 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELITE: Efficient Gaussian Head Avatar from a Monocular Video via Learned Initialization and TEst-time Generative Adaptation
Jan 15, 2026We introduce ELITE, an Efficient Gaussian head avatar synthesis from a monocular video via Learned Initialization and TEst-time generative adaptation. Prior works rely either on a 3D data prior or a 2D generative prior to compensate for missing visual cues in monocular videos. However, 3D data prior methods often struggle to generalize in-the-wild, while 2D generative prior methods are computationally heavy and prone to identity hallucination. We identify a complementary synergy between these two priors and design an efficient system that achieves high-fidelity animatable avatar synthesis with strong in-the-wild generalization. Specifically, we introduce a feed-forward Mesh2Gaussian Prior Model (MGPM) that enables fast initialization of a Gaussian avatar. To further bridge the domain gap at test time, we design a test-time generative adaptation stage, leveraging both real and synthetic images as supervision. Unlike previous full diffusion denoising strategies that are slow and hallucination-prone, we propose a rendering-guided single-step diffusion enhancer that restores missing visual details, grounded on Gaussian avatar renderings. Our experiments demonstrate that ELITE produces visually superior avatars to prior works, even for challenging expressions, while achieving 60x faster synthesis than the 2D generative prior method.
FPGS: Feed-Forward Semantic-aware Photorealistic Style Transfer of Large-Scale Gaussian Splatting
Mar 11, 2025



We present FPGS, a feed-forward photorealistic style transfer method of large-scale radiance fields represented by Gaussian Splatting. FPGS, stylizes large-scale 3D scenes with arbitrary, multiple style reference images without additional optimization while preserving multi-view consistency and real-time rendering speed of 3D Gaussians. Prior arts required tedious per-style optimization or time-consuming per-scene training stage and were limited to small-scale 3D scenes. FPGS efficiently stylizes large-scale 3D scenes by introducing a style-decomposed 3D feature field, which inherits AdaIN's feed-forward stylization machinery, supporting arbitrary style reference images. Furthermore, FPGS supports multi-reference stylization with the semantic correspondence matching and local AdaIN, which adds diverse user control for 3D scene styles. FPGS also preserves multi-view consistency by applying semantic matching and style transfer processes directly onto queried features in 3D space. In experiments, we demonstrate that FPGS achieves favorable photorealistic quality scene stylization for large-scale static and dynamic 3D scenes with diverse reference images. Project page: https://kim-geonu.github.io/FPGS/
MeTTA: Single-View to 3D Textured Mesh Reconstruction with Test-Time Adaptation
Aug 21, 2024
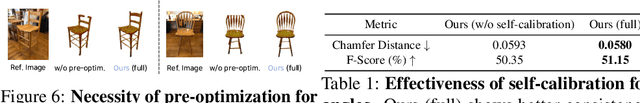

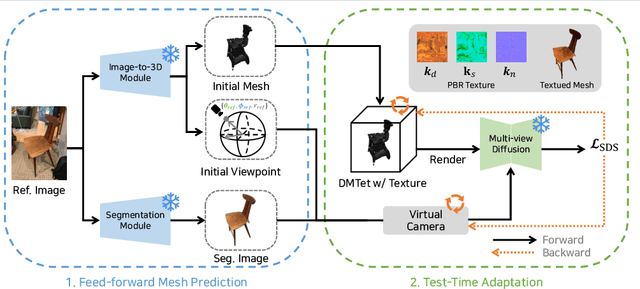
Reconstructing 3D from a single view image is a long-standing challenge. One of the popular approaches to tackle this problem is learning-based methods, but dealing with the test cases unfamiliar with training data (Out-of-distribution; OoD) introduces an additional challenge. To adapt for unseen samples in test time, we propose MeTTA, a test-time adaptation (TTA) exploiting generative prior. We design joint optimization of 3D geometry, appearance, and pose to handle OoD cases with only a single view image. However, the alignment between the reference image and the 3D shape via the estimated viewpoint could be erroneous, which leads to ambiguity. To address this ambiguity, we carefully design learnable virtual cameras and their self-calibration. In our experiments, we demonstrate that MeTTA effectively deals with OoD scenarios at failure cases of existing learning-based 3D reconstruction models and enables obtaining a realistic appearance with physically based rendering (PBR) textures.
Object-Centric Domain Randomization for 3D Shape Reconstruction in the Wild
Mar 21, 2024One of the biggest challenges in single-view 3D shape reconstruction in the wild is the scarcity of <3D shape, 2D image>-paired data from real-world environments. Inspired by remarkable achievements via domain randomization, we propose ObjectDR which synthesizes such paired data via a random simulation of visual variations in object appearances and backgrounds. Our data synthesis framework exploits a conditional generative model (e.g., ControlNet) to generate images conforming to spatial conditions such as 2.5D sketches, which are obtainable through a rendering process of 3D shapes from object collections (e.g., Objaverse-XL). To simulate diverse variations while preserving object silhouettes embedded in spatial conditions, we also introduce a disentangled framework which leverages an initial object guidance. After synthesizing a wide range of data, we pre-train a model on them so that it learns to capture a domain-invariant geometry prior which is consistent across various domains. We validate its effectiveness by substantially improving 3D shape reconstruction models on a real-world benchmark. In a scale-up evaluation, our pre-training achieves 23.6% superior results compared with the pre-training on high-quality computer graphics renderings.
FPRF: Feed-Forward Photorealistic Style Transfer of Large-Scale 3D Neural Radiance Fields
Jan 10, 2024We present FPRF, a feed-forward photorealistic style transfer method for large-scale 3D neural radiance fields. FPRF stylizes large-scale 3D scenes with arbitrary, multiple style reference images without additional optimization while preserving multi-view appearance consistency. Prior arts required tedious per-style/-scene optimization and were limited to small-scale 3D scenes. FPRF efficiently stylizes large-scale 3D scenes by introducing a style-decomposed 3D neural radiance field, which inherits AdaIN's feed-forward stylization machinery, supporting arbitrary style reference images. Furthermore, FPRF supports multi-reference stylization with the semantic correspondence matching and local AdaIN, which adds diverse user control for 3D scene styles. FPRF also preserves multi-view consistency by applying semantic matching and style transfer processes directly onto queried features in 3D space. In experiments, we demonstrate that FPRF achieves favorable photorealistic quality 3D scene stylization for large-scale scenes with diverse reference images. Project page: https://kim-geonu.github.io/FPRF/
Paint-it: Text-to-Texture Synthesis via Deep Convolutional Texture Map Optimization and Physically-Based Rendering
Dec 18, 2023



