Sign Language Recognition
Nov 01, 2022



The goal of this work is background-robust continuous sign language recognition. Most existing Continuous Sign Language Recognition (CSLR) benchmarks have fixed backgrounds and are filmed in studios with a static monochromatic background. However, signing is not limited only to studios in the real world. In order to analyze the robustness of CSLR models under background shifts, we first evaluate existing state-of-the-art CSLR models on diverse backgrounds. To synthesize the sign videos with a variety of backgrounds, we propose a pipeline to automatically generate a benchmark dataset utilizing existing CSLR benchmarks. Our newly constructed benchmark dataset consists of diverse scenes to simulate a real-world environment. We observe even the most recent CSLR method cannot recognize glosses well on our new dataset with changed backgrounds. In this regard, we also propose a simple yet effective training scheme including (1) background randomization and (2) feature disentanglement for CSLR models. The experimental results on our dataset demonstrate that our method generalizes well to other unseen background data with minimal additional training images.
Distribution-Aware Semantics-Oriented Pseudo-label for Imbalanced Semi-Supervised Learning
Jun 10, 2021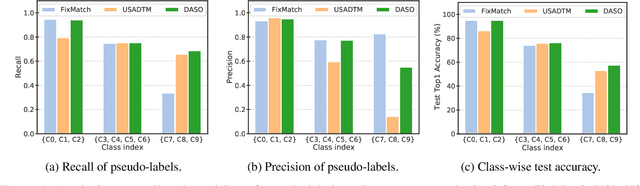
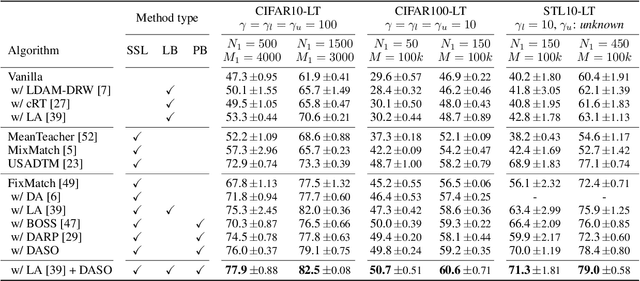


The capability of the traditional semi-supervised learning (SSL) methods is far from real-world application since they do not consider (1) class imbalance and (2) class distribution mismatch between labeled and unlabeled data. This paper addresses such a relatively under-explored problem, imbalanced semi-supervised learning, where heavily biased pseudo-labels can harm the model performance. Interestingly, we find that the semantic pseudo-labels from a similarity-based classifier in feature space and the traditional pseudo-labels from the linear classifier show the complementary property. To this end, we propose a general pseudo-labeling framework to address the bias motivated by this observation. The key idea is to class-adaptively blend the semantic pseudo-label to the linear one, depending on the current pseudo-label distribution. Thereby, the increased semantic pseudo-label component suppresses the false positives in the majority classes and vice versa. We term the novel pseudo-labeling framework for imbalanced SSL as Distribution-Aware Semantics-Oriented (DASO) Pseudo-label. Extensive evaluation on CIFAR10/100-LT and STL10-LT shows that DASO consistently outperforms both recently proposed re-balancing methods for label and pseudo-label. Moreover, we demonstrate that typical SSL algorithms can effectively benefit from unlabeled data with DASO, especially when (1) class imbalance and (2) class distribution mismatch exist and even on recent real-world Semi-Aves benchmark.