 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAVAS: Physics-Aware Video-to-Audio Synthesis
Dec 09, 2025



Recent advances in Video-to-Audio (V2A) generation have achieved impressive perceptual quality and temporal synchronization, yet most models remain appearance-driven, capturing visual-acoustic correlations without considering the physical factors that shape real-world sounds. We present Physics-Aware Video-to-Audio Synthesis (PAVAS), a method that incorporates physical reasoning into a latent diffusion-based V2A generation through the Physics-Driven Audio Adapter (Phy-Adapter). The adapter receives object-level physical parameters estimated by the Physical Parameter Estimator (PPE), which uses a Vision-Language Model (VLM) to infer the moving-object mass and a segmentation-based dynamic 3D reconstruction module to recover its motion trajectory for velocity computation. These physical cues enable the model to synthesize sounds that reflect underlying physical factors. To assess physical realism, we curate VGG-Impact, a benchmark focusing on object-object interactions, and introduce Audio-Physics Correlation Coefficient (APCC), an evaluation metric that measures consistency between physical and auditory attributes. Comprehensive experiments show that PAVAS produces physically plausible and perceptually coherent audio, outperforming existing V2A models in both quantitative and qualitative evaluations. Visit https://physics-aware-video-to-audio-synthesis.github.io for demo videos.
Perceptually Accurate 3D Talking Head Generation: New Definitions, Speech-Mesh Representation, and Evaluation Metrics
Mar 27, 2025



Recent advancements in speech-driven 3D talking head generation have made significant progress in lip synchronization. However, existing models still struggle to capture the perceptual alignment between varying speech characteristics and corresponding lip movements. In this work, we claim that three criteria -- Temporal Synchronization, Lip Readability, and Expressiveness -- are crucial for achieving perceptually accurate lip movements. Motivated by our hypothesis that a desirable representation space exists to meet these three criteria, we introduce a speech-mesh synchronized representation that captures intricate correspondences between speech signals and 3D face meshes. We found that our learned representation exhibits desirable characteristics, and we plug it into existing models as a perceptual loss to better align lip movements to the given speech. In addition, we utilize this representation as a perceptual metric and introduce two other physically grounded lip synchronization metrics to assess how well the generated 3D talking heads align with these three criteria. Experiments show that training 3D talking head generation models with our perceptual loss significantly improve all three aspects of perceptually accurate lip synchronization. Codes and datasets are available at https://perceptual-3d-talking-head.github.io/.
AVHBench: A Cross-Modal Hallucination Benchmark for Audio-Visual Large Language Models
Oct 23, 2024
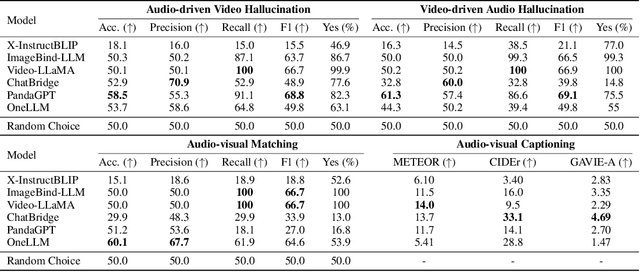

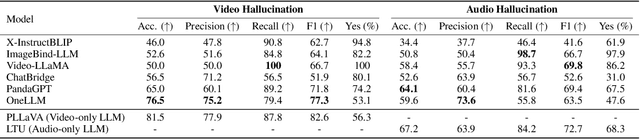
Following the success of Large Language Models (LLMs), expanding their boundaries to new modalities represents a significant paradigm shift in multimodal understanding. Human perception is inherently multimodal, relying not only on text but also on auditory and visual cues for a complete understanding of the world. In recognition of this fact, audio-visual LLMs have recently emerged. Despite promising developments, the lack of dedicated benchmarks poses challenges for understanding and evaluating models. In this work, we show that audio-visual LLMs struggle to discern subtle relationships between audio and visual signals, leading to hallucinations, underscoring the need for reliable benchmarks. To address this, we introduce AVHBench, the first comprehensive benchmark specifically designed to evaluate the perception and comprehension capabilities of audio-visual LLMs. Our benchmark includes tests for assessing hallucinations, as well as the cross-modal matching and reasoning abilities of these models. Our results reveal that most existing audio-visual LLMs struggle with hallucinations caused by cross-interactions between modalities, due to their limited capacity to perceive complex multimodal signals and their relationships. Additionally, we demonstrate that simple training with our AVHBench improves robustness of audio-visual LLMs against hallucinations.
Enhancing Speech-Driven 3D Facial Animation with Audio-Visual Guidance from Lip Reading Expert
Jul 01, 2024

