 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCARI4D: Category Agnostic 4D Reconstruction of Human-Object Interaction
Dec 12, 2025Accurate capture of human-object interaction from ubiquitous sensors like RGB cameras is important for applications in human understanding, gaming, and robot learning. However, inferring 4D interactions from a single RGB view is highly challenging due to the unknown object and human information, depth ambiguity, occlusion, and complex motion, which hinder consistent 3D and temporal reconstruction. Previous methods simplify the setup by assuming ground truth object template or constraining to a limited set of object categories. We present CARI4D, the first category-agnostic method that reconstructs spatially and temporarily consistent 4D human-object interaction at metric scale from monocular RGB videos. To this end, we propose a pose hypothesis selection algorithm that robustly integrates the individual predictions from foundation models, jointly refine them through a learned render-and-compare paradigm to ensure spatial, temporal and pixel alignment, and finally reasoning about intricate contacts for further refinement satisfying physical constraints. Experiments show that our method outperforms prior art by 38% on in-distribution dataset and 36% on unseen dataset in terms of reconstruction error. Our model generalizes beyond the training categories and thus can be applied zero-shot to in-the-wild internet videos. Our code and pretrained models will be publicly released.
Fast-FoundationStereo: Real-Time Zero-Shot Stereo Matching
Dec 11, 2025Stereo foundation models achieve strong zero-shot generalization but remain computationally prohibitive for real-time applications. Efficient stereo architectures, on the other hand, sacrifice robustness for speed and require costly per-domain fine-tuning. To bridge this gap, we present Fast-FoundationStereo, a family of architectures that achieve, for the first time, strong zero-shot generalization at real-time frame rate. We employ a divide-and-conquer acceleration strategy with three components: (1) knowledge distillation to compress the hybrid backbone into a single efficient student; (2) blockwise neural architecture search for automatically discovering optimal cost filtering designs under latency budgets, reducing search complexity exponentially; and (3) structured pruning for eliminating redundancy in the iterative refinement module. Furthermore, we introduce an automatic pseudo-labeling pipeline used to curate 1.4M in-the-wild stereo pairs to supplement synthetic training data and facilitate knowledge distillation. The resulting model can run over 10x faster than FoundationStereo while closely matching its zero-shot accuracy, thus establishing a new state-of-the-art among real-time methods. Project page: https://nvlabs.github.io/Fast-FoundationStereo/
RaySt3R: Predicting Novel Depth Maps for Zero-Shot Object Completion
Jun 05, 20253D shape completion has broad applications in robotics, digital twin reconstruction, and extended reality (XR). Although recent advances in 3D object and scene completion have achieved impressive results, existing methods lack 3D consistency, are computationally expensive, and struggle to capture sharp object boundaries. Our work (RaySt3R) addresses these limitations by recasting 3D shape completion as a novel view synthesis problem. Specifically, given a single RGB-D image and a novel viewpoint (encoded as a collection of query rays), we train a feedforward transformer to predict depth maps, object masks, and per-pixel confidence scores for those query rays. RaySt3R fuses these predictions across multiple query views to reconstruct complete 3D shapes. We evaluate RaySt3R on synthetic and real-world datasets, and observe it achieves state-of-the-art performance, outperforming the baselines on all datasets by up to 44% in 3D chamfer distance. Project page: https://rayst3r.github.io
Any6D: Model-free 6D Pose Estimation of Novel Objects
Mar 25, 2025We introduce Any6D, a model-free framework for 6D object pose estimation that requires only a single RGB-D anchor image to estimate both the 6D pose and size of unknown objects in novel scenes. Unlike existing methods that rely on textured 3D models or multiple viewpoints, Any6D leverages a joint object alignment process to enhance 2D-3D alignment and metric scale estimation for improved pose accuracy. Our approach integrates a render-and-compare strategy to generate and refine pose hypotheses, enabling robust performance in scenarios with occlusions, non-overlapping views, diverse lighting conditions, and large cross-environment variations. We evaluate our method on five challenging datasets: REAL275, Toyota-Light, HO3D, YCBINEOAT, and LM-O, demonstrating its effectiveness in significantly outperforming state-of-the-art methods for novel object pose estimation. Project page: https://taeyeop.com/any6d
L4P: Low-Level 4D Vision Perception Unified
Feb 18, 2025The spatio-temporal relationship between the pixels of a video carries critical information for low-level 4D perception. A single model that reasons about it should be able to solve several such tasks well. Yet, most state-of-the-art methods rely on architectures specialized for the task at hand. We present L4P (pronounced "LAP"), a feedforward, general-purpose architecture that solves low-level 4D perception tasks in a unified framework. L4P combines a ViT-based backbone with per-task heads that are lightweight and therefore do not require extensive training. Despite its general and feedforward formulation, our method matches or surpasses the performance of existing specialized methods on both dense tasks, such as depth or optical flow estimation, and sparse tasks, such as 2D/3D tracking. Moreover, it solves all those tasks at once in a time comparable to that of individual single-task methods.
SPOT: SE(3) Pose Trajectory Diffusion for Object-Centric Manipulation
Nov 01, 2024