We present Paint-it, a text-driven high-fidelity texture map synthesis method for 3D meshes via neural re-parameterized texture optimization. Paint-it synthesizes texture maps from a text description by synthesis-through-optimization, exploiting the Score-Distillation Sampling (SDS). We observe that directly applying SDS yields undesirable texture quality due to its noisy gradients. We reveal the importance of texture parameterization when using SDS. Specifically, we propose Deep Convolutional Physically-Based Rendering (DC-PBR) parameterization, which re-parameterizes the physically-based rendering (PBR) texture maps with randomly initialized convolution-based neural kernels, instead of a standard pixel-based parameterization. We show that DC-PBR inherently schedules the optimization curriculum according to texture frequency and naturally filters out the noisy signals from SDS. In experiments, Paint-it obtains remarkable quality PBR texture maps within 15 min., given only a text description. We demonstrate the generalizability and practicality of Paint-it by synthesizing high-quality texture maps for large-scale mesh datasets and showing test-time applications such as relighting and material control using a popular graphics engine. Project page: https://kim-youwang.github.io/paint-it
A Large-Scale 3D Face Mesh Video Dataset via Neural Re-parameterized Optimization
Oct 06, 2023We propose NeuFace, a 3D face mesh pseudo annotation method on videos via neural re-parameterized optimization. Despite the huge progress in 3D face reconstruction methods, generating reliable 3D face labels for in-the-wild dynamic videos remains challenging. Using NeuFace optimization, we annotate the per-view/-frame accurate and consistent face meshes on large-scale face videos, called the NeuFace-dataset. We investigate how neural re-parameterization helps to reconstruct image-aligned facial details on 3D meshes via gradient analysis. By exploiting the naturalness and diversity of 3D faces in our dataset, we demonstrate the usefulness of our dataset for 3D face-related tasks: improving the reconstruction accuracy of an existing 3D face reconstruction model and learning 3D facial motion prior. Code and datasets will be available at https://neuface-dataset.github.io.
Cross-Attention of Disentangled Modalities for 3D Human Mesh Recovery with Transformers
Jul 27, 2022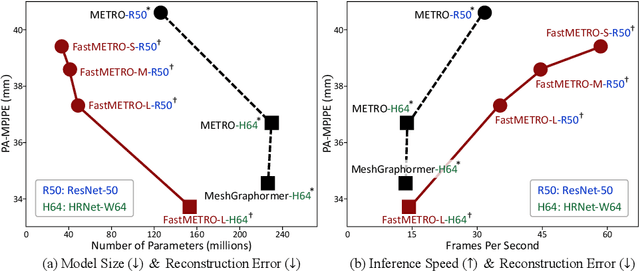