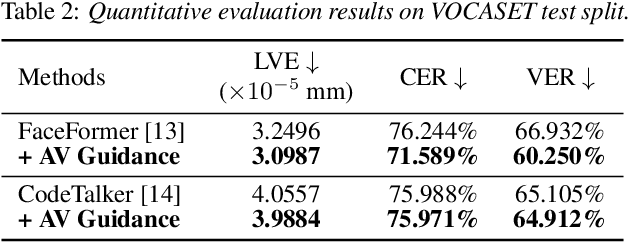

Speech-driven 3D facial animation has recently garnered attention due to its cost-effective usability in multimedia production. However, most current advances overlook the intelligibility of lip movements, limiting the realism of facial expressions. In this paper, we introduce a method for speech-driven 3D facial animation to generate accurate lip movements, proposing an audio-visual multimodal perceptual loss. This loss provides guidance to train the speech-driven 3D facial animators to generate plausible lip motions aligned with the spoken transcripts. Furthermore, to incorporate the proposed audio-visual perceptual loss, we devise an audio-visual lip reading expert leveraging its prior knowledge about correlations between speech and lip motions. We validate the effectiveness of our approach through broad experiments, showing noticeable improvements in lip synchronization and lip readability performance. Codes are available at https://3d-talking-head-avguide.github.io/.
MultiTalk: Enhancing 3D Talking Head Generation Across Languages with Multilingual Video Dataset
Jun 20, 2024

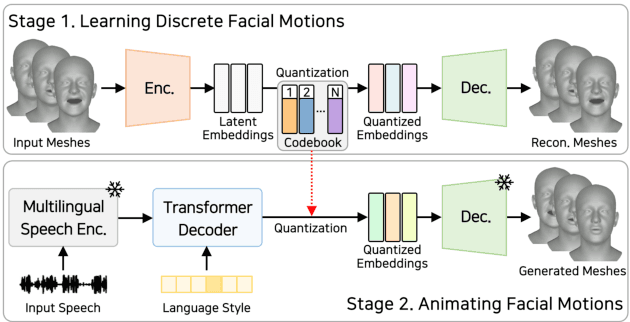

Recent studies in speech-driven 3D talking head generation have achieved convincing results in verbal articulations. However, generating accurate lip-syncs degrades when applied to input speech in other languages, possibly due to the lack of datasets covering a broad spectrum of facial movements across languages. In this work, we introduce a novel task to generate 3D talking heads from speeches of diverse languages. We collect a new multilingual 2D video dataset comprising over 420 hours of talking videos in 20 languages. With our proposed dataset, we present a multilingually enhanced model that incorporates language-specific style embeddings, enabling it to capture the unique mouth movements associated with each language. Additionally, we present a metric for assessing lip-sync accuracy in multilingual settings. We demonstrate that training a 3D talking head model with our proposed dataset significantly enhances its multilingual performance. Codes and datasets are available at https://multi-talk.github.io/.
Revisiting Learning-based Video Motion Magnification for Real-time Processing
Mar 04, 2024



Video motion magnification is a technique to capture and amplify subtle motion in a video that is invisible to the naked eye. The deep learning-based prior work successfully demonstrates the modelling of the motion magnification problem with outstanding quality compared to conventional signal processing-based ones. However, it still lags behind real-time performance, which prevents it from being extended to various online applications. In this paper, we investigate an efficient deep learning-based motion magnification model that runs in real time for full-HD resolution videos. Due to the specified network design of the prior art, i.e. inhomogeneous architecture, the direct application of existing neural architecture search methods is complicated. Instead of automatic search, we carefully investigate the architecture module by module for its role and importance in the motion magnification task. Two key findings are 1) Reducing the spatial resolution of the latent motion representation in the decoder provides a good trade-off between computational efficiency and task quality, and 2) surprisingly, only a single linear layer and a single branch in the encoder are sufficient for the motion magnification task. Based on these findings, we introduce a real-time deep learning-based motion magnification model with4.2X fewer FLOPs and is 2.7X faster than the prior art while maintaining comparable quality.
Learning-based Axial Motion Magnification
Dec 15, 2023Video motion magnification amplifies invisible small motions to be perceptible, which provides humans with spatially dense and holistic understanding about small motions from the scene of interest. This is based on the premise that magnifying small motions enhances the legibility of the motion. In the real world, however, vibrating objects often possess complex systems, having complex natural frequencies, modes, and directions. Existing motion magnification often fails to improve the legibility since the intricate motions still retain complex characteristics even when magnified, which distracts us from analyzing them. In this work, we focus on improving the legibility by proposing a new concept, axial motion magnification, which magnifies decomposed motions along the user-specified direction. Axial motion magnification can be applied to various applications where motions of specific axes are critical, by providing simplified and easily readable motion information. We propose a novel learning-based axial motion magnification method with the Motion Separation Module that enables to disentangle and magnify the motion representation along axes of interest. Further, we build a new synthetic training dataset for the axial motion magnification task. Our proposed method improves the legibility of resulting motions along certain axes, while adding additional user controllability. Our method can be directly adopted to the generic motion magnification and achieves favorable performance against competing methods. Our project page is available at https://axial-momag.github.io/axial-momag/.