 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussExplorer: 3D Gaussian Splatting for Embodied Exploration and Reasoning
Jan 19, 2026We present GaussExplorer, a framework for embodied exploration and reasoning built on 3D Gaussian Splatting (3DGS). While prior approaches to language-embedded 3DGS have made meaningful progress in aligning simple text queries with Gaussian embeddings, they are generally optimized for relatively simple queries and struggle to interpret more complex, compositional language queries. Alternative studies based on object-centric RGB-D structured memories provide spatial grounding but are constrained by pre-fixed viewpoints. To address these issues, GaussExplorer introduces Vision-Language Models (VLMs) on top of 3DGS to enable question-driven exploration and reasoning within 3D scenes. We first identify pre-captured images that are most correlated with the query question, and subsequently adjust them into novel viewpoints to more accurately capture visual information for better reasoning by VLMs. Experiments show that ours outperforms existing methods on several benchmarks, demonstrating the effectiveness of integrating VLM-based reasoning with 3DGS for embodied tasks.
ELITE: Efficient Gaussian Head Avatar from a Monocular Video via Learned Initialization and TEst-time Generative Adaptation
Jan 15, 2026We introduce ELITE, an Efficient Gaussian head avatar synthesis from a monocular video via Learned Initialization and TEst-time generative adaptation. Prior works rely either on a 3D data prior or a 2D generative prior to compensate for missing visual cues in monocular videos. However, 3D data prior methods often struggle to generalize in-the-wild, while 2D generative prior methods are computationally heavy and prone to identity hallucination. We identify a complementary synergy between these two priors and design an efficient system that achieves high-fidelity animatable avatar synthesis with strong in-the-wild generalization. Specifically, we introduce a feed-forward Mesh2Gaussian Prior Model (MGPM) that enables fast initialization of a Gaussian avatar. To further bridge the domain gap at test time, we design a test-time generative adaptation stage, leveraging both real and synthetic images as supervision. Unlike previous full diffusion denoising strategies that are slow and hallucination-prone, we propose a rendering-guided single-step diffusion enhancer that restores missing visual details, grounded on Gaussian avatar renderings. Our experiments demonstrate that ELITE produces visually superior avatars to prior works, even for challenging expressions, while achieving 60x faster synthesis than the 2D generative prior method.
Measurement-Consistent Langevin Corrector: A Remedy for Latent Diffusion Inverse Solvers
Jan 08, 2026With recent advances in generative models, diffusion models have emerged as powerful priors for solving inverse problems in each domain. Since Latent Diffusion Models (LDMs) provide generic priors, several studies have explored their potential as domain-agnostic zero-shot inverse solvers. Despite these efforts, existing latent diffusion inverse solvers suffer from their instability, exhibiting undesirable artifacts and degraded quality. In this work, we first identify the instability as a discrepancy between the solver's and true reverse diffusion dynamics, and show that reducing this gap stabilizes the solver. Building on this, we introduce Measurement-Consistent Langevin Corrector (MCLC), a theoretically grounded plug-and-play correction module that remedies the LDM-based inverse solvers through measurement-consistent Langevin updates. Compared to prior approaches that rely on linear manifold assumptions, which often do not hold in latent space, MCLC operates without this assumption, leading to more stable and reliable behavior. We experimentally demonstrate the effectiveness of MCLC and its compatibility with existing solvers across diverse image restoration tasks. Additionally, we analyze blob artifacts and offer insights into their underlying causes. We highlight that MCLC is a key step toward more robust zero-shot inverse problem solvers.
