 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLighthouseGS: Indoor Structure-aware 3D Gaussian Splatting for Panorama-Style Mobile Captures
Jul 08, 2025Recent advances in 3D Gaussian Splatting (3DGS) have enabled real-time novel view synthesis (NVS) with impressive quality in indoor scenes. However, achieving high-fidelity rendering requires meticulously captured images covering the entire scene, limiting accessibility for general users. We aim to develop a practical 3DGS-based NVS framework using simple panorama-style motion with a handheld camera (e.g., mobile device). While convenient, this rotation-dominant motion and narrow baseline make accurate camera pose and 3D point estimation challenging, especially in textureless indoor scenes. To address these challenges, we propose LighthouseGS, a novel framework inspired by the lighthouse-like sweeping motion of panoramic views. LighthouseGS leverages rough geometric priors, such as mobile device camera poses and monocular depth estimation, and utilizes the planar structures often found in indoor environments. We present a new initialization method called plane scaffold assembly to generate consistent 3D points on these structures, followed by a stable pruning strategy to enhance geometry and optimization stability. Additionally, we introduce geometric and photometric corrections to resolve inconsistencies from motion drift and auto-exposure in mobile devices. Tested on collected real and synthetic indoor scenes, LighthouseGS delivers photorealistic rendering, surpassing state-of-the-art methods and demonstrating the potential for panoramic view synthesis and object placement.
MeTTA: Single-View to 3D Textured Mesh Reconstruction with Test-Time Adaptation
Aug 21, 2024
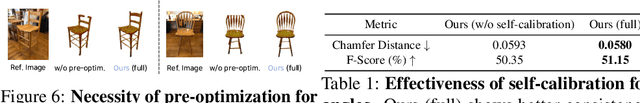

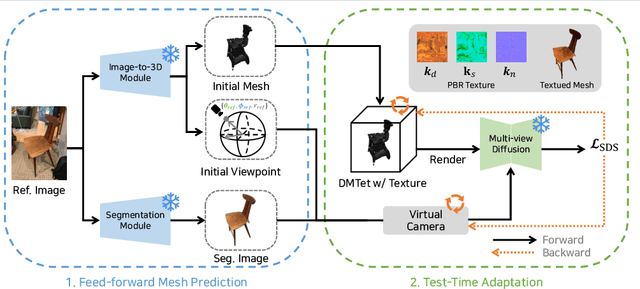
Reconstructing 3D from a single view image is a long-standing challenge. One of the popular approaches to tackle this problem is learning-based methods, but dealing with the test cases unfamiliar with training data (Out-of-distribution; OoD) introduces an additional challenge. To adapt for unseen samples in test time, we propose MeTTA, a test-time adaptation (TTA) exploiting generative prior. We design joint optimization of 3D geometry, appearance, and pose to handle OoD cases with only a single view image. However, the alignment between the reference image and the 3D shape via the estimated viewpoint could be erroneous, which leads to ambiguity. To address this ambiguity, we carefully design learnable virtual cameras and their self-calibration. In our experiments, we demonstrate that MeTTA effectively deals with OoD scenarios at failure cases of existing learning-based 3D reconstruction models and enables obtaining a realistic appearance with physically based rendering (PBR) textures.
Multiface: A Dataset for Neural Face Rendering
Jul 22, 2022



Photorealistic avatars of human faces have come a long way in recent years, yet research along this area is limited by a lack of publicly available, high-quality datasets covering both, dense multi-view camera captures, and rich facial expressions of the captured subjects. In this work, we present Multiface, a new multi-view, high-resolution human face dataset collected from 13 identities at Reality Labs Research for neural face rendering. We introduce Mugsy, a large scale multi-camera apparatus to capture high-resolution synchronized videos of a facial performance. The goal of Multiface is to close the gap in accessibility to high quality data in the academic community and to enable research in VR telepresence. Along with the release of the dataset, we conduct ablation studies on the influence of different model architectures toward the model's interpolation capacity of novel viewpoint and expressions. With a conditional VAE model serving as our baseline, we found that adding spatial bias, texture warp field, and residual connections improves performance on novel view synthesis. Our code and data is available at: https://github.com/facebookresearch/multiface
Facial Depth and Normal Estimation using Single Dual-Pixel Camera
Nov 25, 2021
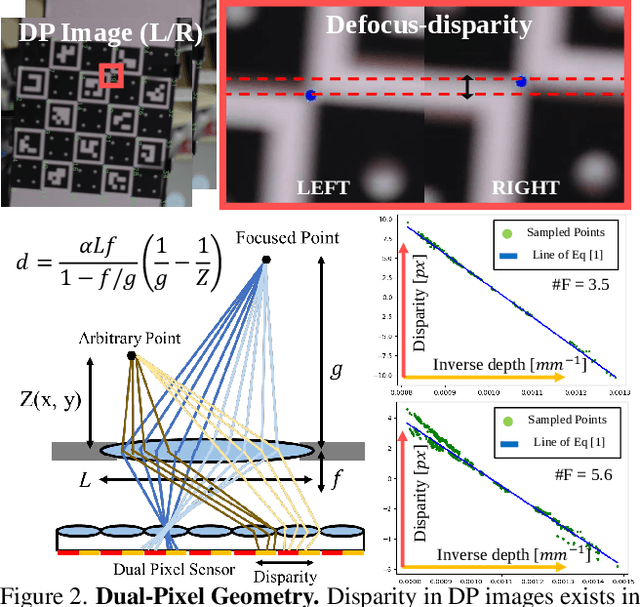

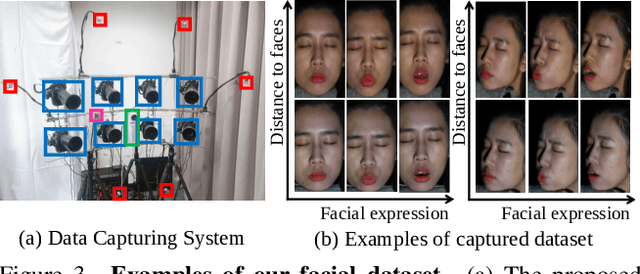
Many mobile manufacturers recently have adopted Dual-Pixel (DP) sensors in their flagship models for faster auto-focus and aesthetic image captures. Despite their advantages, research on their usage for 3D facial understanding has been limited due to the lack of datasets and algorithmic designs that exploit parallax in DP images. This is because the baseline of sub-aperture images is extremely narrow and parallax exists in the defocus blur region. In this paper, we introduce a DP-oriented Depth/Normal network that reconstructs the 3D facial geometry. For this purpose, we collect a DP facial data with more than 135K images for 101 persons captured with our multi-camera structured light systems. It contains the corresponding ground-truth 3D models including depth map and surface normal in metric scale. Our dataset allows the proposed matching network to be generalized for 3D facial depth/normal estimation. The proposed network consists of two novel modules: Adaptive Sampling Module and Adaptive Normal Module, which are specialized in handling the defocus blur in DP images. Finally, the proposed method achieves state-of-the-art performances over recent DP-based depth/normal estimation methods. We also demonstrate the applicability of the estimated depth/normal to face spoofing and relighting.