 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent6D: Event-based Novel Object 6D Pose Tracking
Mar 30, 2026Event cameras provide microsecond latency, making them suitable for 6D object pose tracking in fast, dynamic scenes where conventional RGB and depth pipelines suffer from motion blur and large pixel displacements. We introduce EventTrack6D, an event-depth tracking framework that generalizes to novel objects without object-specific training by reconstructing both intensity and depth at arbitrary timestamps between depth frames. Conditioned on the most recent depth measurement, our dual reconstruction recovers dense photometric and geometric cues from sparse event streams. Our EventTrack6D operates at over 120 FPS and maintains temporal consistency under rapid motion. To support training and evaluation, we introduce a comprehensive benchmark suite: a large-scale synthetic dataset for training and two complementary evaluation sets, including real and simulated event datasets. Trained exclusively on synthetic data, EventTrack6D generalizes effectively to real-world scenarios without fine-tuning, maintaining accurate tracking across diverse objects and motion patterns. Our method and datasets validate the effectiveness of event cameras for event-based 6D pose tracking of novel objects. Code and datasets are publicly available at https://chohoonhee.github.io/Event6D.
GeoNVS: Geometry Grounded Video Diffusion for Novel View Synthesis
Mar 16, 2026Novel view synthesis requires strong 3D geometric consistency and the ability to generate visually coherent images across diverse viewpoints. While recent camera-controlled video diffusion models show promising results, they often suffer from geometric distortions and limited camera controllability. To overcome these challenges, we introduce GeoNVS, a geometry-grounded novel-view synthesizer that enhances both geometric fidelity and camera controllability through explicit 3D geometric guidance. Our key innovation is the Gaussian Splat Feature Adapter (GS-Adapter), which lifts input-view diffusion features into 3D Gaussian representations, renders geometry-constrained novel-view features, and adaptively fuses them with diffusion features to correct geometrically inconsistent representations. Unlike prior methods that inject geometry at the input level, GS-Adapter operates in feature space, avoiding view-dependent color noise that degrades structural consistency. Its plug-and-play design enables zero-shot compatibility with diverse feed-forward geometry models without additional training, and can be adapted to other video diffusion backbones. Experiments across 9 scenes and 18 settings demonstrate state-of-the-art performance, achieving 11.3% and 14.9% improvements over SEVA and CameraCtrl, with up to 2x reduction in translation error and 7x in Chamfer Distance.
Any6D: Model-free 6D Pose Estimation of Novel Objects
Mar 25, 2025We introduce Any6D, a model-free framework for 6D object pose estimation that requires only a single RGB-D anchor image to estimate both the 6D pose and size of unknown objects in novel scenes. Unlike existing methods that rely on textured 3D models or multiple viewpoints, Any6D leverages a joint object alignment process to enhance 2D-3D alignment and metric scale estimation for improved pose accuracy. Our approach integrates a render-and-compare strategy to generate and refine pose hypotheses, enabling robust performance in scenarios with occlusions, non-overlapping views, diverse lighting conditions, and large cross-environment variations. We evaluate our method on five challenging datasets: REAL275, Toyota-Light, HO3D, YCBINEOAT, and LM-O, demonstrating its effectiveness in significantly outperforming state-of-the-art methods for novel object pose estimation. Project page: https://taeyeop.com/any6d
Stable Surface Regularization for Fast Few-Shot NeRF
Mar 29, 2024This paper proposes an algorithm for synthesizing novel views under few-shot setup. The main concept is to develop a stable surface regularization technique called Annealing Signed Distance Function (ASDF), which anneals the surface in a coarse-to-fine manner to accelerate convergence speed. We observe that the Eikonal loss - which is a widely known geometric regularization - requires dense training signal to shape different level-sets of SDF, leading to low-fidelity results under few-shot training. In contrast, the proposed surface regularization successfully reconstructs scenes and produce high-fidelity geometry with stable training. Our method is further accelerated by utilizing grid representation and monocular geometric priors. Finally, the proposed approach is up to 45 times faster than existing few-shot novel view synthesis methods, and it produces comparable results in the ScanNet dataset and NeRF-Real dataset.