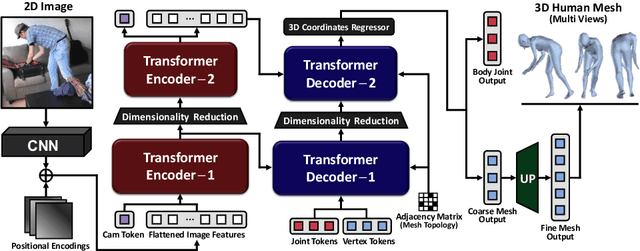
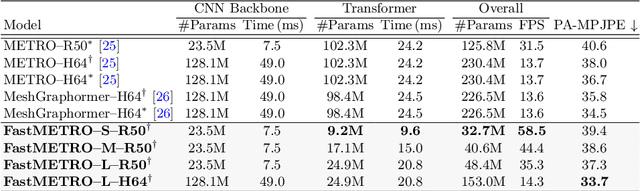
Transformer encoder architectures have recently achieved state-of-the-art results on monocular 3D human mesh reconstruction, but they require a substantial number of parameters and expensive computations. Due to the large memory overhead and slow inference speed, it is difficult to deploy such models for practical use. In this paper, we propose a novel transformer encoder-decoder architecture for 3D human mesh reconstruction from a single image, called FastMETRO. We identify the performance bottleneck in the encoder-based transformers is caused by the token design which introduces high complexity interactions among input tokens. We disentangle the interactions via an encoder-decoder architecture, which allows our model to demand much fewer parameters and shorter inference time. In addition, we impose the prior knowledge of human body's morphological relationship via attention masking and mesh upsampling operations, which leads to faster convergence with higher accuracy. Our FastMETRO improves the Pareto-front of accuracy and efficiency, and clearly outperforms image-based methods on Human3.6M and 3DPW. Furthermore, we validate its generalizability on FreiHAND.
CLIP-Actor: Text-Driven Recommendation and Stylization for Animating Human Meshes
Jun 09, 2022
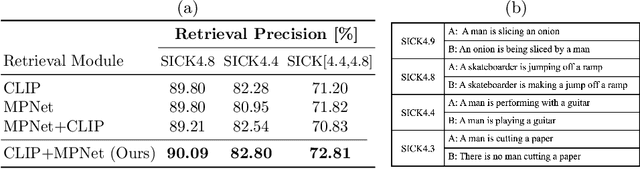
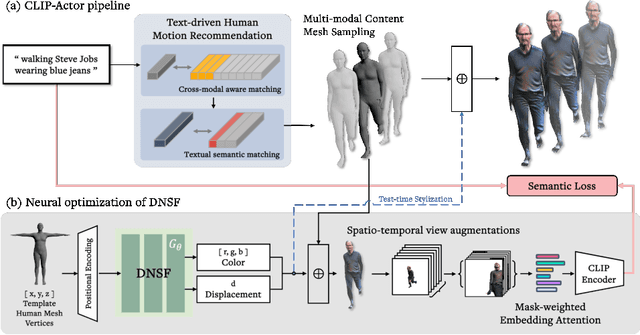
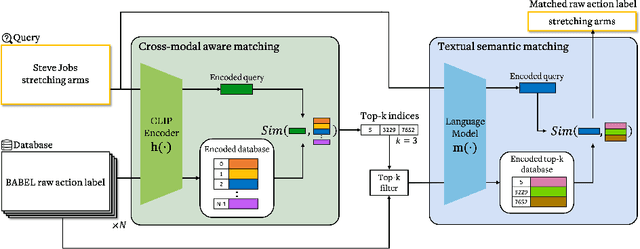
We propose CLIP-Actor, a text-driven motion recommendation and neural mesh stylization system for human mesh animation. CLIP-Actor animates a 3D human mesh to conform to a text prompt by recommending a motion sequence and learning mesh style attributes. Prior work fails to generate plausible results when the artist-designed mesh content does not conform to the text from the beginning. Instead, we build a text-driven human motion recommendation system by leveraging a large-scale human motion dataset with language labels. Given a natural language prompt, CLIP-Actor first suggests a human motion that conforms to the prompt in a coarse-to-fine manner. Then, we propose a synthesize-through-optimization method that detailizes and texturizes a recommended mesh sequence in a disentangled way from the pose of each frame. It allows the style attribute to conform to the prompt in a temporally-consistent and pose-agnostic manner. The decoupled neural optimization also enables spatio-temporal view augmentation from multi-frame human motion. We further propose the mask-weighted embedding attention, which stabilizes the optimization process by rejecting distracting renders containing scarce foreground pixels. We demonstrate that CLIP-Actor produces plausible and human-recognizable style 3D human mesh in motion with detailed geometry and texture from a natural language prompt.
Unified 3D Mesh Recovery of Humans and Animals by Learning Animal Exercise
Nov 03, 2021



We propose an end-to-end unified 3D mesh recovery of humans and quadruped animals trained in a weakly-supervised way. Unlike recent work focusing on a single target class only, we aim to recover 3D mesh of broader classes with a single multi-task model. However, there exists no dataset that can directly enable multi-task learning due to the absence of both human and animal annotations for a single object, e.g., a human image does not have animal pose annotations; thus, we have to devise a new way to exploit heterogeneous datasets. To make the unstable disjoint multi-task learning jointly trainable, we propose to exploit the morphological similarity between humans and animals, motivated by animal exercise where humans imitate animal poses. We realize the morphological similarity by semantic correspondences, called sub-keypoint, which enables joint training of human and animal mesh regression branches. Besides, we propose class-sensitive regularization methods to avoid a mean-shape bias and to improve the distinctiveness across multi-classes. Our method performs favorably against recent uni-modal models on various human and animal datasets while being far more compact.