 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussExplorer: 3D Gaussian Splatting for Embodied Exploration and Reasoning
Jan 19, 2026We present GaussExplorer, a framework for embodied exploration and reasoning built on 3D Gaussian Splatting (3DGS). While prior approaches to language-embedded 3DGS have made meaningful progress in aligning simple text queries with Gaussian embeddings, they are generally optimized for relatively simple queries and struggle to interpret more complex, compositional language queries. Alternative studies based on object-centric RGB-D structured memories provide spatial grounding but are constrained by pre-fixed viewpoints. To address these issues, GaussExplorer introduces Vision-Language Models (VLMs) on top of 3DGS to enable question-driven exploration and reasoning within 3D scenes. We first identify pre-captured images that are most correlated with the query question, and subsequently adjust them into novel viewpoints to more accurately capture visual information for better reasoning by VLMs. Experiments show that ours outperforms existing methods on several benchmarks, demonstrating the effectiveness of integrating VLM-based reasoning with 3DGS for embodied tasks.
Dr. Splat: Directly Referring 3D Gaussian Splatting via Direct Language Embedding Registration
Feb 23, 2025



We introduce Dr. Splat, a novel approach for open-vocabulary 3D scene understanding leveraging 3D Gaussian Splatting. Unlike existing language-embedded 3DGS methods, which rely on a rendering process, our method directly associates language-aligned CLIP embeddings with 3D Gaussians for holistic 3D scene understanding. The key of our method is a language feature registration technique where CLIP embeddings are assigned to the dominant Gaussians intersected by each pixel-ray. Moreover, we integrate Product Quantization (PQ) trained on general large-scale image data to compactly represent embeddings without per-scene optimization. Experiments demonstrate that our approach significantly outperforms existing approaches in 3D perception benchmarks, such as open-vocabulary 3D semantic segmentation, 3D object localization, and 3D object selection tasks. For video results, please visit : https://drsplat.github.io/
MeTTA: Single-View to 3D Textured Mesh Reconstruction with Test-Time Adaptation
Aug 21, 2024
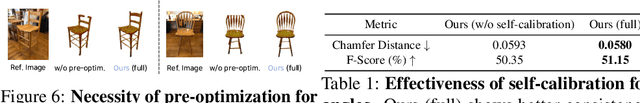

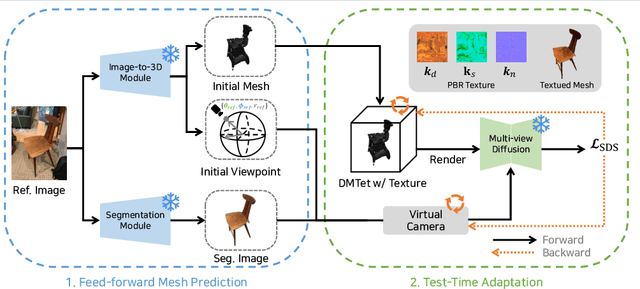
Reconstructing 3D from a single view image is a long-standing challenge. One of the popular approaches to tackle this problem is learning-based methods, but dealing with the test cases unfamiliar with training data (Out-of-distribution; OoD) introduces an additional challenge. To adapt for unseen samples in test time, we propose MeTTA, a test-time adaptation (TTA) exploiting generative prior. We design joint optimization of 3D geometry, appearance, and pose to handle OoD cases with only a single view image. However, the alignment between the reference image and the 3D shape via the estimated viewpoint could be erroneous, which leads to ambiguity. To address this ambiguity, we carefully design learnable virtual cameras and their self-calibration. In our experiments, we demonstrate that MeTTA effectively deals with OoD scenarios at failure cases of existing learning-based 3D reconstruction models and enables obtaining a realistic appearance with physically based rendering (PBR) textures.
Scratching Visual Transformer's Back with Uniform Attention
Oct 16, 2022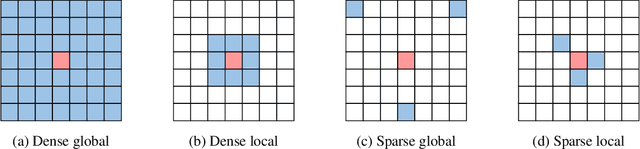

