 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiDAR-Anchored Collaborative Distillation for Robust 2D Representations
Feb 13, 2026As deep learning continues to advance, self-supervised learning has made considerable strides. It allows 2D image encoders to extract useful features for various downstream tasks, including those related to vision-based systems. Nevertheless, pre-trained 2D image encoders fall short in conducting the task under noisy and adverse weather conditions beyond clear daytime scenes, which require for robust visual perception. To address these issues, we propose a novel self-supervised approach, \textbf{Collaborative Distillation}, which leverages 3D LiDAR as self-supervision to improve robustness to noisy and adverse weather conditions in 2D image encoders while retaining their original capabilities. Our method outperforms competing methods in various downstream tasks across diverse conditions and exhibits strong generalization ability. In addition, our method also improves 3D awareness stemming from LiDAR's characteristics. This advancement highlights our method's practicality and adaptability in real-world scenarios.
DarkEQA: Benchmarking Vision-Language Models for Embodied Question Answering in Low-Light Indoor Environments
Dec 31, 2025Vision Language Models (VLMs) are increasingly adopted as central reasoning modules for embodied agents. Existing benchmarks evaluate their capabilities under ideal, well-lit conditions, yet robust 24/7 operation demands performance under a wide range of visual degradations, including low-light conditions at night or in dark environments--a core necessity that has been largely overlooked. To address this underexplored challenge, we present DarkEQA, an open-source benchmark for evaluating EQA-relevant perceptual primitives under multi-level low-light conditions. DarkEQA isolates the perception bottleneck by evaluating question answering from egocentric observations under controlled degradations, enabling attributable robustness analysis. A key design feature of DarkEQA is its physical fidelity: visual degradations are modeled in linear RAW space, simulating physics-based illumination drop and sensor noise followed by an ISP-inspired rendering pipeline. We demonstrate the utility of DarkEQA by evaluating a wide range of state-of-the-art VLMs and Low-Light Image Enhancement (LLIE) models. Our analysis systematically reveals VLMs' limitations when operating under these challenging visual conditions. Our code and benchmark dataset will be released upon acceptance.
Sound2Vision: Generating Diverse Visuals from Audio through Cross-Modal Latent Alignment
Dec 09, 2024



How does audio describe the world around us? In this work, we propose a method for generating images of visual scenes from diverse in-the-wild sounds. This cross-modal generation task is challenging due to the significant information gap between auditory and visual signals. We address this challenge by designing a model that aligns audio-visual modalities by enriching audio features with visual information and translating them into the visual latent space. These features are then fed into the pre-trained image generator to produce images. To enhance image quality, we use sound source localization to select audio-visual pairs with strong cross-modal correlations. Our method achieves substantially better results on the VEGAS and VGGSound datasets compared to previous work and demonstrates control over the generation process through simple manipulations to the input waveform or latent space. Furthermore, we analyze the geometric properties of the learned embedding space and demonstrate that our learning approach effectively aligns audio-visual signals for cross-modal generation. Based on this analysis, we show that our method is agnostic to specific design choices, showing its generalizability by integrating various model architectures and different types of audio-visual data.
MeTTA: Single-View to 3D Textured Mesh Reconstruction with Test-Time Adaptation
Aug 21, 2024
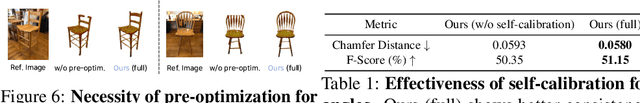

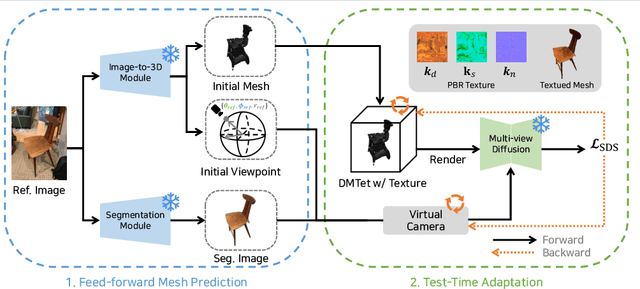
Reconstructing 3D from a single view image is a long-standing challenge. One of the popular approaches to tackle this problem is learning-based methods, but dealing with the test cases unfamiliar with training data (Out-of-distribution; OoD) introduces an additional challenge. To adapt for unseen samples in test time, we propose MeTTA, a test-time adaptation (TTA) exploiting generative prior. We design joint optimization of 3D geometry, appearance, and pose to handle OoD cases with only a single view image. However, the alignment between the reference image and the 3D shape via the estimated viewpoint could be erroneous, which leads to ambiguity. To address this ambiguity, we carefully design learnable virtual cameras and their self-calibration. In our experiments, we demonstrate that MeTTA effectively deals with OoD scenarios at failure cases of existing learning-based 3D reconstruction models and enables obtaining a realistic appearance with physically based rendering (PBR) textures.
Revisiting Learning-based Video Motion Magnification for Real-time Processing
Mar 04, 2024



Video motion magnification is a technique to capture and amplify subtle motion in a video that is invisible to the naked eye. The deep learning-based prior work successfully demonstrates the modelling of the motion magnification problem with outstanding quality compared to conventional signal processing-based ones. However, it still lags behind real-time performance, which prevents it from being extended to various online applications. In this paper, we investigate an efficient deep learning-based motion magnification model that runs in real time for full-HD resolution videos. Due to the specified network design of the prior art, i.e. inhomogeneous architecture, the direct application of existing neural architecture search methods is complicated. Instead of automatic search, we carefully investigate the architecture module by module for its role and importance in the motion magnification task. Two key findings are 1) Reducing the spatial resolution of the latent motion representation in the decoder provides a good trade-off between computational efficiency and task quality, and 2) surprisingly, only a single linear layer and a single branch in the encoder are sufficient for the motion magnification task. Based on these findings, we introduce a real-time deep learning-based motion magnification model with4.2X fewer FLOPs and is 2.7X faster than the prior art while maintaining comparable quality.
Sound to Visual Scene Generation by Audio-to-Visual Latent Alignment
Mar 30, 2023
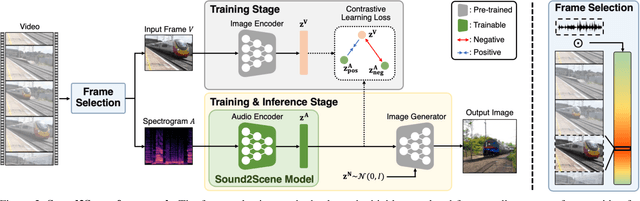


How does audio describe the world around us? In this paper, we propose a method for generating an image of a scene from sound. Our method addresses the challenges of dealing with the large gaps that often exist between sight and sound. We design a model that works by scheduling the learning procedure of each model component to associate audio-visual modalities despite their information gaps. The key idea is to enrich the audio features with visual information by learning to align audio to visual latent space. We translate the input audio to visual features, then use a pre-trained generator to produce an image. To further improve the quality of our generated images, we use sound source localization to select the audio-visual pairs that have strong cross-modal correlations. We obtain substantially better results on the VEGAS and VGGSound datasets than prior approaches. We also show that we can control our model's predictions by applying simple manipulations to the input waveform, or to the latent space.