 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceptually Accurate 3D Talking Head Generation: New Definitions, Speech-Mesh Representation, and Evaluation Metrics
Mar 27, 2025



Recent advancements in speech-driven 3D talking head generation have made significant progress in lip synchronization. However, existing models still struggle to capture the perceptual alignment between varying speech characteristics and corresponding lip movements. In this work, we claim that three criteria -- Temporal Synchronization, Lip Readability, and Expressiveness -- are crucial for achieving perceptually accurate lip movements. Motivated by our hypothesis that a desirable representation space exists to meet these three criteria, we introduce a speech-mesh synchronized representation that captures intricate correspondences between speech signals and 3D face meshes. We found that our learned representation exhibits desirable characteristics, and we plug it into existing models as a perceptual loss to better align lip movements to the given speech. In addition, we utilize this representation as a perceptual metric and introduce two other physically grounded lip synchronization metrics to assess how well the generated 3D talking heads align with these three criteria. Experiments show that training 3D talking head generation models with our perceptual loss significantly improve all three aspects of perceptually accurate lip synchronization. Codes and datasets are available at https://perceptual-3d-talking-head.github.io/.
Enhancing Speech-Driven 3D Facial Animation with Audio-Visual Guidance from Lip Reading Expert
Jul 01, 2024

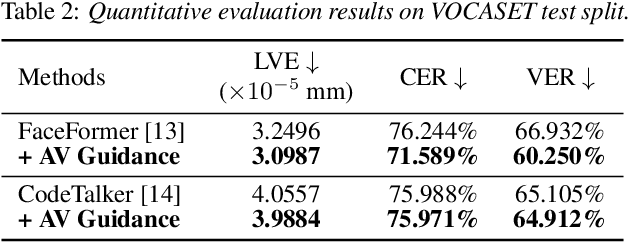

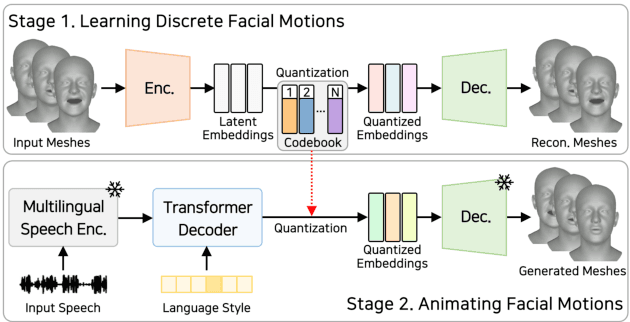
Speech-driven 3D facial animation has recently garnered attention due to its cost-effective usability in multimedia production. However, most current advances overlook the intelligibility of lip movements, limiting the realism of facial expressions. In this paper, we introduce a method for speech-driven 3D facial animation to generate accurate lip movements, proposing an audio-visual multimodal perceptual loss. This loss provides guidance to train the speech-driven 3D facial animators to generate plausible lip motions aligned with the spoken transcripts. Furthermore, to incorporate the proposed audio-visual perceptual loss, we devise an audio-visual lip reading expert leveraging its prior knowledge about correlations between speech and lip motions. We validate the effectiveness of our approach through broad experiments, showing noticeable improvements in lip synchronization and lip readability performance. Codes are available at https://3d-talking-head-avguide.github.io/.
MultiTalk: Enhancing 3D Talking Head Generation Across Languages with Multilingual Video Dataset
Jun 20, 2024


Recent studies in speech-driven 3D talking head generation have achieved convincing results in verbal articulations. However, generating accurate lip-syncs degrades when applied to input speech in other languages, possibly due to the lack of datasets covering a broad spectrum of facial movements across languages. In this work, we introduce a novel task to generate 3D talking heads from speeches of diverse languages. We collect a new multilingual 2D video dataset comprising over 420 hours of talking videos in 20 languages. With our proposed dataset, we present a multilingually enhanced model that incorporates language-specific style embeddings, enabling it to capture the unique mouth movements associated with each language. Additionally, we present a metric for assessing lip-sync accuracy in multilingual settings. We demonstrate that training a 3D talking head model with our proposed dataset significantly enhances its multilingual performance. Codes and datasets are available at https://multi-talk.github.io/.
LaughTalk: Expressive 3D Talking Head Generation with Laughter
Nov 02, 2023



Laughter is a unique expression, essential to affirmative social interactions of humans. Although current 3D talking head generation methods produce convincing verbal articulations, they often fail to capture the vitality and subtleties of laughter and smiles despite their importance in social context. In this paper, we introduce a novel task to generate 3D talking heads capable of both articulate speech and authentic laughter. Our newly curated dataset comprises 2D laughing videos paired with pseudo-annotated and human-validated 3D FLAME parameters and vertices. Given our proposed dataset, we present a strong baseline with a two-stage training scheme: the model first learns to talk and then acquires the ability to express laughter. Extensive experiments demonstrate that our method performs favorably compared to existing approaches in both talking head generation and expressing laughter signals. We further explore potential applications on top of our proposed method for rigging realistic avatars.
A Large-Scale 3D Face Mesh Video Dataset via Neural Re-parameterized Optimization
Oct 06, 2023We propose NeuFace, a 3D face mesh pseudo annotation method on videos via neural re-parameterized optimization. Despite the huge progress in 3D face reconstruction methods, generating reliable 3D face labels for in-the-wild dynamic videos remains challenging. Using NeuFace optimization, we annotate the per-view/-frame accurate and consistent face meshes on large-scale face videos, called the NeuFace-dataset. We investigate how neural re-parameterization helps to reconstruct image-aligned facial details on 3D meshes via gradient analysis. By exploiting the naturalness and diversity of 3D faces in our dataset, we demonstrate the usefulness of our dataset for 3D face-related tasks: improving the reconstruction accuracy of an existing 3D face reconstruction model and learning 3D facial motion prior. Code and datasets will be available at https://neuface-dataset.github.io.