We introduce SPOT, an object-centric imitation learning framework. The key idea is to capture each task by an object-centric representation, specifically the SE(3) object pose trajectory relative to the target. This approach decouples embodiment actions from sensory inputs, facilitating learning from various demonstration types, including both action-based and action-less human hand demonstrations, as well as cross-embodiment generalization. Additionally, object pose trajectories inherently capture planning constraints from demonstrations without the need for manually crafted rules. To guide the robot in executing the task, the object trajectory is used to condition a diffusion policy. We show improvement compared to prior work on RLBench simulated tasks. In real-world evaluation, using only eight demonstrations shot on an iPhone, our approach completed all tasks while fully complying with task constraints. Project page: https://nvlabs.github.io/object_centric_diffusion
SkillMimicGen: Automated Demonstration Generation for Efficient Skill Learning and Deployment
Oct 24, 2024



Imitation learning from human demonstrations is an effective paradigm for robot manipulation, but acquiring large datasets is costly and resource-intensive, especially for long-horizon tasks. To address this issue, we propose SkillMimicGen (SkillGen), an automated system for generating demonstration datasets from a few human demos. SkillGen segments human demos into manipulation skills, adapts these skills to new contexts, and stitches them together through free-space transit and transfer motion. We also propose a Hybrid Skill Policy (HSP) framework for learning skill initiation, control, and termination components from SkillGen datasets, enabling skills to be sequenced using motion planning at test-time. We demonstrate that SkillGen greatly improves data generation and policy learning performance over a state-of-the-art data generation framework, resulting in the capability to produce data for large scene variations, including clutter, and agents that are on average 24% more successful. We demonstrate the efficacy of SkillGen by generating over 24K demonstrations across 18 task variants in simulation from just 60 human demonstrations, and training proficient, often near-perfect, HSP agents. Finally, we apply SkillGen to 3 real-world manipulation tasks and also demonstrate zero-shot sim-to-real transfer on a long-horizon assembly task. Videos, and more at https://skillgen.github.io.
FORGE: Force-Guided Exploration for Robust Contact-Rich Manipulation under Uncertainty
Aug 08, 2024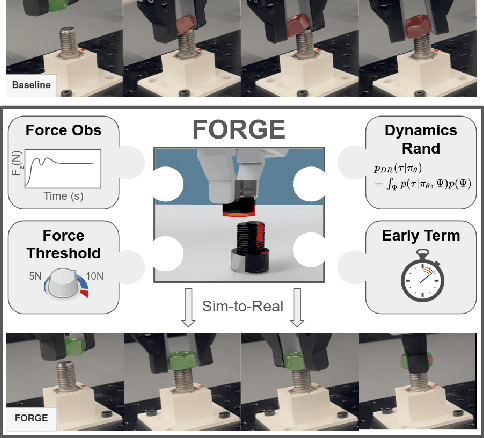