Facial Depth and Normal Estimation using Single Dual-Pixel Camera
Nov 25, 2021
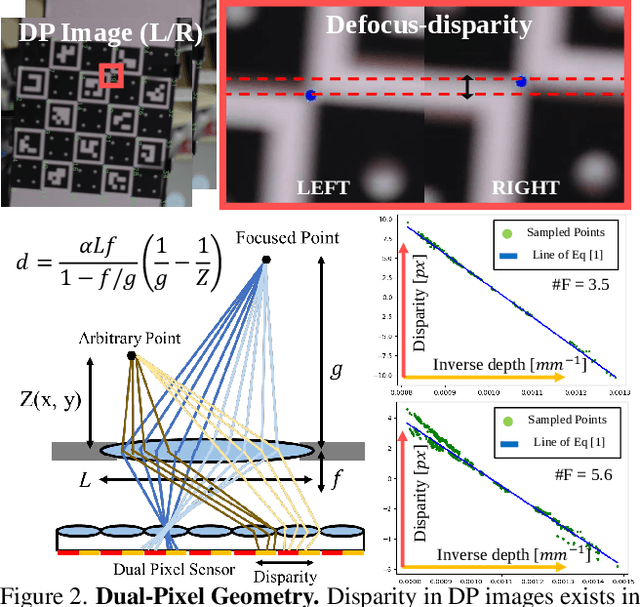

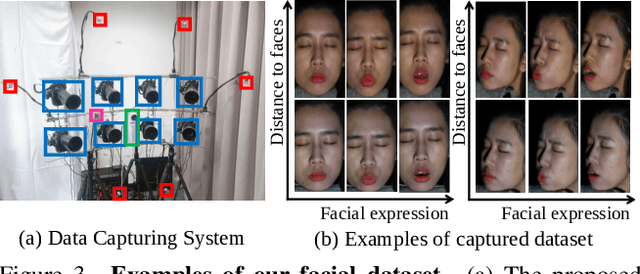
Many mobile manufacturers recently have adopted Dual-Pixel (DP) sensors in their flagship models for faster auto-focus and aesthetic image captures. Despite their advantages, research on their usage for 3D facial understanding has been limited due to the lack of datasets and algorithmic designs that exploit parallax in DP images. This is because the baseline of sub-aperture images is extremely narrow and parallax exists in the defocus blur region. In this paper, we introduce a DP-oriented Depth/Normal network that reconstructs the 3D facial geometry. For this purpose, we collect a DP facial data with more than 135K images for 101 persons captured with our multi-camera structured light systems. It contains the corresponding ground-truth 3D models including depth map and surface normal in metric scale. Our dataset allows the proposed matching network to be generalized for 3D facial depth/normal estimation. The proposed network consists of two novel modules: Adaptive Sampling Module and Adaptive Normal Module, which are specialized in handling the defocus blur in DP images. Finally, the proposed method achieves state-of-the-art performances over recent DP-based depth/normal estimation methods. We also demonstrate the applicability of the estimated depth/normal to face spoofing and relighting.
VolumeFusion: Deep Depth Fusion for 3D Scene Reconstruction
Aug 19, 2021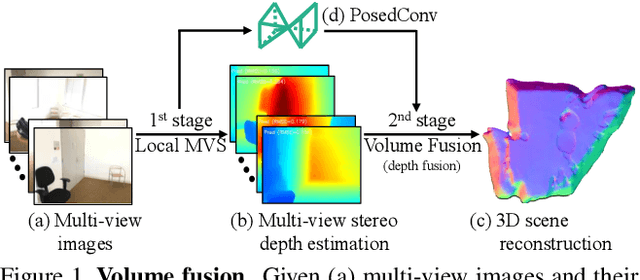
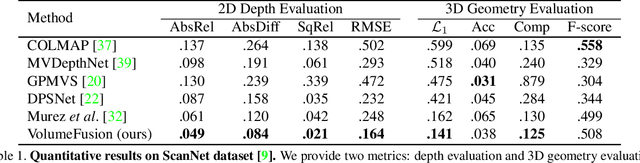
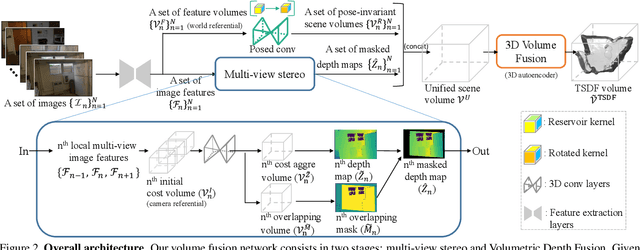

To reconstruct a 3D scene from a set of calibrated views, traditional multi-view stereo techniques rely on two distinct stages: local depth maps computation and global depth maps fusion. Recent studies concentrate on deep neural architectures for depth estimation by using conventional depth fusion method or direct 3D reconstruction network by regressing Truncated Signed Distance Function (TSDF). In this paper, we advocate that replicating the traditional two stages framework with deep neural networks improves both the interpretability and the accuracy of the results. As mentioned, our network operates in two steps: 1) the local computation of the local depth maps with a deep MVS technique, and, 2) the depth maps and images' features fusion to build a single TSDF volume. In order to improve the matching performance between images acquired from very different viewpoints (e.g., large-baseline and rotations), we introduce a rotation-invariant 3D convolution kernel called PosedConv. The effectiveness of the proposed architecture is underlined via a large series of experiments conducted on the ScanNet dataset where our approach compares favorably against both traditional and deep learning techniques.