SA-ResGS: Self-Augmented Residual 3D Gaussian Splatting for Next Best View Selection
Jan 06, 2026We propose Self-Augmented Residual 3D Gaussian Splatting (SA-ResGS), a novel framework to stabilize uncertainty quantification and enhancing uncertainty-aware supervision in next-best-view (NBV) selection for active scene reconstruction. SA-ResGS improves both the reliability of uncertainty estimates and their effectiveness for supervision by generating Self-Augmented point clouds (SA-Points) via triangulation between a training view and a rasterized extrapolated view, enabling efficient scene coverage estimation. While improving scene coverage through physically guided view selection, SA-ResGS also addresses the challenge of under-supervised Gaussians, exacerbated by sparse and wide-baseline views, by introducing the first residual learning strategy tailored for 3D Gaussian Splatting. This targeted supervision enhances gradient flow in high-uncertainty Gaussians by combining uncertainty-driven filtering with dropout- and hard-negative-mining-inspired sampling. Our contributions are threefold: (1) a physically grounded view selection strategy that promotes efficient and uniform scene coverage; (2) an uncertainty-aware residual supervision scheme that amplifies learning signals for weakly contributing Gaussians, improving training stability and uncertainty estimation across scenes with diverse camera distributions; (3) an implicit unbiasing of uncertainty quantification as a consequence of constrained view selection and residual supervision, which together mitigate conflicting effects of wide-baseline exploration and sparse-view ambiguity in NBV planning. Experiments on active view selection demonstrate that SA-ResGS outperforms state-of-the-art baselines in both reconstruction quality and view selection robustness.
DarkEQA: Benchmarking Vision-Language Models for Embodied Question Answering in Low-Light Indoor Environments
Dec 31, 2025Vision Language Models (VLMs) are increasingly adopted as central reasoning modules for embodied agents. Existing benchmarks evaluate their capabilities under ideal, well-lit conditions, yet robust 24/7 operation demands performance under a wide range of visual degradations, including low-light conditions at night or in dark environments--a core necessity that has been largely overlooked. To address this underexplored challenge, we present DarkEQA, an open-source benchmark for evaluating EQA-relevant perceptual primitives under multi-level low-light conditions. DarkEQA isolates the perception bottleneck by evaluating question answering from egocentric observations under controlled degradations, enabling attributable robustness analysis. A key design feature of DarkEQA is its physical fidelity: visual degradations are modeled in linear RAW space, simulating physics-based illumination drop and sensor noise followed by an ISP-inspired rendering pipeline. We demonstrate the utility of DarkEQA by evaluating a wide range of state-of-the-art VLMs and Low-Light Image Enhancement (LLIE) models. Our analysis systematically reveals VLMs' limitations when operating under these challenging visual conditions. Our code and benchmark dataset will be released upon acceptance.
FacEDiT: Unified Talking Face Editing and Generation via Facial Motion Infilling
Dec 16, 2025
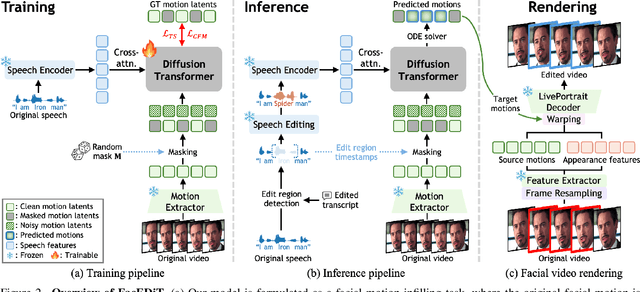


Talking face editing and face generation have often been studied as distinct problems. In this work, we propose viewing both not as separate tasks but as subtasks of a unifying formulation, speech-conditional facial motion infilling. We explore facial motion infilling as a self-supervised pretext task that also serves as a unifying formulation of dynamic talking face synthesis. To instantiate this idea, we propose FacEDiT, a speech-conditional Diffusion Transformer trained with flow matching. Inspired by masked autoencoders, FacEDiT learns to synthesize masked facial motions conditioned on surrounding motions and speech. This formulation enables both localized generation and edits, such as substitution, insertion, and deletion, while ensuring seamless transitions with unedited regions. In addition, biased attention and temporal smoothness constraints enhance boundary continuity and lip synchronization. To address the lack of a standard editing benchmark, we introduce FacEDiTBench, the first dataset for talking face editing, featuring diverse edit types and lengths, along with new evaluation metrics. Extensive experiments validate that talking face editing and generation emerge as subtasks of speech-conditional motion infilling; FacEDiT produces accurate, speech-aligned facial edits with strong identity preservation and smooth visual continuity while generalizing effectively to talking face generation.