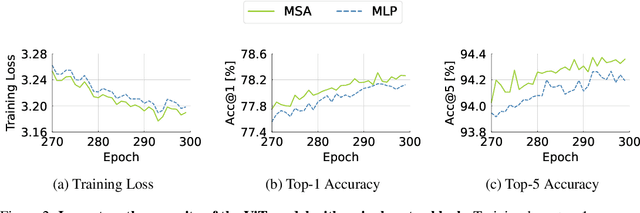
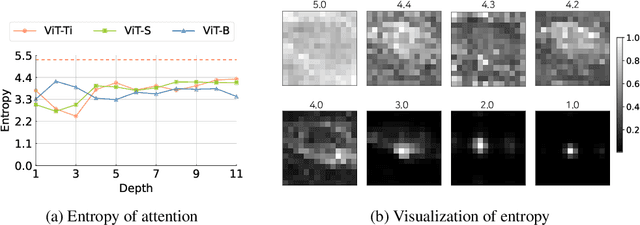
The favorable performance of Vision Transformers (ViTs) is often attributed to the multi-head self-attention (MSA). The MSA enables global interactions at each layer of a ViT model, which is a contrasting feature against Convolutional Neural Networks (CNNs) that gradually increase the range of interaction across multiple layers. We study the role of the density of the attention. Our preliminary analyses suggest that the spatial interactions of attention maps are close to dense interactions rather than sparse ones. This is a curious phenomenon, as dense attention maps are harder for the model to learn due to steeper softmax gradients around them. We interpret this as a strong preference for ViT models to include dense interaction. We thus manually insert the uniform attention to each layer of ViT models to supply the much needed dense interactions. We call this method Context Broadcasting, CB. We observe that the inclusion of CB reduces the degree of density in the original attention maps and increases both the capacity and generalizability of the ViT models. CB incurs negligible costs: 1 line in your model code, no additional parameters, and minimal extra operations.
HDR-Plenoxels: Self-Calibrating High Dynamic Range Radiance Fields
Aug 14, 2022

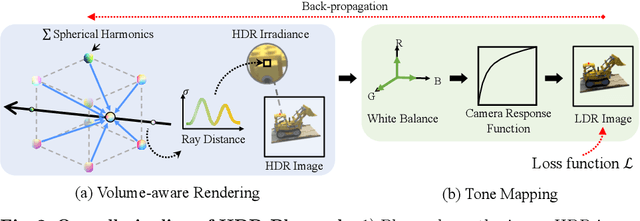
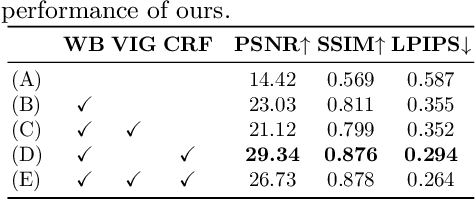
We propose high dynamic range radiance (HDR) fields, HDR-Plenoxels, that learn a plenoptic function of 3D HDR radiance fields, geometry information, and varying camera settings inherent in 2D low dynamic range (LDR) images. Our voxel-based volume rendering pipeline reconstructs HDR radiance fields with only multi-view LDR images taken from varying camera settings in an end-to-end manner and has a fast convergence speed. To deal with various cameras in real-world scenarios, we introduce a tone mapping module that models the digital in-camera imaging pipeline (ISP) and disentangles radiometric settings. Our tone mapping module allows us to render by controlling the radiometric settings of each novel view. Finally, we build a multi-view dataset with varying camera conditions, which fits our problem setting. Our experiments show that HDR-Plenoxels can express detail and high-quality HDR novel views from only LDR images with various cameras.