We present FORGE, a method that enables sim-to-real transfer of contact-rich manipulation policies in the presence of significant pose uncertainty. FORGE combines a force threshold mechanism with a dynamics randomization scheme during policy learning in simulation, to enable the robust transfer of the learned policies to the real robot. At deployment, FORGE policies, conditioned on a maximum allowable force, adaptively perform contact-rich tasks while respecting the specified force threshold, regardless of the controller gains. Additionally, FORGE autonomously predicts a termination action once the task has succeeded. We demonstrate that FORGE can be used to learn a variety of robust contact-rich policies, enabling multi-stage assembly of a planetary gear system, which requires success across three assembly tasks: nut-threading, insertion, and gear meshing. Project website can be accessed at https://noseworm.github.io/forge/.
AutoMate: Specialist and Generalist Assembly Policies over Diverse Geometries
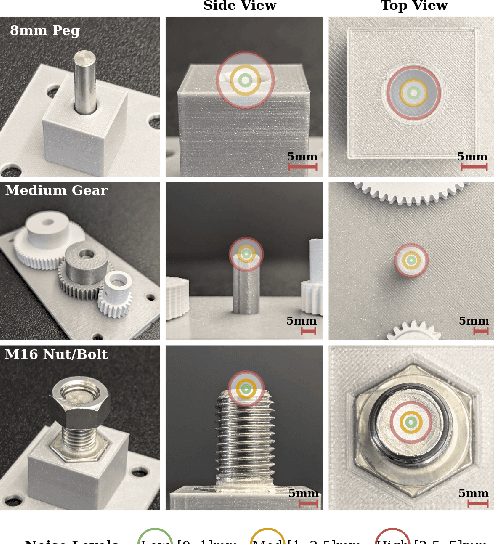
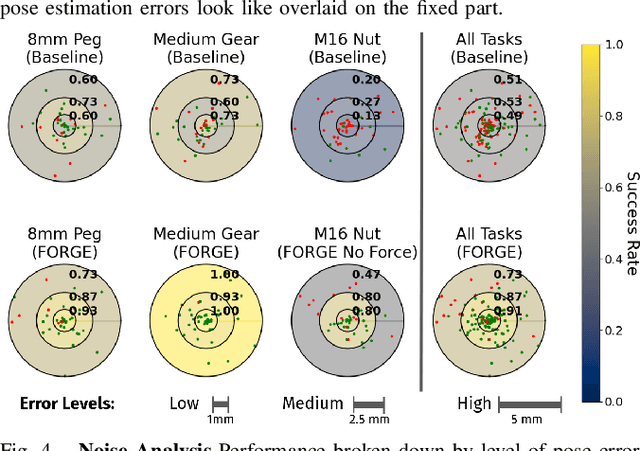
Jul 10, 2024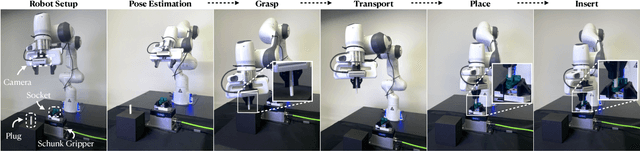

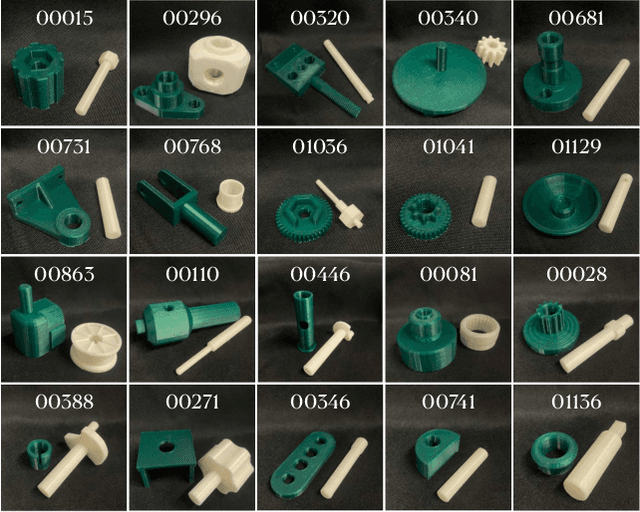

Robotic assembly for high-mixture settings requires adaptivity to diverse parts and poses, which is an open challenge. Meanwhile, in other areas of robotics, large models and sim-to-real have led to tremendous progress. Inspired by such work, we present AutoMate, a learning framework and system that consists of 4 parts: 1) a dataset of 100 assemblies compatible with simulation and the real world, along with parallelized simulation environments for policy learning, 2) a novel simulation-based approach for learning specialist (i.e., part-specific) policies and generalist (i.e., unified) assembly policies, 3) demonstrations of specialist policies that individually solve 80 assemblies with 80% or higher success rates in simulation, as well as a generalist policy that jointly solves 20 assemblies with an 80%+ success rate, and 4) zero-shot sim-to-real transfer that achieves similar (or better) performance than simulation, including on perception-initialized assembly. The key methodological takeaway is that a union of diverse algorithms from manufacturing engineering, character animation, and time-series analysis provides a generic and robust solution for a diverse range of robotic assembly problems.To our knowledge, AutoMate provides the first simulation-based framework for learning specialist and generalist policies over a wide range of assemblies, as well as the first system demonstrating zero-shot sim-to-real transfer over such a range.
NeRFDeformer: NeRF Transformation from a Single View via 3D Scene Flows
Jun 15, 2024We present a method for automatically modifying a NeRF representation based on a single observation of a non-rigid transformed version of the original scene. Our method defines the transformation as a 3D flow, specifically as a weighted linear blending of rigid transformations of 3D anchor points that are defined on the surface of the scene. In order to identify anchor points, we introduce a novel correspondence algorithm that first matches RGB-based pairs, then leverages multi-view information and 3D reprojection to robustly filter false positives in two steps. We also introduce a new dataset for exploring the problem of modifying a NeRF scene through a single observation. Our dataset ( https://github.com/nerfdeformer/nerfdeformer ) contains 113 synthetic scenes leveraging 47 3D assets. We show that our proposed method outperforms NeRF editing methods as well as diffusion-based methods, and we also explore different methods for filtering correspondences.