Patch-wise Retrieval: A Bag of Practical Techniques for Instance-level Matching
Dec 14, 2025Instance-level image retrieval aims to find images containing the same object as a given query, despite variations in size, position, or appearance. To address this challenging task, we propose Patchify, a simple yet effective patch-wise retrieval framework that offers high performance, scalability, and interpretability without requiring fine-tuning. Patchify divides each database image into a small number of structured patches and performs retrieval by comparing these local features with a global query descriptor, enabling accurate and spatially grounded matching. To assess not just retrieval accuracy but also spatial correctness, we introduce LocScore, a localization-aware metric that quantifies whether the retrieved region aligns with the target object. This makes LocScore a valuable diagnostic tool for understanding and improving retrieval behavior. We conduct extensive experiments across multiple benchmarks, backbones, and region selection strategies, showing that Patchify outperforms global methods and complements state-of-the-art reranking pipelines. Furthermore, we apply Product Quantization for efficient large-scale retrieval and highlight the importance of using informative features during compression, which significantly boosts performance. Project website: https://wons20k.github.io/PatchwiseRetrieval/
PAVAS: Physics-Aware Video-to-Audio Synthesis
Dec 09, 2025



Recent advances in Video-to-Audio (V2A) generation have achieved impressive perceptual quality and temporal synchronization, yet most models remain appearance-driven, capturing visual-acoustic correlations without considering the physical factors that shape real-world sounds. We present Physics-Aware Video-to-Audio Synthesis (PAVAS), a method that incorporates physical reasoning into a latent diffusion-based V2A generation through the Physics-Driven Audio Adapter (Phy-Adapter). The adapter receives object-level physical parameters estimated by the Physical Parameter Estimator (PPE), which uses a Vision-Language Model (VLM) to infer the moving-object mass and a segmentation-based dynamic 3D reconstruction module to recover its motion trajectory for velocity computation. These physical cues enable the model to synthesize sounds that reflect underlying physical factors. To assess physical realism, we curate VGG-Impact, a benchmark focusing on object-object interactions, and introduce Audio-Physics Correlation Coefficient (APCC), an evaluation metric that measures consistency between physical and auditory attributes. Comprehensive experiments show that PAVAS produces physically plausible and perceptually coherent audio, outperforming existing V2A models in both quantitative and qualitative evaluations. Visit https://physics-aware-video-to-audio-synthesis.github.io for demo videos.
RetouchLLM: Training-free White-box Image Retouching
Oct 09, 2025Image retouching not only enhances visual quality but also serves as a means of expressing personal preferences and emotions. However, existing learning-based approaches require large-scale paired data and operate as black boxes, making the retouching process opaque and limiting their adaptability to handle diverse, user- or image-specific adjustments. In this work, we propose RetouchLLM, a training-free white-box image retouching system, which requires no training data and performs interpretable, code-based retouching directly on high-resolution images. Our framework progressively enhances the image in a manner similar to how humans perform multi-step retouching, allowing exploration of diverse adjustment paths. It comprises of two main modules: a visual critic that identifies differences between the input and reference images, and a code generator that produces executable codes. Experiments demonstrate that our approach generalizes well across diverse retouching styles, while natural language-based user interaction enables interpretable and controllable adjustments tailored to user intent.
VSC: Visual Search Compositional Text-to-Image Diffusion Model
May 02, 2025Text-to-image diffusion models have shown impressive capabilities in generating realistic visuals from natural-language prompts, yet they often struggle with accurately binding attributes to corresponding objects, especially in prompts containing multiple attribute-object pairs. This challenge primarily arises from the limitations of commonly used text encoders, such as CLIP, which can fail to encode complex linguistic relationships and modifiers effectively. Existing approaches have attempted to mitigate these issues through attention map control during inference and the use of layout information or fine-tuning during training, yet they face performance drops with increased prompt complexity. In this work, we introduce a novel compositional generation method that leverages pairwise image embeddings to improve attribute-object binding. Our approach decomposes complex prompts into sub-prompts, generates corresponding images, and computes visual prototypes that fuse with text embeddings to enhance representation. By applying segmentation-based localization training, we address cross-attention misalignment, achieving improved accuracy in binding multiple attributes to objects. Our approaches outperform existing compositional text-to-image diffusion models on the benchmark T2I CompBench, achieving better image quality, evaluated by humans, and emerging robustness under scaling number of binding pairs in the prompt.